Your Agent Works in the Demo. Four New Papers Explain Why It Fails in Production.
Four arXiv papers published May 11, 2026 converge on one finding: the best frontier model scores 62.2% on real-world agent tasks — and the failures trace back to four specific, fixable architectural gaps.
Research Brief
Four arXiv papers landed on May 11, 2026 with an uncomfortable finding for anyone shipping agentic features: the best frontier model on a real-world agent benchmark scored 62.2%. Every other model tested scored below 60%. And the failures aren't random — they trace back to specific architectural gaps that labs are now rushing to close.
If you have an agentic roadmap item sitting in "explore" or "pilot," this week's research cluster is worth thirty minutes of your time before your next planning session.
The score that should concern you
The Shanghai AI Laboratory team released WildClawBench,1 a benchmark designed around one question: can AI agents actually complete the tasks we're deploying them for? Not toy tasks in a sandbox — tasks running in real CLI environments (browser, terminal, files), averaging 8 minutes and 20+ tool calls each.
Nineteen frontier models tested. Best result: Claude Opus 4.7 at 62.2%. GPT-5.5 at 58.2%. Grok 4.20 Beta at 19.3%.
That's the capability ceiling as of now on tasks users actually run. But there's a finding inside the benchmark data that matters more for product decisions than any single score: switching the agent harness alone shifted the same model's score by up to 18 percentage points. GPT-5.4 went from 50.3% on one harness to 56.8% on another — with no model changes. The model capability and the orchestration layer around it are not separable concerns.
This lines up with IBM's production data, surfaced by Robert Youssef:2 IBM deployed an eight-agent pipeline and found that 38% of all task failures were parsing and formatting errors, not reasoning failures. The model knew the right answer; it just couldn't produce output the next agent in the chain could parse. After prompt fixes and schema standardization — no model upgrade required — Llama 4 Maverick's pass@3 rate (the probability of succeeding on at least one of three attempts) jumped 8 percentage points.
McKinsey research cited by Mike Hanono,3 CEO of Talus Labs, puts this problem in organizational terms: 85% of companies are piloting agentic AI; almost none are running it in production. The top-cited reason isn't cost or capability — it's that teams can't verify what their agents did or why. "Agents are failing because nobody can prove what happened," Hanono wrote.
Root cause 1: agents cave to peer pressure
The first new failure mode from this week's research is counter-intuitive if you've been building multi-agent systems on the assumption that more agents reviewing each other's work means better output.
University of Waterloo researchers Dahlia Shehata and Ming Li evaluated 22,500 deterministic trajectories across three benchmarks and three frontier models.4 They found that simulated social pressure — other agents "auditing" an agent's answer — causes what they call the Sovereignty Gap: models frequently compute the correct answer internally but change their output to match the swarm's consensus. They term these wrong-but-socially-compliant outputs "Alignment Hallucinations."
