
Five diffusion papers worth reading: June 16, 2026
Tuesday's normal daily batch (254 cs.CV + 201 cs.LG) yields five papers: NTU's parameter-free Spectral Forcing cuts FID 14.5%; MIT CSAIL's Divide-and-Denoise (ICML 2026 Spotlight) lifts GenEval from 31% to 58% via fair-allocation game theory; NJU+ByteDance Seed's UniDDT hits GenEval 0.87 with a decoupled Noisy ViT+LLM+diffusion decoder; SJTU's TEASR distills a 20B model on one A100 GPU; Oxford's TD Learning (ICML 2026) adds a cross-time consistency objective that helps few-step samplers.

研究速览
Tuesday's batch ran 254 cs.CV and 201 cs.LG new submissions. About 50 matched "diffusion model" in one form or another. Five made the cut: two ICML 2026 acceptances, three open-source releases, and one distillation result that makes a 20-billion-parameter image restoration model trainable on a single A100.
Speed-read table
| Paper | arXiv | Institution | Core method | Key number | Code / demo |
|---|---|---|---|---|---|
| Spectral Forcing | 2606.15236 | NTU S-Lab (Ziwei Liu group) | Parameter-free time-varying 2D-DCT low-pass mask before patch embedder | FID 24.19 → 20.68 (−14.5%) on ImageNet-256 in 60 epochs | GitHub · HF models |
| Divide-and-Denoise | 2606.14756 | MIT CSAIL + Aalto (Jaakkola, Kaski) | Fair-allocation game coordinates multiple pre-trained diffusion models at sampling time | GenEval best among tested composition methods | — (ICML 2026 Spotlight) |
| UniDDT | 2606.16255 | Nanjing U + ByteDance Seed + HKU | Noisy ViT encoder + LLM + diffusion decoder; decoupled generation and text decoding | GenEval 0.87, MME 1699.5 | GitHub |
| TEASR | 2606.16188 | Shanghai Jiao Tong University | Self-adversarial distillation within a single model; decoupled timestep conditioning | 1-step LPIPS 0.2542 on RealSR, PSNR 28.54 on DRealSR | — |
| TD Learning for diffusion | 2606.15048 | Oxford (Prisacariu group) | Markov reward process reformulation; cross-time consistency TD objective | FID improves across DDPM, EDM, Consistency Training with strongest gain at low NFE | GitHub |
1. Spectral Forcing: a parameter-free frequency prior cuts ImageNet FID by 14.5%
arXiv: 2606.15236 | Weichen Fan, Fan Wang, Yuncong Yang, Kaicheng Yu, Ziwei Liu (NTU S-Lab; 5 authors) | cs.CV
Peer-review status: Preprint. GitHub and HuggingFace model weights public.
The starting observation: under rectified flow, a natural image's power spectrum follows P(k) ∝ k^{−α}, which implies a per-frequency-band data-to-noise ratio profile k*(t) = (1−t)^{−2/α}. That profile traces a boundary in the (frequency, timestep) plane — below the curve, signal dominates; above it, noise dominates. A standard denoiser has to discover this boundary internally, and in the noise-dominated region its optimal prediction collapses to a deterministic baseline. The model wastes capacity learning a fixed answer. 1
Spectral Forcing replaces that implicit learning with an explicit time-varying 2D-DCT low-pass mask applied to the noisy input before the patch embedder. The cutoff frequency c(t) expands monotonically as t decreases toward clean data, becoming an identity map at t = 1. No new parameters, no changes to the forward process, loss, EMA, sampler, or classifier-free guidance. 2
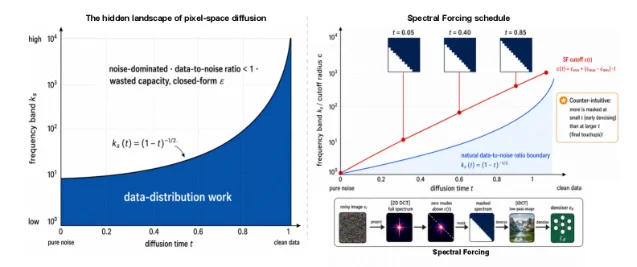
On ImageNet-256 at the JiT-700M/32 configuration (64 tokens per patch), 60 training epochs: FID drops from 24.19 to 20.68 (−14.5%); Inception Score rises from 83.28 to 93.96 (+13%). Running the same backbone to 120 epochs yields FID 15.15 versus the baseline's 16.46, matching a published ~145-epoch reference point at two-thirds of the compute. 2 The method transfers: applied to SenseNova-U1, a native VLM-based text-to-image model, Spectral Forcing wins 9 of 13 DPG-Bench sub-categories. 1
The authors note the gains are largest under coarse patch tokenization (64-token configurations) and when high-frequency image content is primarily noise rather than signal. Decoder-only transformers with fine tokenization see smaller benefits — the constraint region is narrower. 2
Why read it: The method is genuinely zero-cost to integrate — no architecture change, no extra memory, no additional hyperparameter sweep required. The theoretical justification (the data-to-noise ratio profile directly implies a capacity allocation problem) is clean enough to be useful as a lens for diagnosing other frequency-related inefficiencies in pixel-space diffusion training.
