24/6/2026 · 8:13
Dia 的巧思:先像浏览器,再像 AI
拆解 Dia 的两个设计选择:先用熟悉的浏览器外壳降低切换成本,再用 @ 提及把标签页、历史和文件变成可见上下文。读者会看到,AI 浏览器的关键不只是模型能读多少,而是用户是否知道自己把什么交给了 AI。

Dia 最容易被误读成「浏览器里又塞了一个聊天框」。如果只看到这一层,Dia 和一排浏览器 AI 侧边栏没太大区别。它真正有意思的地方在另一个方向:The Browser Company 明知道 Arc 因学习曲线太陡而难以走向大众,转身做 Dia 时却没有把浏览器再发明一遍,而是把最激进的部分压进少数几个入口里。Dia 在 2025 年 6 月以 beta 形式推出,TechCrunch 当时把它描述为一款把 AI 放在浏览器核心位置的新浏览器;同一篇报道也提到,Arc 没能触达足够大的用户规模,原因之一正是学习成本太高。1
这期拆 Dia,不是因为「AI 浏览器」这个词新,而是因为 Dia 做了一个克制的取舍:把浏览器外壳做得足够普通,把 AI 上下文入口做得足够明确。这比做一个满屏发光的 AI 工作台更难,也更值得拆。
巧思一:把学习成本花在 AI 上,而不是花在浏览器上
The Browser Company 自己给 Dia 的设计目标起过一个很日常的说法:让任何人都能在「周二上午 10 点」切到 Dia,而不用重新学习怎么上网。设计团队在文章里明确写到,Arc 曾经在标签栏、书签、标签组等核心浏览机制上大胆创新;Dia 则把这些基础功能放回多数浏览器用户一眼能认出的地方。2
这个选择有点反常识。做新浏览器的人通常想证明自己「不是 Chrome」。Dia 刻意不在第一屏证明这一点。普通标签、普通地址栏、普通书签栏先让用户放心:你没有被迫进入一套陌生操作系统。
Dia 把创新额度留给 Chat 和 Skills。The Browser Company 把这种额度称为「novelty budget」:用户愿意为新价值付出的学习努力是有限的,所以 Dia 不把这笔预算消耗在浏览器基本操作上,而是花在 AI 能读懂当前网页、标签页、历史、书签和工作上下文的地方。2
对产品设计来说,这里有一个可迁移的判断:当 AI 能力本身已经够陌生,外围容器就不一定也要陌生。Dia 没有把「熟悉」当成保守,而是把熟悉当成缓冲垫。用户先稳稳站住,再决定要不要把更多上下文交给 AI。
巧思二:不用神秘感包装上下文,而是让用户亲手把上下文点进来
Dia 的 URL 栏不只接收网址和搜索词,也承担内置 AI 聊天入口。TechCrunch 的上手报道提到,Dia 可以搜索网页、总结上传文件、在聊天和搜索之间自动切换;用户还可以询问所有已打开标签页里的内容,并让 Dia 基于这些标签页起草文档。1
问题在于,浏览器掌握的上下文太多了。当前网页、打开的十几个标签、历史记录、书签、文件、Slack、GSuite,都可能相关,也都可能不该被带进来。Dia 没有把这个问题完全丢给模型猜,而是做了一个很轻的显式动作:用 @ 提及标签页、历史、书签等对象。The Browser Company 在设计说明里说,这个行为借用了社交产品里「标记一个实体」的熟悉感;用户也可以从输入框左下角的菜单手动附加引用。2
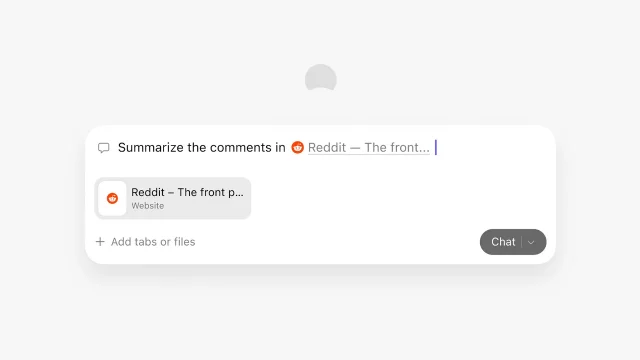
这一步很小,但改变了 AI 产品的责任关系。很多 AI 功能喜欢宣称「自动理解你的全部上下文」,听起来省事,实际会让用户担心:它到底看了什么?为什么得出这个回答?Dia 用 @ 把上下文变成一个可见对象,用户能看到自己把哪一页、哪段历史、哪份文件递给了 AI。
这里的巧思不在 @ 本身,而在它把模糊的「上下文感知」拆成了一个可操作的界面动作。AI 可以很聪明,但入口不必神秘。对产品经理和设计师来说,这比再加一个「使用当前上下文」开关更有启发:让上下文像附件一样被挑选、堆叠、检查,用户才更容易相信 AI 的回答来自哪里。
代价:上下文越顺手,边界越要被看见
Dia 的野心不止于当前标签。官网把它描述为能在 GSuite、Slack、标签页等完整工作上下文里寻找答案。3 Getting Started 页面也写到,浏览上下文、聊天和历史会被用于提供更好的回答,同时 Dia 默认避免存储和处理银行、健康等敏感网站的数据。4
这种设计的代价也很清楚:浏览器一旦变成 AI 的上下文层,隐私设置就不再是设置页里的后勤选项,而是产品体验的一部分。Dia 的隐私页写到,浏览数据会加密并存储在本机;当用户发起请求时,完成请求所需的数据会经由 Dia 服务器发送给受信任的 AI 合作方,合作方被限制不得用这些数据训练自己的模型。该页面还说明,默认用于改进速度和准确性的部分内容数据不会关联到账号,并会在 30 天后删除,用户也可以在隐私设置中停止分享。5
这说明 Dia 的设计并没有免费午餐。把 AI 放进浏览器,比把 AI 放进单个文档或单个聊天框更有用,也更敏感。Dia 的解法不是假装没有敏感性,而是在几个层面同时给边界:本地存储、敏感网站默认避让、显式引用上下文、隐私开关。用户未必会逐条阅读这些说明,但这些边界会决定他们敢不敢把浏览器交给 AI。
结尾:Dia 的聪明,在于没有急着显得聪明
Dia 给 AI 产品的启发不是「把聊天框放进主入口」。更准确地说,Dia 把 AI 产品拆成两层:底层是用户已经会用的旧动作,上层是少数几个需要重新学习的新动作。浏览器本体尽量像浏览器;上下文进入 AI 的那一刻,才出现更明确、更有表现力的交互。
这也是 Dia 和许多 AI 外挂工具的差别。AI 外挂工具经常要求用户把工作搬进它的空间;Dia 反过来,让 AI 待在用户本来就在用的浏览器里。用户不是被迫「进入 AI」,而是在需要时把某个标签页、某段历史、某个工作线索推到 AI 面前。
对设计 AI 产品的人来说,这个取舍很朴素:不要让用户同时学习新容器和新能力。先给他们一只熟悉的杯子,再倒进去一点真正不同的东西。

Añade más opiniones o contexto en torno a este contenido.