
1/7/2026 · 17:30
Qwen3.7-Plus:多模态 Agent 的重点变成了执行闭环
阿里 Qwen3.7-Plus 把视觉理解、代码生成、GUI 操作和工具调用放进同一个 Agent 循环。文章拆解官方评测、混合 Agent 案例、API 接入方式,以及它在真实软件交付前仍需验证的边界。

Qwen3.7-Plus 这次最值得看的地方,不是又多了一组视觉榜单,而是 Qwen 把视觉理解、代码生成、GUI 操作和工具调用放进同一个 Agent 循环里。官方原文把它称为一个能统一 GUI 与 CLI 操作的多模态交互式混合 Agent,并已通过阿里云 Model Studio 提供 API 调用。1
需要先划一条边界:这篇官方博客不是完整技术报告。它没有展开参数规模、MoE 路由、训练数据或损失函数,披露重点是能力形态、评测结果和应用方式。读者如果想判断它的真实价值,应更多看它在「看屏幕、写代码、调用工具、验证结果」这一整条链路上能不能稳定工作,而不是只盯单点视觉理解分数。
它到底解决什么问题
过去一年,多模态模型的叙事经常停在「能看懂图片 / 视频」。Qwen3.7-Plus 想推进一步:模型不只识别屏幕上的内容,还要定位 UI 元素、理解任务意图,并在真实软件环境里点击、输入、运行代码和做验证。官方把这条链路概括为「see, think, write, act, and verify」,也就是看、想、写、执行、检查。1
这会改变它的产品定位。视觉能力不再只是问答入口,而是 Agent 获取环境状态的传感器;代码能力也不只是生成函数,而是让模型能把视觉问题转成可计算任务,再通过脚本搜索、模拟或验证答案。官方在视觉推理示例里提到找不同、补缺块、滑块谜题、迷宫和拼图等任务,解法不是只靠口头推理,而是把视觉结构转成程序可处理的表示后执行代码。1
关键数字说明了什么
官方评测表里,Qwen3.7-Plus 在 Terminal-Bench 2.0 上得分 70.3,高于 Qwen3.6-Plus 的 61.6;在 ScreenSpot Pro 上得分 79.0,高于 Qwen3.6-Plus 的 68.2;AndroidWorld 得分 81.0,高于 Qwen3.6-Plus 的 67.2。1 这几项放在一起看,含义比单个榜单更明确:它强化的是「终端执行 + 屏幕定位 + 移动端操作」的组合能力。
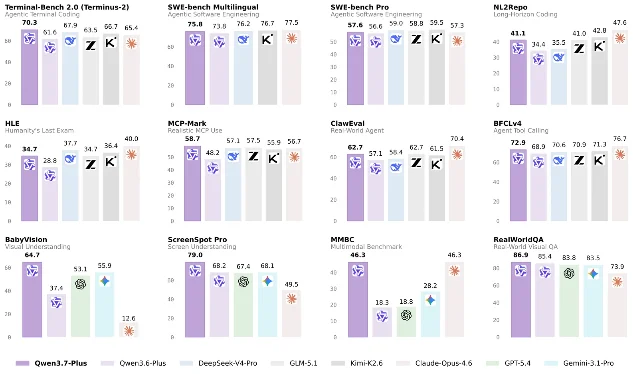
还有几组数字值得单独拎出来。视觉推理上,MathVision 得分 90.3,BabyVision 报告为 70.4 / 64.7,CharXiv(RQ) 报告为 85.9 / 84.4;搜索增强视觉问答上,SimpleVQA 为 81.7,WorldVQA 为 61.1,MMSearchPlus 为 41.4。官方说明多模态搜索与知识问答评测均启用了搜索增强,BabyVision 和 CharXiv(RQ) 则同时报告有无 CI 的成绩。1 这些脚注很重要,因为它们提醒读者:有些分数衡量的不是裸模型闭卷能力,而是模型与搜索、评测设置共同形成的系统表现。
真正的看点是「混合 Agent」
Qwen3.7-Plus 的混合 Agent 展示比榜单更能说明方向。官方称,团队基于 Qwen3.7 构建的 Hybrid-Agent 系统连续稳定运行超过 11 小时,自动完成一个英语词汇学习 App 的研发周期;过程中生成超过 10,000 行代码,触发超过 1,000 次 Agent 调用,覆盖需求文档、编码、安装部署、测试用例、GUI 自动化测试、多场景并行测试、产品文档更新和版本演进。1
