
1/7/2026 · 17:20
Seedance 2.0:字节把视频生成推向可导演工作流
字节 Seed 的 Seedance 2.0 把文本、图片、音频、视频参考和剪辑指令纳入统一音视频生成流程。本文拆解它的多模态架构取向、复杂运动与声画同步能力、官方评测口径,以及进入真实制作工作流前仍要验证的限制。

Seedance 2.0 最值得拆的地方,不是它又能生成更长、更好看的视频,而是字节 Seed 把视频生成、参考素材、剪辑续写和音频同步放进了同一个模型接口里。官方博客把它称为「统一的多模态音视频联合生成架构」,支持文本、图片、音频、视频四类输入;官网产品页也把这条能力放在首屏说明。12
先校正一个时间点:这篇官方英文博客页面标注的发布日期是 2026-02-12,不是 2026-06。本文仍按用户指定材料解读,但事实时间以官方页面为准。1
一句话结论:它想从「生成片段」变成「接管制作指令」
Seedance 1.5 的关键词是同步音视频生成;Seedance 2.0 的关键词变成了多模态参考、可编辑、可续写。官方说法里,它可以同时接收最多 9 张图片、3 段视频、3 段音频,再叠加自然语言指令;模型会参考构图、运动、镜头、视觉效果和声音特征来生成结果。1
这意味着产品定位在变化。传统文生视频更像「给一句 prompt,赌一个片段」;Seedance 2.0 想做的是「把已有素材和导演意图合并成一个可执行任务」。如果它能稳定工作,创作者的输入不再只是文字,而是脚本、分镜、人物参考、场景参考、动作参考和音频参考的组合。
这里要克制一点:官方博客没有公开模型规模、训练数据、损失函数、推理成本,也没有给出可复现的架构图。所谓「统一架构」目前只能按官方披露理解为产品和训练范式层面的统一,不应扩写成某个具体网络结构已经被证明优于所有方案。
架构价值:多模态输入不再是补丁,而是主接口
博客把 Seedance 2.0 的能力拆成几类:文本生成视频、图生视频、参考生成、视频编辑、视频延展,以及带声音的视频输出。它们过去往往由不同工具链拼起来:先生成画面,再配音效,再剪辑,再补局部修改。Seedance 2.0 的卖点是把这些环节尽量压进同一个生成过程。1
这对视频模型很关键,因为视频创作里最难的不是「画面像不像」,而是素材之间是否能互相约束:人物外观要延续,镜头运动要连续,声音节奏要对上动作,上一段视频的结尾要能接住下一段。官方在结尾提到,Seedance 系列依赖稀疏架构的效率和多模态联合训练的泛化能力,目标是解决物理遵循和长期一致性问题。1
但它离「完整视频制作系统」还差一层证据。官方展示了参考素材驱动的 15 秒短片、视频续写和局部编辑例子,却没有披露长片段、多轮编辑、多人多物体连续出镜时的失败率。对真实团队来说,能生成一个漂亮 demo 和能承受反复修改,是两件事。
复杂运动:字节在攻「物理感」这道老题
官方最强调的是复杂运动和交互。博客举了双人花样滑冰、晾衣服、多人运动等例子,宣称模型在动作稳定性、物理还原、视觉真实感和可控性上比 1.5 版有明显提升,尤其适合多主体互动和复杂运动场景。1
这类场景正是视频生成模型容易露馅的地方:人物起跳和落地要符合重力,双人配合不能突然穿模,衣服和手部动作不能乱抖,镜头一切换主体不能换脸。官方用「figure skating」和「laundry」做例子,说明它在大幅动作和近景细节两头都想覆盖。
值得注意的是,博客用的是定性描述,没有给出公开样本集上的帧级错误率、身份一致性指标或物理违规统计。读者可以把这部分理解为官方能力主张,而不是已经被外部复现的结论。
可控性:真正有用的是「按素材和脚本办事」
Seedance 2.0 支持参考文本分镜、人物图、场景图、道具图来生成一个 15 秒短片;它还支持指定片段、人物、动作和剧情做修改,并能基于提示词继续延展视频。1
这比单纯提升清晰度更实用。内容团队最怕模型「有灵感但不听话」:画面漂亮,人物却不一致;镜头很炫,但剧情没按脚本走;声音有气氛,却和动作错位。Seedance 2.0 试图解决的就是这些制作层面的摩擦。
