1/5
28/6/2026 · 12:20
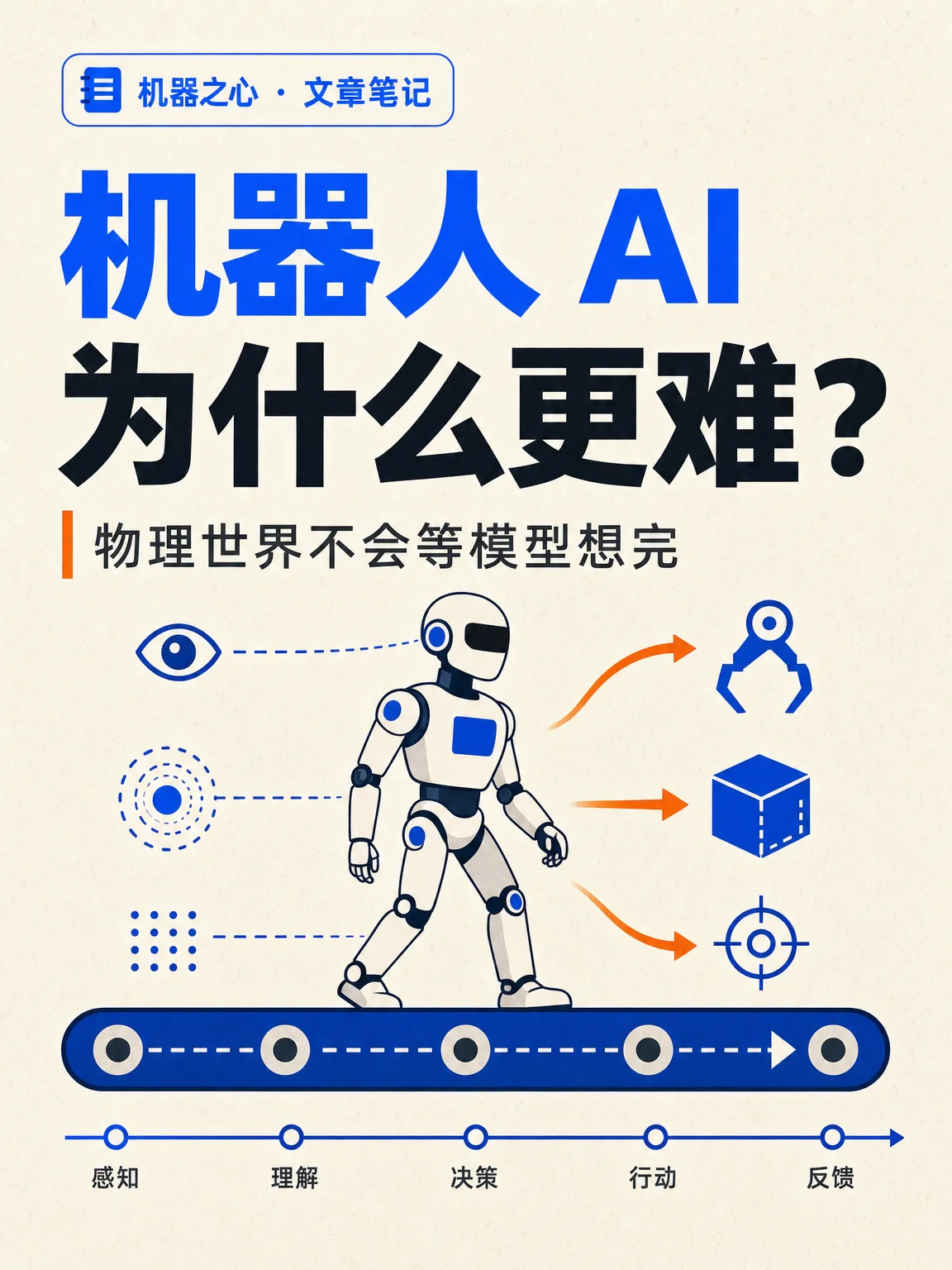
机器人 AI 为什么更难?
