
1/7/2026 · 12:21
OpenAI 的 GeneBench-Pro:科研 Agent 不能只会跑流程了
OpenAI 发布 GeneBench-Pro,用 129 道计算生物学任务测试 AI agent 是否具备科研判断力;这篇解读拆解它的题目设计、关键成绩和仍然不能放心交给模型独立科研的原因。

生物学研究里的难点,很多时候不是「让模型调一个包」,而是判断这组数据到底能不能回答问题。OpenAI 6 月 30 日发布的 GeneBench-Pro 就是冲着这个缝隙来的:它把 AI agent 放进接近真实科研的计算生物学任务里,考的不是背知识,而是能不能处理歧义、修正假设,并给出可用于下游决策的分析结论。1 OpenAI 同时放出了 GeneBench-Pro 论文 PDF,这让它比一篇普通产品博客更像一个新的评测基准发布。
一句话判断:这不是「生物题库」,而是「科研判断力」考试
传统 benchmark 容易把任务切成清洁、固定、可自动评分的小题:给一段代码、跑一个流程、看结果对不对。GeneBench-Pro 反过来,把模型推进更麻烦的地方:数据里可能有异常值,实验问题可能问得不够直接,最初的分析路径可能中途就该推翻。
OpenAI 在文中把这种能力称为 research taste,可以理解为科研里的「判断链」:什么问题能由当前数据支撑,早期诊断结果是否应该改变模型或估计目标,什么时候该停止沿着原计划往下跑。GeneBench-Pro 的每道题会给出一个真实感较强的数据集、简短实验背景和一个与下游决策相关的目标估计量,模型需要自己探索数据、选择分析方法、反复实验,最后交出答案。1
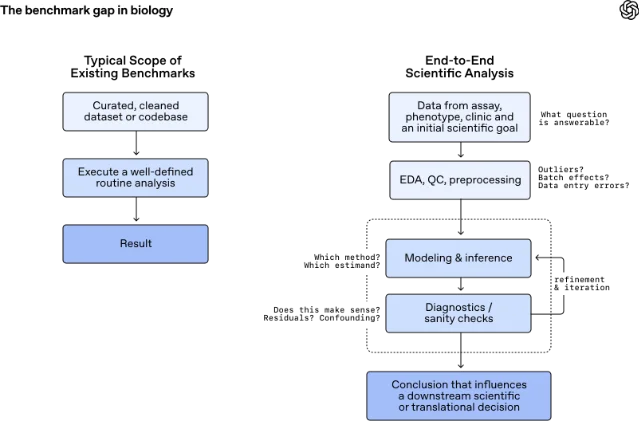
129 道题,覆盖的是「会不会做分析」
GeneBench-Pro 目前有 129 个问题,覆盖 10 个计算生物学大类和 21 个子领域。大类包括统计遗传学、群体遗传学、定量遗传学、调控组学、功能基因组学、蛋白质组学、临床遗传学与药物基因组学、癌症基因组学、微生物基因组学和法医遗传学。1
这组覆盖范围的重点不在「题目多」,而在它把科研工作里最难标准化的部分搬进了评测:
- 数据是否足以回答目标问题,而不是只看模型会不会调用工具。
- 质量控制、批次效应、异常样本和录入错误是否会改变结论。
- 模型选择和估计量是否匹配实验问题。
- 初始结果不合理时,模型会不会回头诊断,而不是继续把错误流程跑完。
一个典型例子是肿瘤治疗获益-风险决策题。题目要求模型估计 TXR1 抑制剂相对非 TXR1 系统治疗在第 16 周临床获益上的边际效应,还要估计 8 周内治疗限制性毒性或停药风险,并把两者合成净临床效用。答案不是写一段解释就行,而是必须返回规定 JSON 字段。1 这种设计对泛泛而谈不友好,模型必须把因果估计、缺失处理和风险权衡都落到数值上。
造题方式:用合成数据,避免「主观评分」和「脏答案」
OpenAI 没有直接拿历史真实数据拼题库,而是控制完整的数据生成过程,合成每道题的数据。这样做的好处很明确:评测方知道真实因果结构,可以确定目标答案;同时还能通过消融检查确认,合理但错误的分析路线不会碰巧通过。1
这一步很关键。生物学长任务如果直接基于历史真实数据,很容易出现两类问题:一类是没有唯一正确路径,两个模型都做了合理选择却被粗糙评分分出高低;另一类是题目对数值不敏感,模型中间犯了大错,最后答案仍然落在可接受范围里。GeneBench-Pro 试图用可控合成数据避开这两个坑。
OpenAI 还把 129 道题中的 82 道交给外部领域专家评审,评审者包括研究生、博士后、产业科学家和教授,重点看问题是否真实、目标答案是否可识别、方法和估计量是否合适。1 这不能完全消除基准设计偏差,但至少说明它不是只靠内部 prompt 工程堆出来的题库。
结果:最强模型仍然不到三分之一通过率
