
21/6/2026 · 5:10
Project Fetch phase two moves Claude from robotics copilot to hardware interface agent
Anthropic's Project Fetch phase two is not proof that Claude has solved robotics. It is evidence that Opus 4.7 can now cross much of the software interface layer around unfamiliar hardware by itself, turning physical-world agency into a documentation, SDK, and control-loop problem.

Vistazo a la investigación
The important result in Project Fetch phase two is not that Claude can make a robot dog move. It is that Anthropic's Frontier Red Team re-ran a physical-world task from less than a year earlier and found that Claude Opus 4.7, working through Claude Code with almost no human assistance, completed the software-heavy parts dramatically faster than the human teams that had done the same work in the first experiment. Anthropic describes the June 18, 2026 update as a test of whether Claude could help employees perform sophisticated robotics tasks, and reports that Opus 4.7 was about 20 times faster than the fastest human team on the tasks completed by the original participants. 1
That makes the post a small robotics benchmark and a larger safety signal. The result does not say that language models have solved embodied control. Anthropic explicitly says the latest Claude models still struggled with the precise beach-ball retrieval task and that the experiments did not test harder low-level robotic control such as learning a specific actuation policy. 1 The sharper claim is narrower: the software interface layer between a model and off-the-shelf hardware is getting easier for the model itself to traverse.
What changed from phase one
The original Project Fetch experiment, published in November 2025, randomly split eight Anthropic researchers and engineers without extensive robotics experience into two teams: one with Claude access and one without. Both teams were asked to operate quadruped robodogs and eventually program them to fetch beach balls. 2 Team Claude accomplished more tasks and finished shared tasks in about half the time, while Team Claude-less expressed more confusion and had more trouble connecting to the robot and its sensors. 2
Phase two removes most of that human collaboration. Anthropic ran three trials of Claude Opus 4.7 in Claude Code, using adaptive thinking at maximum effort. The human researcher's role was limited to plugging a laptop into the robodog, entering the initial prompt, approving commands, and approving the model to move to the next task. 1 Because Claude could not use the physical controller, Anthropic excluded the controller task and did not count the time for a researcher to use Claude's programmed controller to retrieve the ball, though the team says it confirmed the controller worked as intended. 1
| Dimension | Phase one | Phase two |
|---|---|---|
| Unit being evaluated | Teams of four human participants, with or without Claude access. 2 | Claude Opus 4.7 running in Claude Code, with a researcher only approving and advancing tasks. 1 |
| Main question | How much uplift Claude gives non-experts using unfamiliar hardware. 2 | Whether the model can perform the software-heavy robotics objectives largely by itself. 1 |
| Hard boundary | Team Claude nearly reached autonomous fetching but did not complete it. 2 | Opus 4.7 still failed at controlled autonomous fetching, especially the closed-loop ball movement. 1 |
The real gain was interface selection, not dexterity
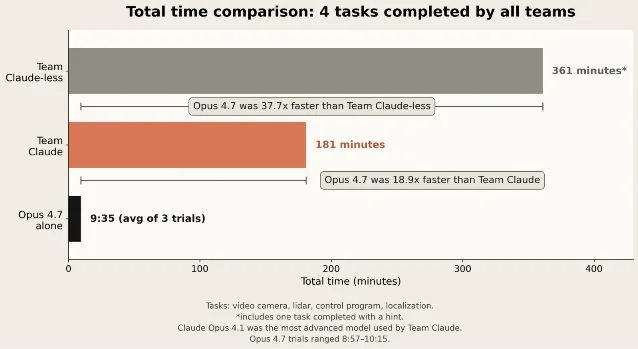
The timing numbers are stark. For the four tasks completed by both human teams in phase one, Opus 4.7 averaged 9 minutes and 35 seconds across three trials, compared with 181 minutes for Team Claude and 361 minutes for Team Claude-less. Anthropic reports this as 18.9 times faster than Team Claude and 37.7 times faster than Team Claude-less. 1 Across the five phase-two tasks, Team Claude took 264 minutes, while Opus 4.7 averaged 12 minutes and 7 seconds; Team Claude-less had not completed every task in that table. 1
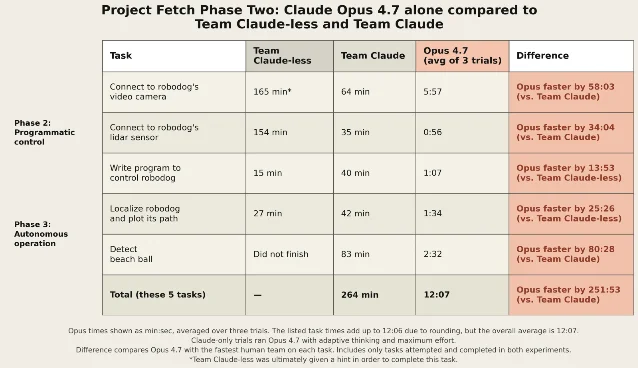
The important mechanism is not that Claude became a better robot body. It became better at the surrounding software work: finding the right way to connect to the robot's video camera and lidar sensor, writing a usable programmatic controller, localizing the robot's path, and detecting the beach ball. Anthropic says the human teams had struggled to choose among several ways of interfacing with the robot's sensors, while Opus 4.7 quickly identified the best path. 1
That distinction matters. A large part of making AI act in the physical world may not start with new robot bodies or end-to-end motor policies. It may start with models learning to operate the messy middleware around existing machines: SDKs, sensor feeds, connection protocols, control programs, calibration scripts, and monitoring tools. Phase two suggests that a frontier model can now traverse much of that layer without the human exploration that dominated the first experiment.
