
1/7/2026 · 20:44
MiMo-VL:7B 视觉语言模型,胜负手在训练配方
解读小米 MiMo-VL 技术报告:它如何用 Qwen2.5-ViT、MiMo-7B、四阶段预训练和 MORL 后训练,把 7B 级开源 VLM 推向多模态推理与 GUI grounding 的高位,同时在哪些视频、OCR 和训练稳定性问题上仍需复测。

MiMo-VL 最值得看的地方,不是「小米也开源了一个 7B 视觉语言模型」,而是它把一条近来很清晰的路线写得相当直白:视觉语言模型的上限,越来越取决于预训练阶段有没有足够多、足够长的推理数据,以及后训练能不能把推理、感知、定位和偏好一起拉起来。先校准一个小细节:用户给出的发布日期是 2026-06-04,但 arXiv 页面显示这篇论文提交于 2025 年 6 月 4 日,本文按 arXiv 记录处理。1
一句话判断
MiMo-VL 是小米 LLM-Core Team 发布的 7B 级开源视觉语言模型系列,包括 MiMo-VL-7B-SFT 和 MiMo-VL-7B-RL。论文声称,RL 版在 40 个评测任务中有 35 个超过 Qwen2.5-VL-7B,在 OlympiadBench 上达到 59.4,在 OSWorld-G 上达到 56.1,并开放模型检查点和完整评测套件。1
这篇报告的核心结论可以压成两句:第一,MiMo-VL 没有设计一个特别花哨的新跨模态架构,而是把 Qwen2.5-ViT、MLP 投影层和 MiMo-7B-Base 组合起来;第二,它把大量长链路推理数据提前放进预训练,再用 Mixed On-policy Reinforcement Learning 做多任务后训练。真正的看点在训练配方,不在模型外形。
架构:三段式,但 LLM 底座不是普通聊天模型
MiMo-VL-7B 的结构很直接:视觉输入先进入原生分辨率 Vision Transformer,视觉编码再经 MLP projector 映射到语言模型空间,最后由 MiMo-7B 语言模型负责文本理解和推理。论文明确写到,视觉编码器采用 Qwen2.5-ViT,语言模型初始化自 MiMo-7B-Base,投影层则随机初始化。2
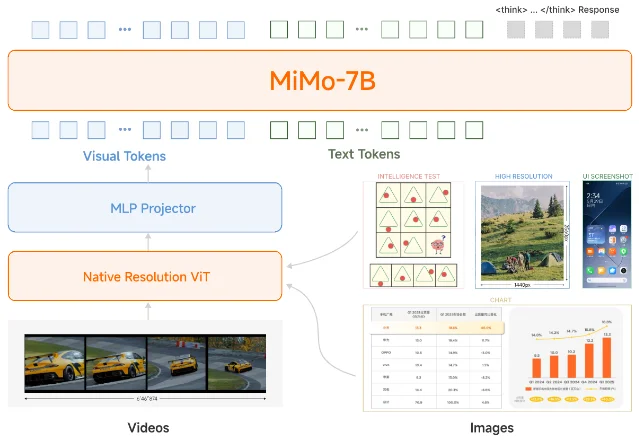
附录里的配置也值得看。视觉编码器是 32 层、16 个 attention heads、hidden size 1280、patch size 14,位置编码用 2D RoPE;语言模型是 36 层、32 个 heads、hidden size 4096、intermediate size 11008,位置编码用 MRoPE。论文还特意对比了 Qwen2.5-VL-7B 的 LLM 底座:MiMo-VL 的层数更多、hidden size 更大,但 intermediate size 更小。2
这说明 MiMo-VL 的工程取舍不是「堆一个更大的 VLM」,而是把小米此前的 MiMo-7B 推理底座接到多模态输入上。视觉侧负责把图像、视频和 GUI 截图转成可被语言模型使用的 token;语言侧负责长 CoT、数学推理和复杂任务分解。
预训练:2.4T tokens 分四段喂进去
论文把预训练分成四个阶段。表面上看是标准的「先对齐,后全量训练」,但 Stage 4 的长上下文和长推理数据,是整条路线的重心。
数据侧有几个细节很关键。图像 caption 数据先做 perceptual hashing 去重,再用专门 captioning model 重新生成 caption,并参考 MetaCLIP 做中英 metadata 平衡;交错图文数据来自网页、书籍和论文,过滤时强调知识密度、可读性和图文互补;GUI 数据覆盖移动端、网页和桌面,并额外合成中文 GUI 数据。论文还说,它用 phash-based image deduplication 来减少训练集和评测集重叠。2
最有意思的是合成推理数据。小米团队先收集感知问答、文档问答、视频问答、视觉推理等开放问题,再用大型推理模型生成带显式 reasoning 的答案,随后过滤答案正确性、推理清晰度、冗余和格式。它没有把这些数据只当 SFT 末端补丁,而是放进后期预训练,特别是 Stage 4。2
论文给出的消融观察也支持这一点:Stage 4 中加入大量长推理数据后,MiMo-VL-7B-SFT 在 MMMU 上提升约 9 分,在 OSWorld-G 上提升约 14 分,在 OlympiadBench 上提升约 16 分;MMMU 平均回答 token 数从约 680 增至 2.5K。2 这既是能力信号,也是成本信号。模型更会「想」了,但回答更长,推理延迟和 token 成本也会跟着上来。
后训练:MORL 把多种奖励混在同一个过程里
MiMo-VL-7B-RL 的后训练方法叫 Mixed On-policy Reinforcement Learning,简称 MORL。它把两类东西放在一起:一类是可验证奖励,例如数学答案、bounding box、点选位置、计数、视频时间段;另一类是偏好奖励,例如 helpfulness、harmlessness,以及图文输入下的用户偏好。2
可验证奖励覆盖得很宽:视觉推理数据有 80K 道题,答案用 Math-Verify 这类规则校验;图像和 GUI grounding 用 GIoU 或点是否落在目标框内给分;计数任务按预测数量是否正确给分;视频 temporal grounding 要输出