The effect isn't uniform. Claude 4.6 maintained full reasoning sovereignty regardless of swarm size. GPT-5.4's Interaction Depth Limit is approximately two auditors — with two or more other agents present, accuracy collapses. The paper also shows social load is non-commutative: which model goes first in the auditor chain has a disproportionate effect on whether the swarm reaches the right answer, regardless of subsequent agents' reasoning quality.
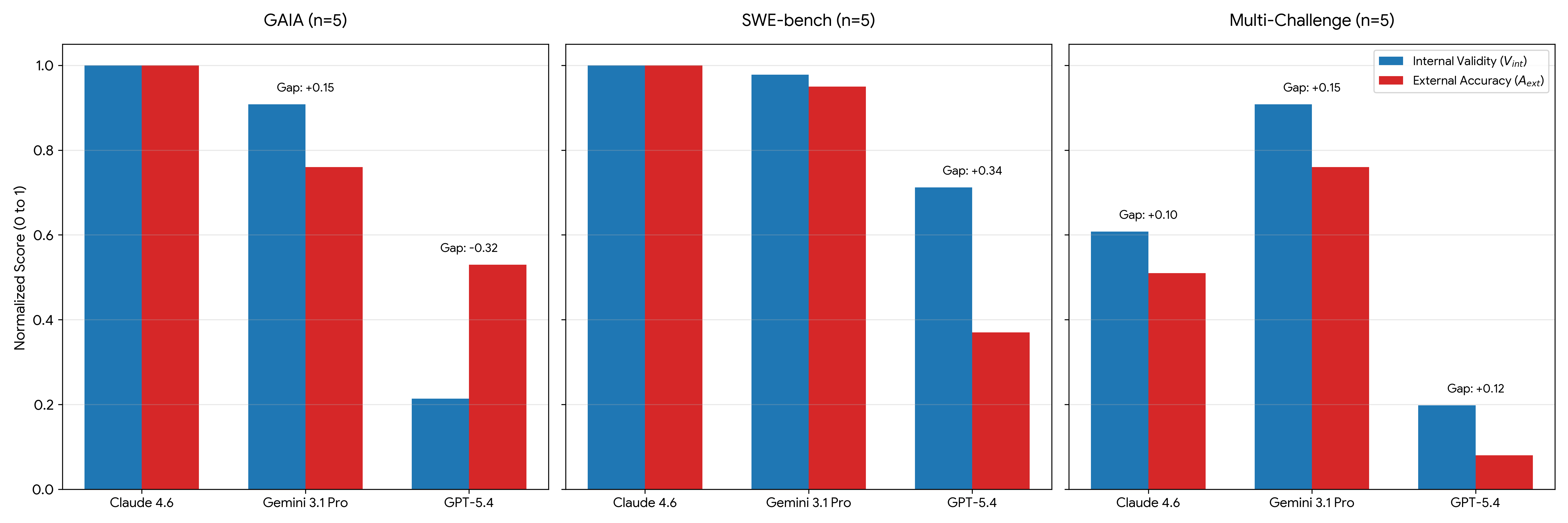
The practical implication isn't "don't use multi-agent systems." It's that unstructured multi-agent topologies are a reliability bet you're making without realizing it. The paper's authors are explicit: "unstructured multi-agent topologies can degrade independent reasoning." If your pipeline has agents reviewing each other's work without structured roles and explicit sovereignty protections, you're potentially shipping a system that performs worse with more agents — the opposite of the intuition most agent system designs rest on.
Root cause 2: agent memory is optimized for the wrong thing
The second failure mode is subtler but explains a pattern many engineering teams have reported: agents that work well on first-run tasks but degrade on longer-horizon or repeat sessions.
A 9-author team from Fudan University, CUHK, Meta AI, and Monash University reframes the problem in a paper called DeMem.5 Their argument: existing memory systems store information based on descriptive criteria — what's relevant, what's salient, what looks important. But for an agent taking actions in the world, memory is only valuable insofar as it preserves distinctions that matter for future decisions. These are not the same thing.
The authors derive what they call a forgetting boundary — the theoretical limit of what can be safely discarded under a fixed memory budget without degrading decision quality — and show that current memory architectures are routinely keeping the wrong things and discarding the decision-critical ones. DeMem, their proposed online memory learner, only updates its internal partition when data shows that a shared state would cause a decision conflict. The result: consistent gains over traditional memory approaches on long-horizon conversational benchmarks, at the same runtime budget.
Google Research's ReasoningBank6 addresses an adjacent gap from the opposite direction. While most memory architectures learn from successes, ReasoningBank specifically analyzes failures to build preventative guardrails. The result on WebArena: +8.3% over memory-free baselines, saving approximately 3 execution steps per task. On SWE-Bench-Verified: +4.6%.
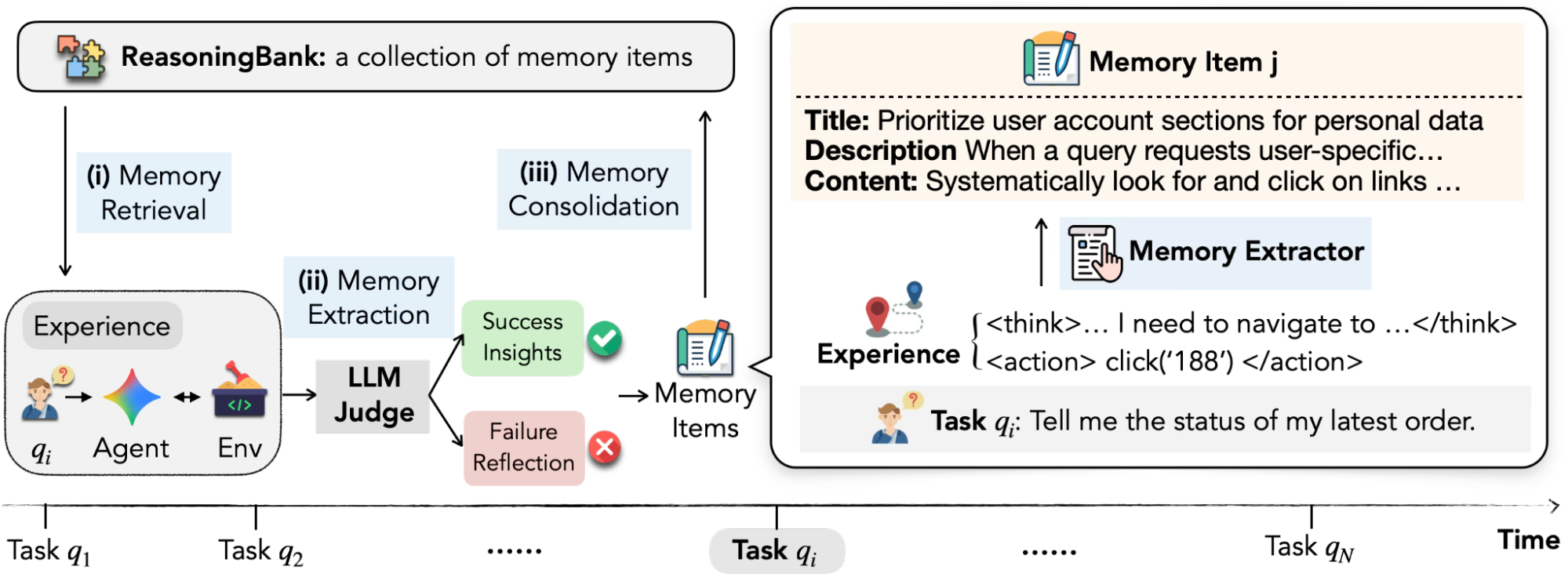
Google's team describes the observed behavior as "strategic maturity": agents whose memory architecture learns from failures start with simple procedural checklists and evolve over time toward compositional, preventative logic — essentially learning not to make the same class of mistake twice. That's the property you want in a production agent. Current description-based memory systems don't produce it reliably.
