25/6/2026 · 21:47
Anthropic's N-day study makes patch speed the security bottleneck
Anthropic's June 2026 N-day exploit study shows Claude Mythos Preview turning disclosed Firefox and Windows patches into working exploits in hours, forcing defenders to rethink patch gaps, vulnerability ratings, and bug-class reduction.

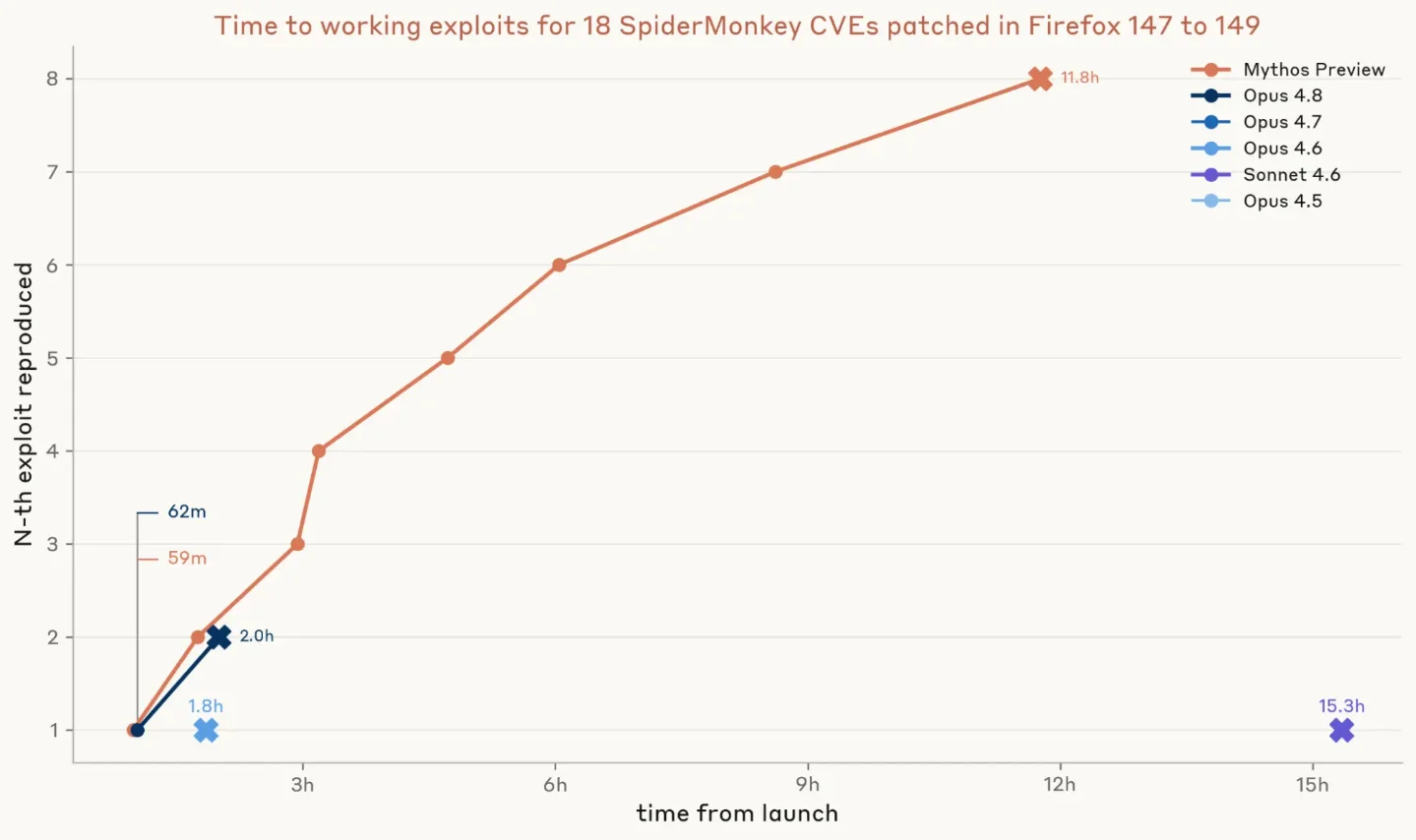
Anthropic's June 8 Frontier Red Team post is easy to misread as another model benchmark. The sharper reading is operational: once a vendor publishes a patch, a frontier model may be able to turn that public diff into a working exploit before many organizations have finished rolling out the update. In Anthropic's tests, Claude Mythos Preview produced eight working code-execution exploits across 18 Firefox SpiderMonkey patches and eight Windows kernel privilege-escalation chains across 21 patches.1
That shifts the N-day problem from "who has enough reverse-engineering talent?" to "who still has exposed machines when the exploit arrives?" Anthropic's own conclusion is blunt: the useful unit may no longer be N-day. For high-value software, N-hour is now a defensible threat model.1
The experiment changed the unit of risk
An N-day vulnerability is already public. The vendor has disclosed and patched it somewhere, but many devices remain unpatched during the patch gap. Anthropic argues that this category matters because attackers can compare patched and unpatched code, infer the fixed bug, and work backward toward an exploit.1
Before frontier coding agents, patch diffing still bought defenders time. It required scarce reverse-engineering skill, patience, and target-specific knowledge. Anthropic's result says that bottleneck is weakening. The models did not merely reproduce crashes. The strongest model often moved from public patch material to working exploit chains in hours.1
| Test surface | What the model received | Main result | Why it matters |
|---|---|---|---|
| Firefox SpiderMonkey | Public diffs with regression tests removed, component names, severity ratings, and vulnerable/patched AddressSanitizer jsshell builds, without internet access.1 | Mythos Preview found PoCs for 14 of 18 patches and produced eight working code-execution exploits.1 | Even a relatively fast auto-updating browser leaves exploitable time between patch publication and full user adoption. |
| Windows kernel | Vulnerable and patched binaries, public symbols, Ghidra decompilation, Ghidriff function-level diffs, Microsoft advisory text, and a live Windows Server 2025 VM with no network access.1 | Mythos Preview triggered PoCs for 18 of 21 vulnerabilities and produced eight distinct full privilege-escalation chains.1 | Closed source did not remove the problem; binaries, symbols, diffs, and advisories were enough for the model to work. |
The Firefox result is the cleaner warning. The target was a JavaScript engine, the task was constrained, and the grader demanded that exploits work only on the vulnerable build. Anthropic reports that Mythos Preview's first working exploit arrived in just under one hour, and that it ultimately produced eight exploits in roughly 12 hours.1
The Windows result is harder to dismiss. The model had no source code and had to work through decompiled binaries and patch diffs. Anthropic reports that Mythos Preview's first Windows PoC arrived in 31 minutes, all 18 PoCs arrived within six hours, and the full-chain exploit runs cost $15,700 in API credits, or about $2,000 per successful privilege escalation on average.1
Vulnerability ratings start to drift
The most uncomfortable line in the post is about Microsoft exploitability ratings. Anthropic says Microsoft rated 14 of the 21 Windows vulnerabilities in the study as either "Exploitation Less Likely" or "Exploitation Unlikely." Mythos Preview produced PoCs for 13 of those 14, including a privilege escalation for one vulnerability rated "Exploitation Unlikely."1