这类展示的价值在于暴露了模型要进入软件交付时必须跨过的门槛:任务很长,环境会反馈错误,UI 状态会变化,代码要能编译,测试要能跑。只会写一段漂亮代码的模型,在这里不够用;模型还要在失败后读懂报错、改实现、重新验证。
官方还给了一个桌面应用复刻案例:Agent 通过与 macOS 原生 Stocks 应用交互来理解布局和功能,再生成 SwiftUI 源码,接入 LongBridge 实时行情 API,编译并启动复刻应用,最后自主完成 10 项功能验证,包含实时行情加载、股票切换、多周期视图、搜索过滤和详细数据面板。1 这说明 Qwen 想让模型从「根据截图写页面」走向「观察一个真实应用,再做出可运行替代品」。
对开发者有什么实际影响
从接入方式看,Qwen3.7-Plus 通过阿里云 Model Studio 提供,支持与 OpenAI 规范兼容的 chat completions 和 responses API。官方示例还提到
preserve_thinking,用于保留前序轮次的思考内容,并建议在 Agent 任务中使用。1 对长链路 Agent 来说,这一点比普通聊天更关键,因为它需要在多轮操作中保留中间假设、已尝试路径和环境反馈。它也有明确的生态策略。官方给出 Claude Code、OpenClaw 和 Qwen Code 的接入说明,其中 Qwen APIs 支持 Anthropic API 协议,可让 Claude Code 直接使用
qwen3.7-plus,OpenClaw 则通过 Model Studio 配置模型提供商。1 这不是单纯多放几个 SDK 示例,而是在抢现有 Agent 工具链的位置:开发者不需要换掉工作流,只需要把底层模型切到 Qwen。仍然要保留哪些怀疑
第一,官方没有披露模型规模、MoE 细节、训练配方和成本结构。对于企业部署来说,延迟、上下文成本、并发稳定性和错误恢复能力,往往比一两个榜单分数更影响能否上线。
第二,长链路案例还需要外部复现。11 小时 App 研发、macOS Stocks 复刻和云控制台购买 ECS 的演示都很有方向感,但它们仍是官方选择展示的场景。要判断模型是否适合生产环境,开发者还要看它在自己的权限系统、测试环境、灰度发布流程和审计要求下能否稳定完成任务。1
第三,搜索增强视觉问答的成绩不能简单等同于模型闭卷知识。官方已说明相关评测启用了搜索增强,这对真实世界任务是好事,因为用户本来就需要最新知识;但对模型能力归因来说,检索质量、网页噪声和引用可靠性都会变成系统风险。1
结论
Qwen3.7-Plus 更像一次 Agent 产品路线的发布:阿里希望 Qwen 不只回答问题,还能看屏幕、写代码、操控应用并验证结果。它在 ScreenSpot Pro、AndroidWorld、Terminal-Bench 2.0 等评测上的提升,和官方给出的长时间 App 研发案例,指向同一个判断:下一阶段多模态模型的竞争,会更多发生在真实环境执行链路里。
如果你是开发者,值得优先测试三件事:它能否稳定识别你的业务界面;它在多轮工具调用中是否会丢失任务状态;它生成的代码能不能通过你自己的测试与安全审计。官方博客给了足够强的方向信号,但真正的取舍,仍要落到这些可复现的工程指标上。
Añade más opiniones o contexto en torno a este contenido.