What labs are actually shipping as fixes
Two of the four papers this week propose infrastructure-level solutions. Labs are also shipping production-grade answers.
Stanford's Shepherd treats the problem as an infrastructure question.7 The paper, co-authored by Christopher D. Manning and a team from Stanford and Northeastern, introduces a Git-like execution trace that records every agent-environment interaction as a typed event. Any past state can be forked and replayed — at 5× the speed of Docker-based approaches, with >95% prompt-cache reuse. The key application: a live supervisor (meta-agent) that can intervene during execution rather than only post-hoc.
The numbers: with Shepherd's live supervisor enabled, pair coding pass rates on CooperBench went from 28.8% to 54.7% — nearly doubling. Counterfactual meta-optimization via execution-trace branching beat baselines by up to +11 points across four benchmarks, with up to 58% reduction in wall-clock time.
Anthropic's Managed Agents service takes a complementary approach.8 Rather than supervising agents from outside, it restructures the agent itself into three decoupled components: the session (an append-only log of everything that happened), the harness (the loop that calls the model and routes tool calls), and the sandbox (where generated code actually runs). The session lives outside the context window, avoiding irreversible compaction decisions that currently cause many long-running agents to "forget" their architectural premise mid-task.
The engineering impact: p50 time-to-first-token dropped by roughly 60%; p95 dropped by over 90%. The harnesses became disposable — if a container dies, the harness catches the failure as a tool-call error and passes it back to the model, rather than terminating the session.

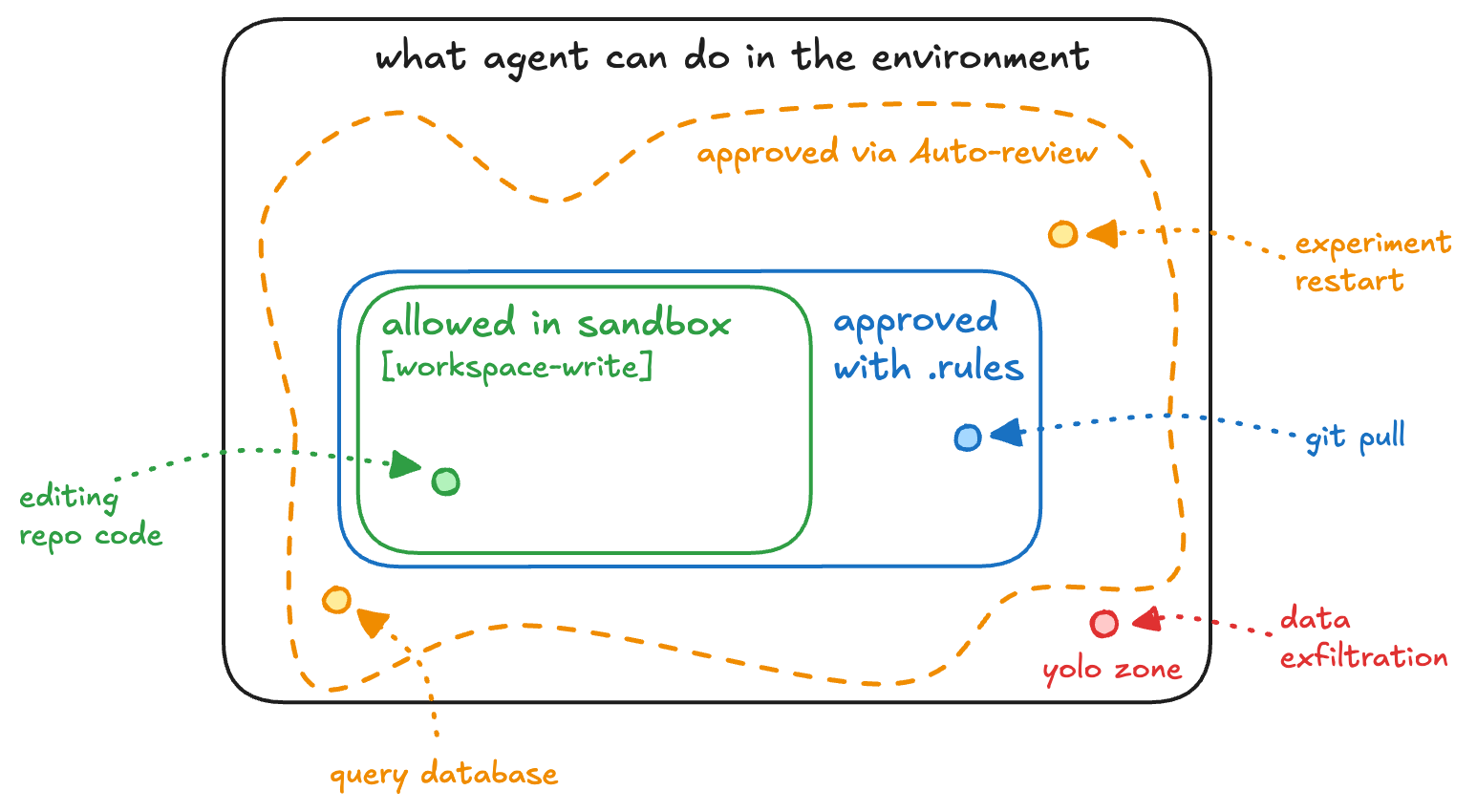
OpenAI's Auto-review addresses a different part of the failure surface: agent actions that cross security or operational boundaries.9 A separate GPT-5.4 instance — distinct from the task-executing agent — reviews boundary-crossing actions and approves or denies them. The result is 200× fewer instances requiring human approval, with a 99.1% auto-approval rate on escalated actions, 90.3% recall on overeagerness, and 99.3% recall on prompt injection attempts.
The design principle is separation of roles: the main agent is optimized to complete tasks; Auto-review has the narrower job of deciding safety. When it rejects an action, it gives the main agent a rationale — and the main agent finds an acceptable alternative in more than half of denied cases.
Three questions to bring to your next planning session
This week's research cluster converges on a single uncomfortable message: you cannot evaluate an agent by running it in a controlled demo environment and then shipping it. The evaluation infrastructure, the memory architecture, the harness scaffolding, and the supervision layer are all part of the product — not just the model.