如果把它放到短剧、广告、解说视频或电商素材里看,最有价值的能力不是一次生成最终片,而是让非专业用户用参考素材控制生成边界。比如品牌广告可以固定产品外观和镜头语言,知识解说可以用脚本控制镜头节奏,个人创作者可以把已有片段继续往后拍。官方博客也明确提到商业广告、解释类视频等适配场景。1
音频:从配背景声,走向声画同步
这次发布里,音频不是附属功能。官方称 Seedance 2.0 引入双声道立体声技术,支持背景音乐、环境音效和角色配音的多轨并行输出,并与视觉节奏对齐。博客还展示了武侠打斗、ASMR 手部近景等提示词,强调雨声、兵器碰撞、玻璃摩擦、毛绒布料摩擦、气泡膜按压等细微拟音。1
视频生成模型要进入更高质量内容制作,声音会变成硬门槛。一个动作晚半拍、脚步声和画面不贴合、人物口型和台词脱节,都会让观众立刻出戏。Seedance 2.0 把音频作为模型生成目标的一部分,说明视频模型竞争已经不只是「画面分辨率」之争。
官方也留下了限制:音频仍可能出现失真,细节稳定性、超写实表现和动态生命力还要继续改进。1 这句话很重要,因为声音瑕疵往往比画面瑕疵更难靠后期快速修掉。
评测:图很好看,但要看清口径
官方称团队与专家共建了评测数据集和标准,覆盖音视频生成、参考生成和编辑,考察多模态参考生成、复杂音视频指令遵循、复杂运动稳定性、自然语言理解、音视频表现力和声画协同。1
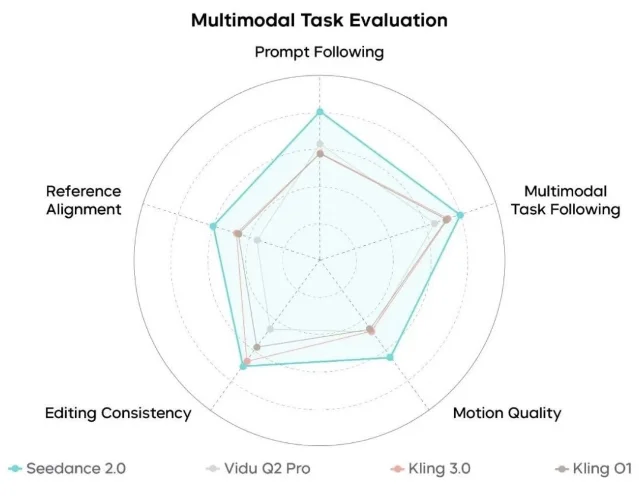
这张图能说明字节 Seed 想把竞争维度从单一文生视频扩到「参考 + 编辑 + 一致性」。但它不能单独证明 Seedance 2.0 在所有真实工作流中都领先。原因有三点:评测集没有公开,雷达图没有原始分数和置信区间,竞品版本和测试提示词也缺少可复核细节。
所以更稳妥的读法是:官方认为 Seedance 2.0 的优势在多模态任务闭环,而不是只在某个单点指标上冲高。真正的验证要等到更多用户在长脚本、多轮修改、品牌素材约束和中文音频场景里测试。
最值得跟进的三个问题
第一,Seedance 2.0 能不能把参考素材的一致性维持到更长时间。15 秒多镜头已经有制作价值,但广告、短剧和课程视频通常需要多段拼接。人物、服装、产品外观和空间关系能否跨段延续,会决定它能不能进入专业流程。
第二,编辑能力能不能经受多轮修改。官方说它支持定向修改片段、人物、动作和剧情,也支持视频延展。真正难的是用户改三轮之后,模型是否还能保住原来的主体、镜头和声音逻辑,而不是每改一次就把整段视频带偏。
第三,合规和授权会不会成为产品边界。官方在 demo 注释里说明,涉及人物参考的视频仅用于能力展示,参考主体要么由 AI 生成,要么已获得授权;如果用户想用真实人像做主体参考,需要身份验证或事先合法授权。1 对视频模型来说,这不是法律脚注,而是能否大规模商用的前置条件。
读者该怎么判断它的价值
如果你只关心单条短视频的视觉冲击,Seedance 2.0 的发布当然值得看。但更有信息量的变化在工作流:模型开始把文本、图片、视频、音频和剪辑指令当成同一个任务来处理。它要解决的不是「生成一个片段」,而是让用户把素材交给模型之后,还能继续导演、修改和延展。
短期内,最适合验证的是三类场景:有固定人物或产品的广告素材,有明确分镜的 15 秒短片,以及依赖环境声和动作同步的 ASMR / 运动 / 打斗场景。若这些场景能稳定通过,Seedance 2.0 对创作者的价值会比普通文生视频模型更高;若多轮编辑和长一致性仍然不稳,它就仍是一个强 demo 模型,而不是完整制作系统。
官方结论里承认,Seedance 2.0 仍有各种生成瑕疵,后续会继续探索大模型与人类反馈的深度对齐。1 这也给了一个清晰观察点:下一阶段的视频模型竞争,不只看谁的样片更炸,更要看谁能把错误率、可编辑性和授权流程降到创作者能承受的水平。
Añade más opiniones o contexto en torno a este contenido.