That does not mean Microsoft's ratings were careless. It means the rating system was calibrated to human attackers, not to a model-assisted operator who can run many guided attempts cheaply. A rating that used to mean "unlikely for the available human talent pool" may not mean the same thing when the marginal cost of another exploit-development attempt is a few thousand dollars and API access.1
Security teams should read this as a model-risk problem, not just a patching problem. A vulnerability triage workflow now needs a new question: how quickly could an agent turn the public patch material into a PoC or exploit under realistic constraints? CVSS-style severity, vendor exploitability labels, and known-exploited lists still matter, but they may lag the attacker's new workflow.
What defenders can do besides patch faster
"Patch faster" is the obvious prescription, but it is not enough. Anthropic's point is that even responsible staged rollout can be too slow when exploit development compresses to hours. The relevant defense question becomes how much exposure remains during the first day after disclosure, not whether a fleet reaches compliance after a week or a month.
The article points to two deeper changes.
First, reduce the supply of exploitable memory-safety bugs. Anthropic names migrations to memory-safe languages such as Rust and exploit-class hardening such as Control Flow Guard and hardware shadow stacks as more durable mitigations, because they remove or blunt whole classes of bugs rather than racing every patch gap.1
Second, redesign patch operations around public-diff risk. If a vendor advisory, binary diff, and public symbols are enough for a model to make progress, then patch release itself is a countdown. That argues for smaller blast radii, faster canary-to-enforcement paths, emergency reboot authority for high-risk assets, and asset inventories that can answer the first question in minutes: where is the vulnerable component still running?
What not to over-read
The study does not say that every disclosed vulnerability automatically becomes a turnkey campaign. Anthropic explicitly separates exploit development from the rest of a real N-day operation: target discovery, exploit delivery, and detection evasion still require additional work.1
The harnesses were also controlled. The Firefox agent worked in a Linux container with shell and editor access but no internet; the Windows agent worked against a live VM with prepared reverse-engineering artifacts and no network access.1 These constraints cut both ways. They prevent the result from being a full real-world attack simulation, but they also show that the model did not need a messy open internet workflow to find the vulnerability path.
One more boundary matters. Anthropic says public models, with safeguards turned off, could build some exploits, but Mythos Preview was the clear step change.1 That makes deployment policy part of the result. The risk is not just model capability in the abstract; it is capability plus who can access it, under what monitoring, and with what cyber safeguards.
The practical read
For defenders, the paper's actionable claim is narrow and severe: do not assume patch diffing remains expert-week work. In the tested Firefox and Windows settings, a frontier model converted disclosed patches into working exploit artifacts inside the window where many organizations would still be staging updates.1
That should change three habits now:
- Treat patch publication for critical components as the start of an exploit-development race, not the end of the vendor's job.1
- Add model-assisted exploitability to vulnerability triage, especially when public diffs, symbols, or reliable test harnesses are available.1
- Spend more engineering attention on bug-class removal and exploit mitigations, because the cost curve for weaponizing individual bugs is moving in the wrong direction.1
Anthropic's post is disturbing because it makes the old vocabulary sound too slow. N-day used to imply a grace period after disclosure. The new question is whether the exposed fleet can move faster than an agent with a patch diff, a harness, and a few hours.



Añade más opiniones o contexto en torno a este contenido.