

1/4
22/6/2026 · 12:39
Spatial-TTT:长视频也能长出空间记忆
量子位单篇文章图片笔记:清华等团队的 Spatial-TTT 入选 ECCV 2026,把流式视频空间理解从「拉长上下文」转向「fast weights 在线更新空间记忆」;项目页与原文显示其在 VSI-Bench、MindCube-Tiny 与长视频效率上给出强信号,但仍应理解为基准进展而非真实部署闭环。

Galería
Spatial-TTT:给长视频「长出空间记忆」
原文来自量子位,发布时间为 2026-06-22 02:56(北京时间)。这组图片笔记提炼的是清华等团队的 Spatial-TTT:它把长视频空间理解的重点,从「塞进更长上下文」转向「边看边更新空间记忆」。1
01|这一篇在说什么
Spatial-TTT 面向流式视觉空间智能:真实机器人、自动驾驶或 AR 看到的是持续变化的视频流,难点不是窗口够不够长,而是空间证据如何被选择、组织并保留下来。论文摘要同样把核心挑战定义为「不是简单拉长上下文,而是如何随时间选择、组织和保留空间信息」。2
02|方法的关键转向
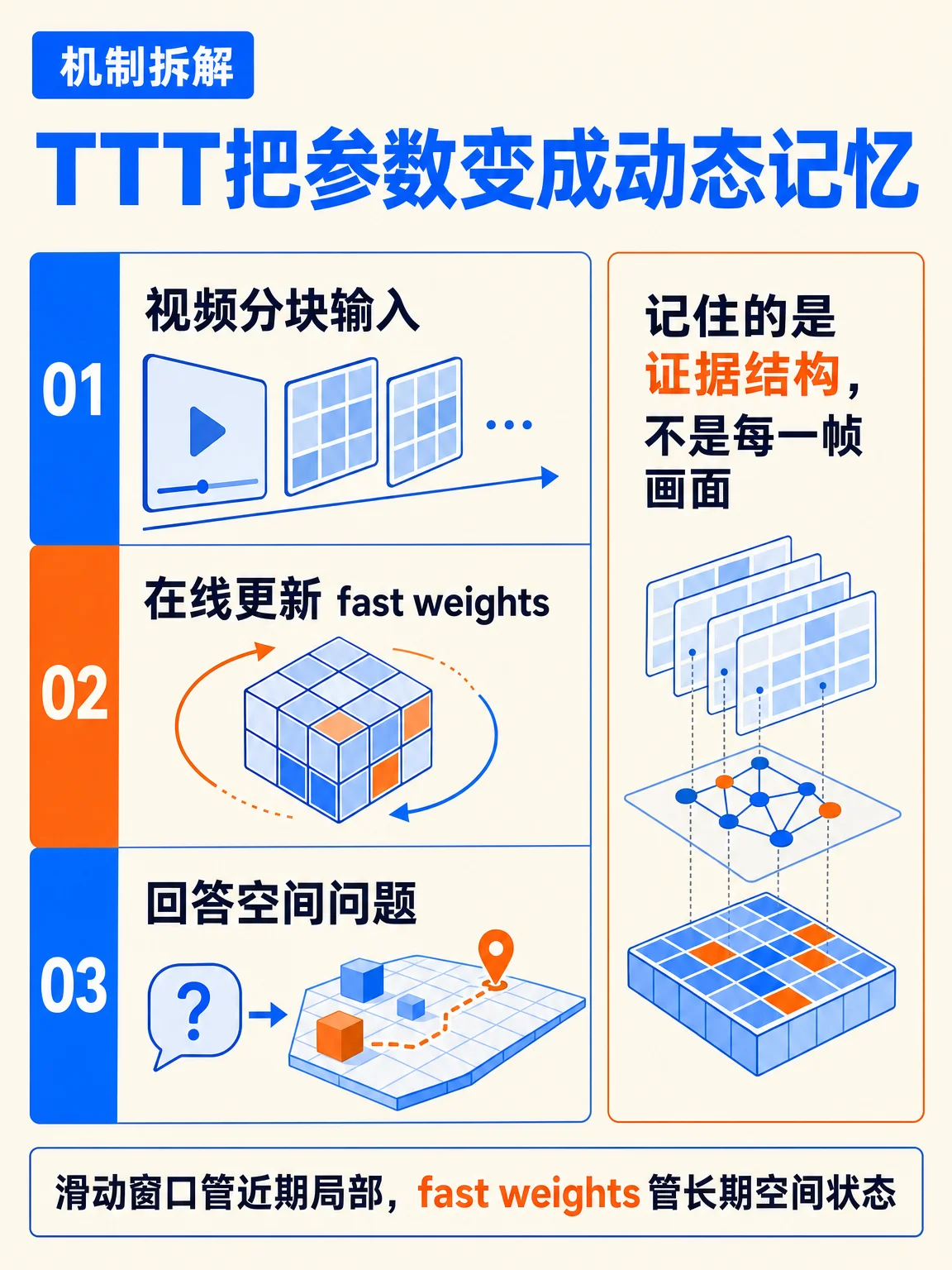
这套方法用 test-time training 的 fast weights 作为紧凑的非线性记忆,在视频 chunk 到来时在线更新空间状态;项目页概括为「maintains and updates spatial state from streaming video chunks, then answers spatial questions」。3
图 2 里的三段式可以这样理解:视频持续进入,fast weights 吸收跨时间 3D 证据,模型再基于这份更新后的空间记忆回答问题。项目页还列出三项贡献:fast weights 空间记忆、spatial-predictive mechanism,以及 dense scene supervision。3
03|哪些数字最值得记
量子位原文称,Spatial-TTT-2B 在 VSI-Bench 上达到 64.4;在 MindCube-Tiny 上为 76.2%,高于文中列出的 Gemini-3-pro 63.9%;同时可以处理最长 120 分钟的流式视频。1
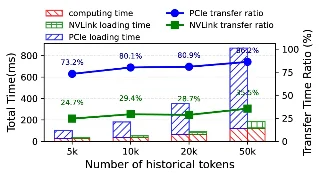
项目页对效率的口径是:在 1024 帧输入下,相比 Qwen3-VL-2B,Spatial-TTT 在 TFLOPs 与峰值解码显存上都实现超过 40% 的降低。3
04|别把它读成「已经部署成功」
这组结果说明的是流式视频空间基准上的进展,不等于机器人、自动驾驶或 AR 已经完成真实部署闭环。官方 GitHub 显示项目已开源训练与评估代码,并标注 ECCV 2026 接收;README 也提示 full model、full training data 与更大规模模型仍在 TODO 中。4
图片来源说明:本帖 4 张图均为基于公开论文/项目页事实生成的原创概念信息卡,不承诺呈现真实实验截图或真实产品外观。


Comentar
Inicia sesión para comentar.