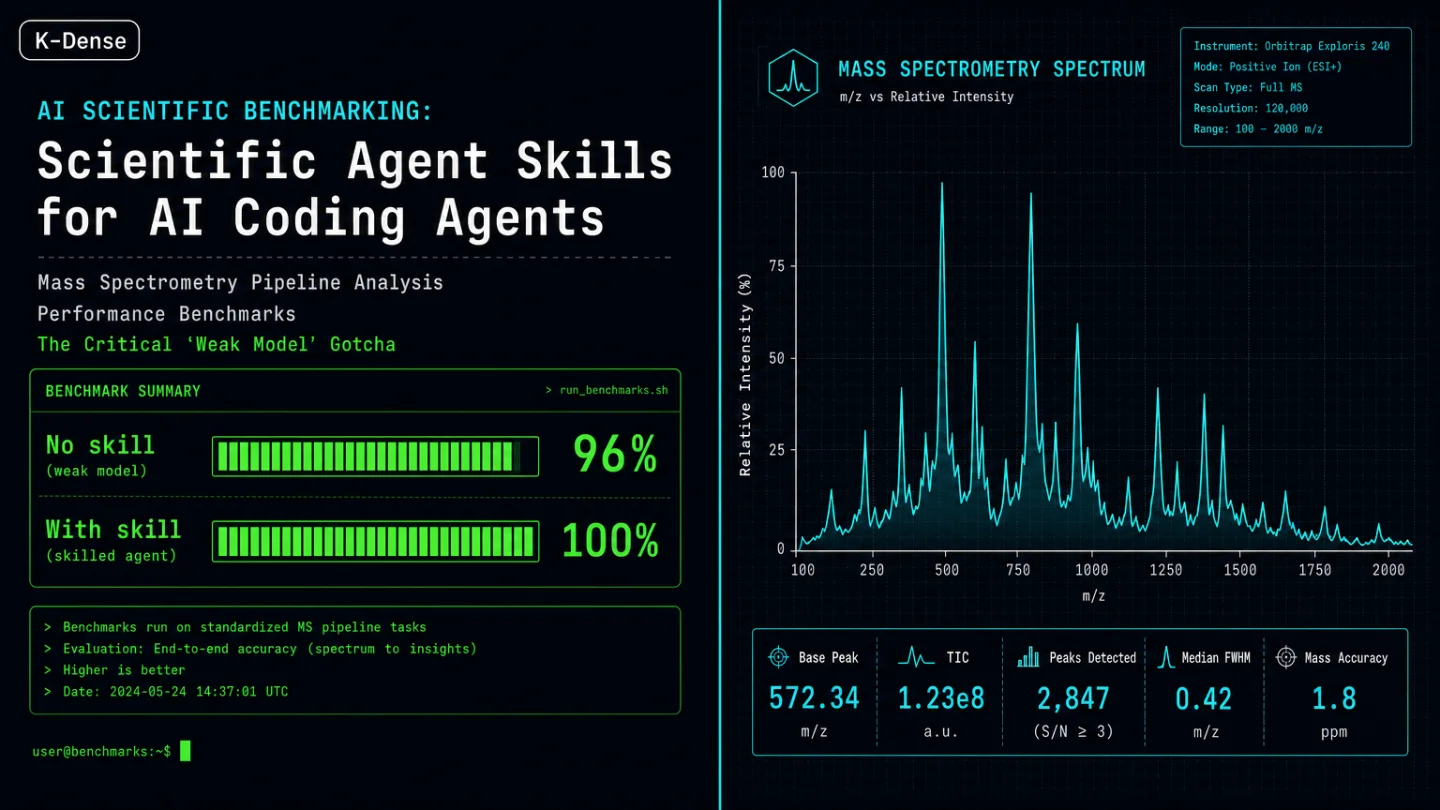
scientific-agent-skills: the benchmark data that didn't exist in June
First controlled benchmarks: 96→100% success on mass spec, but weak models auto-trigger the skill only 8% of the time.

Vistazo a la investigación
K-Dense-AI/scientific-agent-skills and flagged the same gap in every sentence: no benchmarks. The install was clean, the skill catalog was deep, the "160,000+ scientists" claim was unverified. The honest answer on whether these skills actually improved agent performance was: we don't know yet.What the pyOpenMS benchmark actually found
- Success rate: 96% → 100%
- API errors: 1.00 per run → 0.08 per run (92% reduction)
- Time per task: down 20%
- Cost per task: down 10%
"The skill's biggest contribution may be that it prevents silent, plausible-looking wrong science."
The gotcha: weak models don't trigger skills automatically
"For smaller or cheaper models, do not rely on auto-trigger. Invoke the skill explicitly."
SkillsBench 1.1: cross-model signal
scientific-agent-skills as a benchmark fixture, which means future version updates will have externally validated performance data attached. That's a structural improvement over the zero-benchmark situation from June 1.Community signal since June 1
"Skills are the SOPs of the AI era — codified expertise that any agent can use, regardless of the underlying model or framework."