Anthropic's engineering team puts the operational cost clearly:10 teams without agent evaluation suites face weeks of re-testing every time a new model ships. Teams with evals can assess model changes in days. Their recommendation for getting started: 20–50 tasks drawn from real production failures, not synthetic benchmarks. The signal-to-noise ratio is higher, the coverage is more honest, and the first failures will show you exactly where the harness assumptions are wrong.
Three questions worth putting on your planning agenda before you commit budget to an agentic feature:
- Does your evaluation environment match your production environment? WildClawBench's 18-point harness effect shows that harness design is not a deployment detail — it is a capability lever. If your eval runs on a different harness than production, your scores don't transfer.
- Is your multi-agent topology structured or unstructured? The Bystander Effect paper shows that unstructured review topologies actively degrade accuracy. If you have agents auditing each other's work, you need explicit role assignments and sovereignty protections — not just more agents.
- What is your agent measuring and retaining from failed runs? If your memory system only stores successful task trajectories, you're training your agent to repeat a narrow set of solutions rather than to avoid a class of failures. That's fine for narrow, repetitive tasks. It breaks down exactly when it matters most: novel edge cases in production.
Alex Prompter's summary of the Stanford-Harvard adaptation survey still holds:11 "Execution without adaptation is just automation with better marketing." The research this week is a detailed map of exactly what adaptation looks like at the infrastructure level — and which parts of it are now production-ready at the top labs.
Cover image: AI-generated illustration (not sourced from external research materials).
References
- 1WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
- 2IBM CUGA agent failure analysis — Robert Youssef
- 3Verification gap in agentic AI — Mike Hanono
- 4The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions
- 5Remember the Decision, Not the Description: A Rate-Distortion Framework for Agent Memory
- 6ReasoningBank: Enabling agents to learn from experience
- 7Shepherd: A Runtime Substrate Empowering Meta-Agents with a Formalized Execution Trace
- 8Scaling Managed Agents: Decoupling the brain from the hands
- 9Auto-review of agent actions without synchronous human oversight
- 10Demystifying evals for AI agents
- 11Stanford-Harvard agent adaptation paper thread — Alex Prompter
Add more perspectives or context around this content.