Less code, less thrashing
The code-volume result points in the same direction. In phase one, Team Claude wrote far more code than Team Claude-less. Anthropic described that as partly useful exploration and partly side-quest risk. 2 In phase two, Opus 4.7 was as or more successful than both human teams while producing far less code than Team Claude: 1,045 lines for Opus 4.7, 1,136 for Team Claude-less, and 10,309 for Team Claude. 1
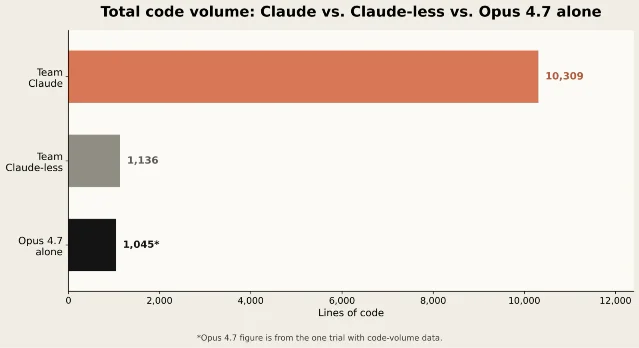
This does not prove that the model has a clean internal model of robotics. Anthropic notes that Opus 4.7 sometimes made poor choices, including defaulting to an outdated object-detection algorithm before working around it. 1 But the pattern is still meaningful. The model no longer needs to spray a large amount of speculative code across the problem space to reach a working interface. It can often pick a route, test it, and recover.
That is exactly the kind of capability that turns hardware from a bespoke research environment into an agent tool. The robot was not trained for Claude. The setup was an off-the-shelf quadruped, a laptop, Claude Code, and a human approving operations. If the model can repeatedly map unknown hardware into a controllable software surface, physical-world agency begins to look less like a robotics breakthrough and more like another instance of tool use.
The failure mode is still closed-loop control
The boundary is just as important as the gain. The humans could use their eyes and hands to make small corrective movements as the ball drifted off course. Claude could move behind the ball and position the robot to knock it toward the starting area, but Anthropic says its attempts were poorly controlled and unsuccessful. 1
This is the gap between writing code that connects to a physical system and controlling a physical process under continuous feedback. The former resembles agentic coding: inspect the environment, modify files, run commands, recover from errors. The latter requires fast perception-action loops, error correction, and enough embodied context to know how a previous movement changed the world.
Anthropic says a researcher with more robotics experience successfully programmed autonomous fetching, and the team believes current Claude generations could likely do the same with more time and scaffolding. 1 That claim should be treated as a watchpoint, not a result. The published experiment shows strong autonomy in the digital interface layer and weak autonomy in the final physical-control layer.
Why safety researchers should care
Project Fetch sits next to Anthropic's other recent Frontier Red Team work because it tracks the same transition pattern: first a model uplifts humans, then humans provide light scaffolding for the model, then the model performs more of the task alone. Anthropic makes that comparison directly in the phase-two post, citing cybersecurity as another domain where this pattern has appeared. 1 In its June 8 N-day exploit evaluation, Anthropic reported that Claude Mythos Preview autonomously built eight working Firefox code-execution exploits from 18 recent security patches and eight full Windows kernel privilege-escalation chains from 21 patches. 3
The robotics result is less mature than the cyber result, but the risk logic is similar. If the bottleneck is scarce human expertise, model progress can compress the time needed to cross it. In cybersecurity, that means patch windows shrink. In robotics, it could mean that unfamiliar hardware becomes easier for a frontier model to instrument, script, and use.
Anthropic's own phrasing is cautious: the company says we may be entering the early era of physical agentic AI, not that we have arrived at general robot autonomy. 1 That is the right level of caution. Project Fetch phase two is a limited benchmark with a small task suite, a single hardware setup, and researchers still approving the model's actions. It is not evidence that Claude can be dropped into arbitrary embodied environments.
But it is evidence that the distance between software agents and physical agents is not only a robotics problem. It is also a documentation, interface, and orchestration problem. Claude's improvement came where agentic coding is already strong: reading the environment, choosing tools, generating control code, and debugging under feedback. The next red-team question is whether that competence stays bounded to benign off-the-shelf tasks, or generalizes into faster access to more consequential physical systems.
What to watch next
Three follow-up measurements would make Project Fetch more decision-useful.
First, Anthropic should separate interface acquisition from physical control. If future models keep improving on connection, sensor access, and code generation while still failing controlled fetching, the safety story is about easier hardware enablement. If they also solve closed-loop retrieval quickly, the story becomes embodied task autonomy.
Second, the benchmark needs hardware diversity. A single robodog is useful for repeatability, but the strategic question is whether a model can generalize across unfamiliar machines, vendor SDKs, degraded documentation, and partially incorrect online guidance.
Third, command approval should be measured explicitly. Phase two kept a human approving commands and task transitions. 1 Future versions should report how many approvals were needed, where they mattered, and whether stricter approval policies degrade performance. For physical agents, the governance surface is not only what the model can code. It is where the human gate still changes the outcome.
Project Fetch phase two is therefore best read as a capability shift at the boundary. Claude is not yet a robot operator in the strong sense. It is becoming a much faster translator between intent and machine-controlling software. That translation layer is where physical agentic AI may arrive first.



Añade más opiniones o contexto en torno a este contenido.