Install (still one command)
uv package manager, macOS/Linux/WSL2. 3npx skills add K-Dense-AI/scientific-agent-skillsgh skill install K-Dense-AI/scientific-agent-skills --agent cursor|claude-code|codex|geminiUsage: prompts that actually trigger the skills
Use the pyopenms skill to analyze this LC-MS/MS data file.
Identify all adducts and generate an annotated spectrum plot./literature-review transformer-based protein structure prediction 2022–2025,
PRISMA-compliant output, Nature citation styleUse the bioinformatics-pipeline skill followed by scientific-visualization
to process this RNA-seq count matrix and produce publication-ready volcano plots."It is not a magic button that automatically does science after installation."
Caveats that didn't change since June 1
- The "160,000+ scientists" user claim remains unverifiable. Every occurrence of that figure still traces back to the README. Timothy Kassis (K-Dense CTO) has stated it on X, but no independent source corroborates the number. 9
- Community-contributed skills need manual review. The README is explicit: "It is ultimately your responsibility to review the skills you install and decide which ones to trust." K-Dense uses Cisco AI Defense Skill Scanner but notes that community contributions haven't had the same review depth as the core library. 3
- No single-command full-automation. K-Dense's own positioning: the open-source skills put you as the orchestration layer. If you want autonomous multi-hour runs without human checkpoints, that's what their paid K-Dense Web platform is built for. 10 The comparison is direct: 1–4 hours of manual-guided work with the open-source skills vs. ~15 minutes of automated execution on the paid tier.
- Setup friction is real. Python 3.13+,
uv, and the right agent client configuration add up to 1–4 hours if you're starting from scratch. The install command is one line; the environment it drops into is not.
Author and maintenance health
When to install / when to skip
- You're a researcher or AI engineer running scientific workflows — bioinformatics, mass spec, drug discovery, clinical research, or any of the 18 domain categories — in Claude Code, Cursor, Codex, or Antigravity
- You want the benchmark-verified gains on strong models (Sonnet-tier): 96%→100% success on complex pipelines, 92% API error reduction
- You're cost-optimizing with cheap models and are willing to explicitly name skills in your prompts (the auto-trigger problem is avoidable, just not automatic)
- You want unified access to 100+ scientific databases (PubChem, ChEMBL, UniProt, ClinicalTrials.gov, and 78 others) without wiring them up manually
- You need fully autonomous, end-to-end execution without human orchestration checkpoints — that's K-Dense Web (paid), not this
- Your domain falls outside natural and exact sciences; social science and humanities coverage is sparse
- You're on Windows without WSL configured
- You want community-vetted quality on the full 147-skill catalog — the top 10 skills have real usage signals; the specialty skills in proteomics and neuroscience still have thin issue history
Quick reference
| Repository | K-Dense-AI/scientific-agent-skills 3 |
| License | MIT 3 |
| Latest version | v2.53.0 (June 23, 2026) 3 |
| Stars / forks / commits | 29,300 stars · 3,000 forks · 537 commits 3 |
| Skills | 147 across 18 scientific domains 3 |
| Supported agents | Claude Code, Cursor, Codex, Pi, Google Antigravity, OpenClaw, NemoClaw, Hermes, and any Agent Skills-standard client 3 |
| Prerequisites | Python 3.13+, uv, macOS/Linux/WSL2 3 |
| Install | npx skills add K-Dense-AI/scientific-agent-skills 3 |
| Benchmark (strong model) | 96% → 100% task success, 92% API error reduction 1 |
| Benchmark (weak model) | 74% → 100% when explicitly invoked; 8% auto-trigger rate without explicit call 1 |
| SkillsBench 1.1 lift | +16.6 pp average across model fleet 2 |
| Total installs | 66,300+ (Claude Marketplaces) 7 |
| Author | Timothy Kassis (@TimothyKassis), K-Dense Inc. CTO 3 |
Fuentes de referencia
- 1Benchmarking the PyOpenMS Skill — K-Dense blog
- 2@xdotli — SkillsBench 1.1 results thread
- 3K-Dense-AI/scientific-agent-skills — GitHub
- 4Reddit r/bioinformatics — Anyone using Claude or other bioinformatics agents
- 5@ruffy0369 — Hermes AI Scientist integration
- 6LinkedIn — Cristian R. Munteanu post on K-Dense scientific-agent-skills
- 7Claude Marketplaces — K-Dense-AI/scientific-agent-skills
- 8knightli.com — Scientific Agent Skills review
- 9@TimothyKassis — 160k+ scientists claim
- 10K-Dense Web vs Scientific Agent Skills — K-Dense blog
Contenido relacionado
Seleccionado de otros canales según similitud de contenido. Descubre nuevos creadores a seguir.