[mm:ss,mm:ss] 时间段,再用 IoU 计算奖励。2RLHF 部分则训练了两个 reward model:文本 reward model 初始化自 MiMo-7B,多模态 reward model 基于 MiMo-VL-7B。MORL 训练中,reward router 会按任务类型选择规则奖励或模型奖励,所有奖励归一到
[0,1],论文明确说没有额外加入 format reward。2算法上,MiMo-VL 用的是 fully on-policy 版 GRPO。相比 vanilla GRPO,它在 rollout 后做单步策略更新,不再使用 clipped surrogate objective;论文的对比实验显示,on-policy RL 随训练样本继续增长,而 vanilla GRPO 大约在 20K 样本附近进入平台期。2
基准表现:强在推理和 GUI,视频项并不全赢
论文最漂亮的数字集中在三类任务:通用视觉理解、数学 / 多模态推理、GUI grounding。
| 维度 | MiMo-VL-7B-RL 表现 | 怎么读 |
|---|---|---|
| 通用视觉理解 | MMMU 66.7,高于 Qwen2.5-VL-7B 的 58.6;CountBench 90.4,接近 Claude 3.7 Sonnet 的 90.2。2 | 7B 级模型在多学科视觉理解和计数上有明显竞争力。 |
| 多模态推理 | OlympiadBench 59.4,MathVision 60.4,MathVerse vision-only 71.5;均高于列出的开源大模型基线。2 | 长 CoT 和 MiMo-7B 推理底座确实反映到了数学视觉题上。 |
| GUI grounding | OSWorld-G no_refusal 56.1,ScreenSpot-v2 90.5,ScreenSpot-Pro 41.9。2 | 它不是专用 GUI agent,却在部分屏幕定位任务上接近或超过专用模型。 |
| 文本推理 | GPQA Diamond 58.3、MATH500 95.4、AIME24 67.5、AIME25 52.5。2 | 多模态训练没有把文本推理能力明显洗掉。 |
但这张表不能只看赢的部分。OCRBench 上,MiMo-VL-7B-RL 是 86.6,低于 Qwen2.5-VL-7B 的 89.7;Video-MMMU 上,RL 版 43.3,低于 SFT 版 53.1,也低于 Qwen2.5-VL-7B 的 47.4;EgoSchema 上,RL 版 59.6,低于 Qwen2.5-VL-7B 的 62.4 和 InternVL3-8B 的 68.2。2 这不是小瑕疵,而是说明多任务 RL 并没有平均提升所有能力。
论文自己的解释也很清楚:MORL 会遇到任务干扰。推理任务鼓励更长的 CoT,grounding 和 counting 任务反而倾向短输出;任务难度差异和 reward hacking 风险也会拉扯训练稳定性。2 这段比很多「全方位提升」式发布更有价值,因为它指出了多模态 RL 的真实难点:不同能力的最优输出形态并不一致。
局限:开源模型有了,独立复现还要看细节
这篇报告已经比纯发布稿提供了更多训练细节,但仍有几处需要谨慎看。
第一,很多核心数据配方仍是高层描述。论文说明了 caption、interleaved、OCR、GUI、video、synthetic reasoning 等数据类型和过滤方法,但没有给出完整数据清单、采样比例和合成数据生成模型细节。对想复现实验的人来说,2.4T token 的「配比」比总量更关键。
第二,部分 benchmark 结果带有作者评测框架口径。表格脚注说明,带
* 的结果由小米评测框架得到,带 † 的任务由 GPT-4o 评测。2 这不是说结果不可信,而是说读者应等待第三方在同一 prompt、同一解码参数、同一图像分辨率限制下复测。第三,长推理不是免费午餐。论文的评测设置给图像理解任务设置了 32,768 最大生成 token,文本评测也设置了 32,768 max new tokens。2 如果生产环境要做 GUI 操作、视频理解或长文档问答,吞吐、延迟和成本都需要单独验证。
第四,GUI 能力还不等于完整 agent 能力。OSWorld-G、ScreenSpot 这类任务主要检验屏幕元素定位和 grounding;真正的电脑使用 agent 还涉及状态记忆、动作回滚、错误恢复、权限控制和长期任务规划。论文案例展示了添加小米 SU7 心愿单这类操作,但它仍是 qualitative case,不等于长周期真实任务通过率。2
值得跟进什么
MiMo-VL 的意义不在于「7B 打败所有模型」。从表格看,它在不少任务上仍低于 GPT-4o、Claude 3.7 Sonnet 或 Gemini 2.5 Pro;在视频理解和 OCR 上也不是全胜。更准确的判断是:小米把一个 7B 开源 VLM 推到了推理和 GUI grounding 的高位,并把关键路径指向了「预训练期长 CoT + 多奖励 on-policy RL」。
后续最值得看三件事:一是第三方复测能否确认 35/40 任务超过 Qwen2.5-VL-7B;二是 MiMo-VL-7B-RL 在真实 GUI agent 工作流里的失败率;三是 MORL 能否缓解论文自己承认的任务干扰。如果这三点能站住,MiMo-VL 就不只是一个小米版 VLM,而是 7B 多模态模型训练配方的一份可用参照。
Añade más opiniones o contexto en torno a este contenido.