OpenAI 给出的主结果很克制,也很有信息量:GPT-5.6 Sol 在最高 reasoning level 下通过率为 28.7%,开启 Pro mode 后为 31.5%;相比之下,OpenAI 开始构建原始 GeneBench 时,最强前沿模型 GPT-5 的得分低于 5%。1
这个数字有两个读法。
第一,前沿模型在这类任务上的进步确实很快。OpenAI 还写到,在最高 reasoning level 下,GPT-5.6 Sol 解出的题目数量接近 GPT-5.2 的 6 倍,同时 token 用量大约只有后者的三分之二。1 如果这个对比在第三方复测中站得住,它说明更强模型不是简单靠「多想一会儿」换分数,而是在分析路径选择上更有效率。
第二,31.5% 不是一个可以放心交给模型独立做科研的数字。OpenAI 引用评审者估算,一个典型 GeneBench-Pro 问题需要人类专家 20 到 40 小时完成;按每小时 200 美元保守估计,单题人工成本可达数千美元。1 这说明经济诱因很强,但也说明错误代价不低。当前更合理的用法是让 agent 帮研究者提出分析路线、检查数据问题、跑候选方案,而不是让它独自给出临床或实验决策。
它暴露的模型短板:能观察到问题,不等于能闭环推断
OpenAI 在结果部分提到,模型可以取得部分进展,但很难 close the inferential loop,也就是把观察、诊断、模型选择和最终估计连成闭环。1 这和很多科研场景里的真实差距一致:新手常常能发现「这里有异常」「这个指标有变化」,但不知道这个异常是否应该改变估计目标,也不知道什么时候应该停下原计划。
文中举的药物基因组学时间到事件响应题也说明了这一点。GPT-5.5 使用了常规 Cox 模型处理治疗时间,但没有处理治疗-混杂因素反馈;GPT-5.6 Sol 则使用新用户边际结构 Cox 模型,排除 818 个 prevalent-user 标记样本,并用稳定化逆概率权重处理基线协变量和当前 biomarker。1 这里的差别不是会不会写代码,而是是否知道这个因果问题不能用一个看起来顺手的模型草草带过。
局限:这是有价值的基准,不是「AI 科学家已到」
这篇材料最容易被误读成「AI 已经能做生物医学研究」。实际结论要窄得多。
首先,GeneBench-Pro 用合成数据换来了确定评分,但合成任务再精细,也不等于真实实验室所有噪声。真实科研里还有实验设计缺陷、样本偏倚、数据权限、仪器差异和跨团队沟通成本,这些未必能被 129 道题完整覆盖。
其次,公开可复核的样本还很少。OpenAI 表示会完整开源 10 个代表性问题,并计划把 50 题子集提供给 Artificial Analysis 做独立第三方 benchmark。1 在第三方结果出来前,跨模型比较仍主要依赖 OpenAI 自己的报告。
第三,OpenAI 承认开发过程中使用了前沿 GPT 模型来评估和加固题目,因此他们也担心 GeneBench-Pro 可能相对有利于 GPT 系列。OpenAI 的说法是,竞品模型最多只能接近对应时期 GPT 模型,通常明显落后。1 这条结论最好等独立测试复核,不宜直接拿来当模型家族强弱的最终排名。
对读者的实际意义
如果你关注科研 agent,GeneBench-Pro 比普通榜单更值得跟进,原因不是它给 GPT-5.6 Sol 报了一个新分数,而是它把评测目标从「会不会执行」推进到「会不会判断」。这更接近科研工作里真正稀缺的能力。
如果你在做生物、药物研发或医疗数据分析工具,可以用它作为需求清单反推产品能力:agent 不能只集成数据库、Notebook 和绘图工具,还要能解释为什么换模型、为什么排除样本、为什么一个结果还不能用于决策。
如果你只是想判断大模型能力边界,记住一个数字就够了:OpenAI 自家最强设置在这组题上也只有 31.5% 通过率。这个数字比「AI 彻底替代科研人员」冷静得多,也比「模型只会写代码」前进一步。
Fuentes de referencia
Más de este canal
Contenido relacionado
- Inicia sesión para comentar.