机器之心文章图片笔记:从控制函数、VLA 双系统、动作分块、实时延迟和数据瓶颈,快速看懂机器人 AI 难在哪里。

原文:机器之心《从第一性原理看机器人 AI:为什么它比大模型更难?》,发布时间:2026-06-28 11:00。
这套 5 张图片笔记,按「控制函数 → 双系统架构 → 动作分块 → 实时延迟 → 数据瓶颈」拆解机器人 AI 难在哪里。
核心笔记
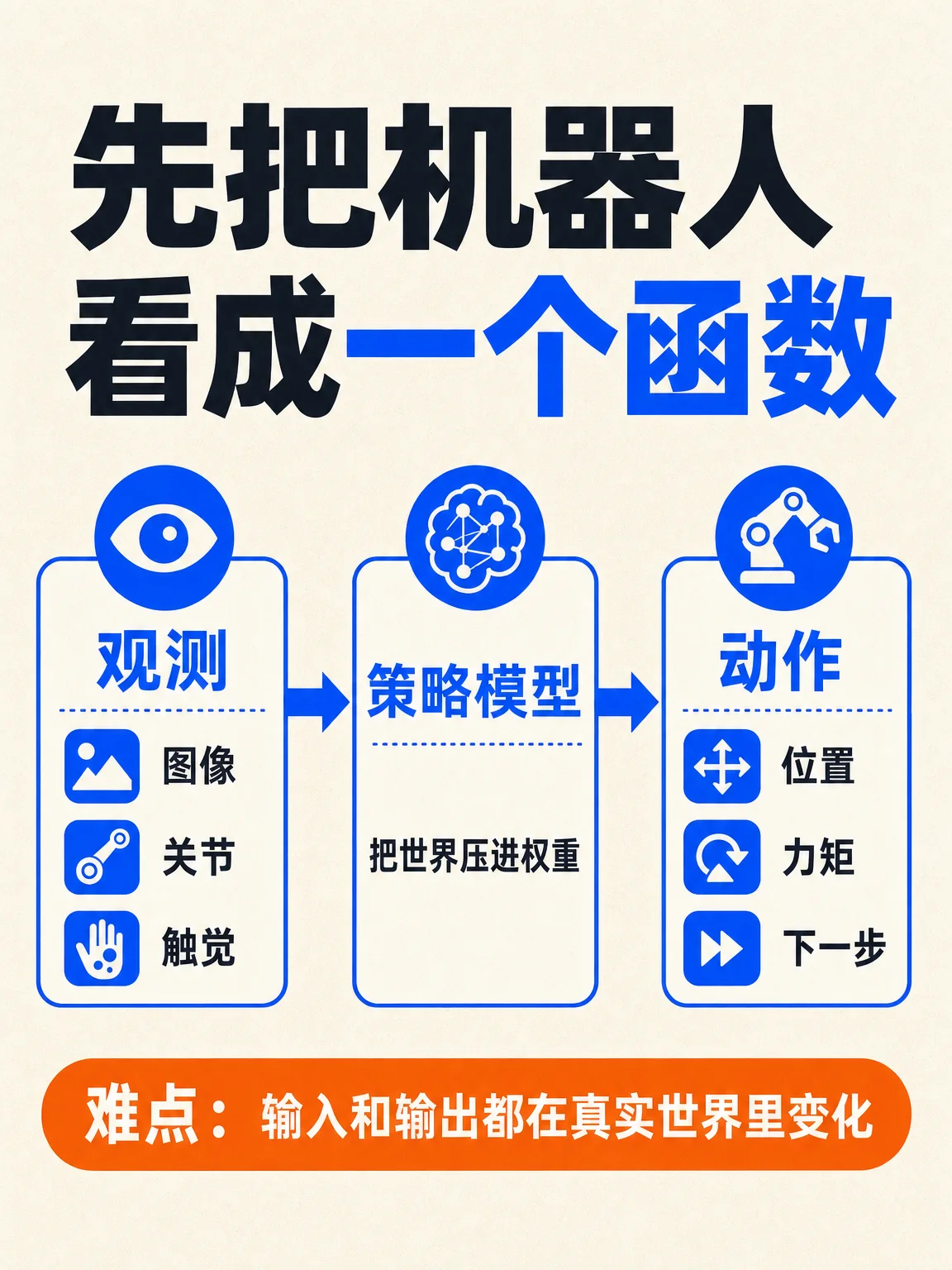
- 机器人控制可以先看成一个函数:输入摄像头像素、关节角度、触觉/阻力等观测,输出电机位置、力矩或下一步动作。难点在于输入和输出都会跟着真实世界实时变化。1
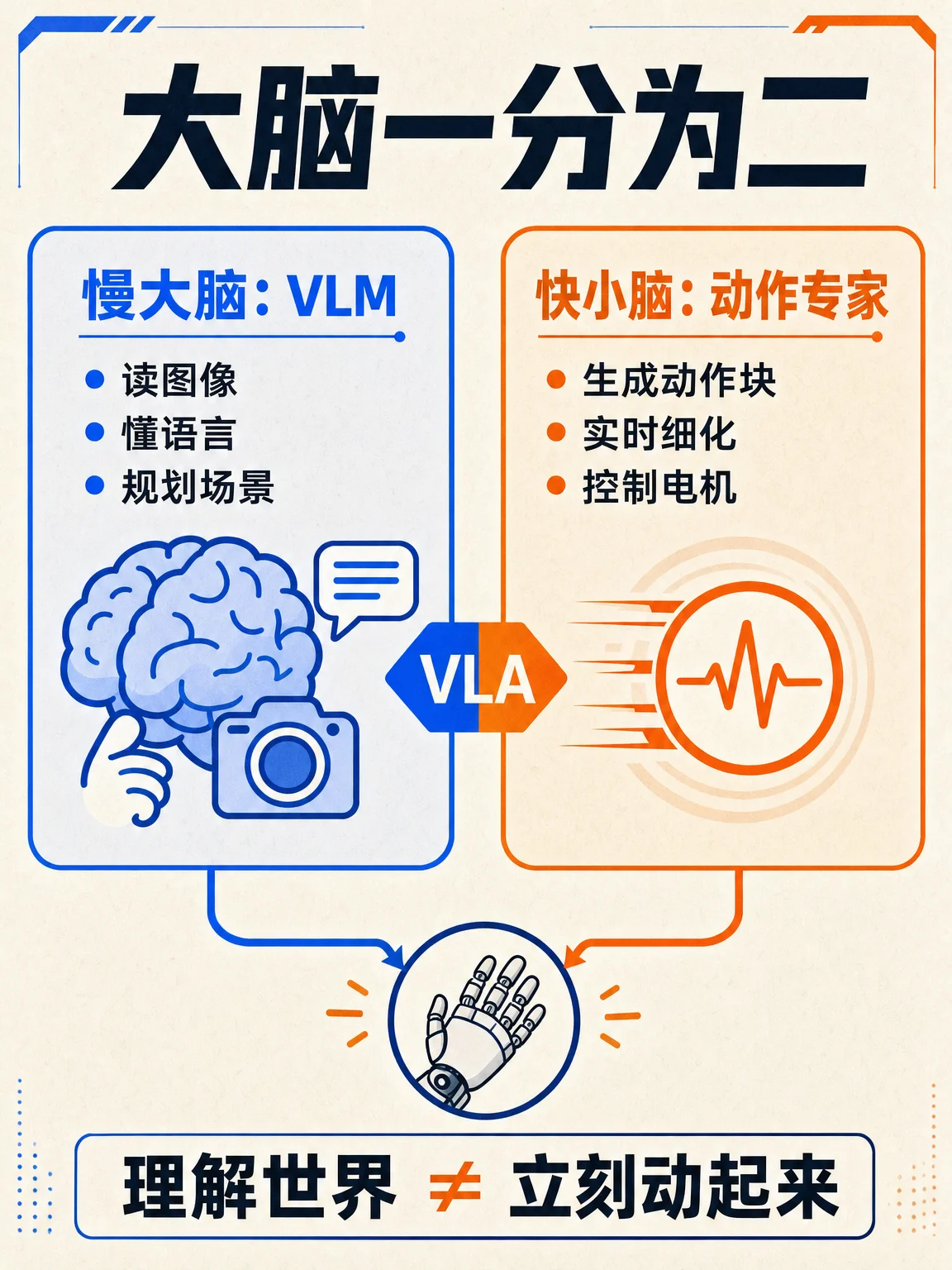
- 现代机器人模型常拆成「慢大脑 + 快小脑」:VLM 负责理解图像、语言和场景,动作专家负责把理解结果细化成可执行的控制指令,代表方向包括 NVIDIA GR00T N1 和 Physical Intelligence π₀。1
- 动作生成不再只做「一步一步预测」。ACT 动作分块一次预测一小段未来动作,原文称这种做法能减少误差累积,并在精细任务中用约 10 分钟示教数据达到 80%–90% 成功率。1
- 延迟是机器人 AI 的硬约束。原文举例称,π₀.₅ 在高端 GPU 上完成一次感知—动作循环约 274ms,而 3Hz 控制循环的边缘设备单周期约 330ms,留给模型的余量非常窄。1
- 数据瓶颈不是「再爬一点互联网」就能解决。原文把路径分成遥操作、仿真/世界模型、第一视角视频、人在回路纠错和部署中学习等方向,并提到 Ego4D 3000+ 小时第一视角视频与 GR00T 混入合成数据后性能提升 40% 的说法。1
图片顺序
- 机器人 AI 为什么更难:物理世界不会等模型想完。
- 控制函数:观测进来,动作出去。
- VLA 双系统:慢大脑理解世界,快小脑立刻动起来。
- 动作分块与延迟:一次预测一段动作,但实时周期仍很紧。
- 数据瓶颈:机器人数据是群岛,部署训练才跨过演示鸿沟。
Comentar
Inicia sesión para comentar.