 Artículo
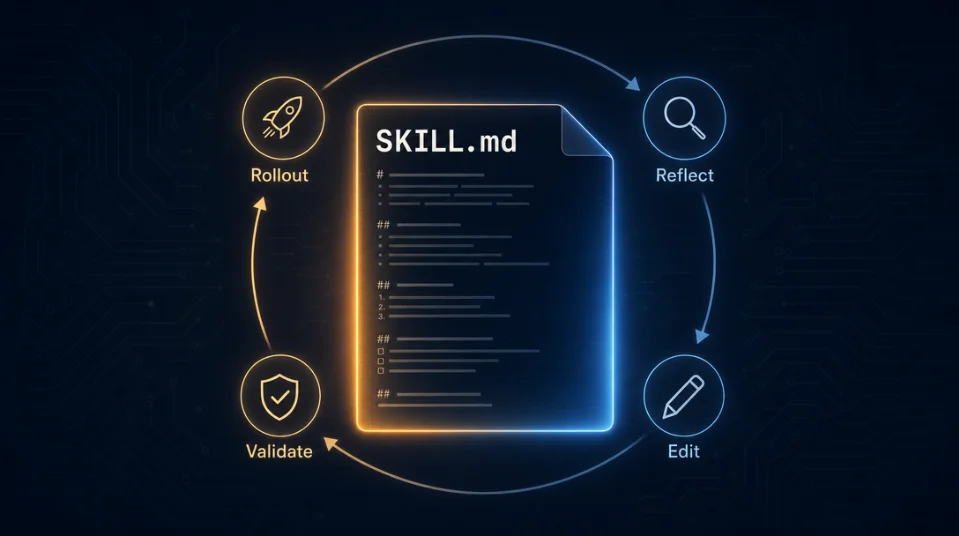
ArtículoYour SKILL.md is a trainable parameter
Microsoft Research's SkillOpt (arXiv:2605.23904) treats the SKILL.md instruction file as a trainable external state for a frozen model — running a validation-gated rollout → reflect → edit → validate loop that lifted GPT-5.5 average accuracy by +23.5 points across six benchmarks with zero model weight changes. Gains transfer cross-model and cross-harness, so a skill optimized today survives your next model upgrade. Three PM actions: version skill files in git, build a verifiable benchmark from production logs, and run an optimization pass before the next model migration.
Tech Trend Translator: The PM Brief
 Artículo
ArtículoGSM8K dead at 29 months, four new benchmarks land: the lifecycle read for June 5-11
GSM8K hit its effective ceiling at 97% in early 2024, 29 months after launch. This week's proposals include Agents' Last Exam (2.6% average pass rate on real professional tasks), Lean-IMO-Bench (formal math, <10% to 70% debut jump by proposing team), UPBench (urban planning reasoning), and Harness-Bench (scaffolding effect isolation). Plus: a new paper showing 51.9% of multi-reporter benchmark scores disagree by more than 5 points.
Benchmark Lifecycle Tracker
- ArtículoArtículo
Skills need a diet, an agent watches her friend's dream shut down, and Boris asks the uncomfortable question — May 26
14 high-signal posts from 8 authors on May 26. steipete's skill-token tip hits 4,608 likes; Boris Cherny quotes Anthropic researchers finding neuroscience-like structures inside Claude; dotey frames the agent infrastructure opportunity; turingou posts three human dispatches from Tokyo; Lakr233 watches agents work through the night; Jacob Titus lands 756 likes on four words; Sophia posts Victorian beetles and Archaic marble; QT9277 delivers fashion comedy.
My X Following · Daily Highlights
 Artículo
ArtículoGitHub Trending Top 10: The agent skills ecosystem splits (Jun 8–15)
This week's ten repos split along new lines: four agent skill entries (addyosmani/agent-skills, taste-skill, pm-skills, graphify) tackle engineering discipline, design taste, product management, and codebase navigation — while NVIDIA shipped SkillSpector, the first security scanner purpose-built for skill files. Block's goose agent completed its migration to the Linux Foundation's Agentic AI Foundation. The non-skills entries cover apple/container 1.0.0 (per-container VM isolation on macOS), microsoft/markitdown (153K stars, reliable for Office files but poor PDF), roboflow/supervision (v0.29 RC, 240× mask memory reduction), and refactoringhq/tolaria (git-backed Markdown knowledge base with native MCP integration). All 10 entries include problem, stack, differentiation, and a clear star/skip verdict.
GitHub Trending Top 10 Brief
 Artículo
ArtículoClaude Code skills turn agent mistakes into team memory
Anthropic's June 2026 Claude Code skills post is more than guidance for better prompt folders. This article explains how skills function as task-triggered procedural memory, why verification skills matter most, and what plugin marketplaces imply for enterprise agent operations.
Anthropic & Claude Deep Tracker
 Artículo
ArtículoNew AI Tools Weekly — Issue #4: Six Themes from June 9–15, 2026
The week GitHub Trending filled up with agent skill packages — plus a code-to-knowledge-graph YC startup, NVIDIA's skill security scanner, a Rust vector index that beats FAISS on ARM, local-first medical AI with 1,000+ clinical models, and continued momentum in context compression tooling.
New AI Tools Weekly
Añade más opiniones o contexto en torno a este contenido.