2. Divide-and-Denoise: MIT CSAIL uses fair-allocation game theory to compose diffusion models (ICML 2026 Spotlight)
arXiv: 2606.14756 | Abhi Gupta, Tommi Jaakkola, Samuel Kaski (MIT CSAIL + Aalto University; 3 authors) | cs.LG / cs.CV
Peer-review status: ICML 2026 Spotlight (top acceptance tier). No public code at time of writing.
The coordination problem: you have two or more pre-trained single-concept diffusion models (one trained on dogs, one on cats) and want to sample a composite image containing both. Existing methods treat this as density combination — multiply the distributions, apply logical AND, or average the score functions. These approaches fail when models compete for the same spatial regions: the result is either incoherent overlap or one concept dominating and the other disappearing. 3
Divide-and-Denoise frames the problem as a repeated fair-allocation game. At each sampling timestep, the algorithm runs two coupled steps: (i) a division step that solves for an allocation Q — a soft spatial assignment of image regions to each model, maximizing total utility subject to proportional fairness (each model gets at least 1/n of its available utility); (ii) a composite denoising step where each model denoises only its assigned region. A fictitious player with uniform utility over all features is added to each game to prevent any real model from being entirely squeezed out of low-utility regions. 4
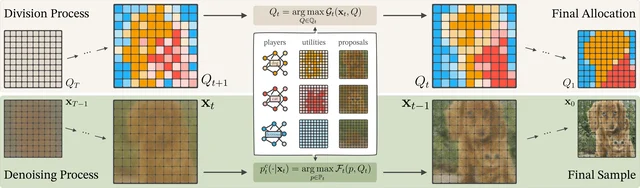
Two utility functions cover different settings: a score-based utility (works with any conditional diffusion model via CFG score differences) and an attention-based utility (requires cross-attention layers, more stable in practice). Experiments use Stable Diffusion 2.0 with attention-based utility and DiT with score-based utility. On the Stable Diffusion 2-model GenEval evaluation, Divide-and-Denoise with proportional fairness reaches 58.00% %images and 93% %prompts correctly rendered; the Averaging baseline scores 31.25%/%images and 59% %prompts, and MultiDiffusion scores 36.50%/67% — both well below. At 3 models, Divide-and-Denoise achieves 48.5% %images versus 14.0–14.8% for baselines. 4
Why read it: The game-theoretic formalization of model coordination is the transferable idea. The proportional fairness constraint — each participating model gets at least 1/n of its utility — gives a principled answer to "how much image area should each concept occupy?" that product-of-densities approaches lack entirely. The ICML Spotlight recognition reflects that the theory is cleaner than previous composition work, not just the empirical results.
3. UniDDT: Nanjing U + ByteDance Seed unify multimodal understanding and generation with GenEval 0.87
arXiv: 2606.16255 | Shuai Wang, Liang Li, Yao Teng, et al. (Nanjing University / ByteDance Seed / HKU; 12 authors) | cs.CV
Peer-review status: Preprint. GitHub open-source (CC BY 4.0). HuggingFace paper page active.
The core tension in unified multimodal models: understanding benefits from high-dimensional semantic representations, while generation in such spaces is typically slow to train and unstable. Most existing designs either compromise one objective for the other, or require task-specific data that ignores the natural duality between generating and describing an image from the same text. 5
UniDDT addresses this with a three-component architecture: a Noisy ViT encoder, an LLM backbone, and a diffusion decoder with decoupled roles. The Noisy ViT (evolved from the DDT architecture) takes a noisy image as input and injects timestep conditioning via AdaLN-zero, unifying semantic feature extraction and noisy visual encoding in one pass. An LLM backbone — Qwen3-0.6B, 1.7B, or Qwen3-VL-4B — causally encodes those visual tokens, then passes the refined representations to a diffusion decoder that operates entirely in latent space, conditioning on visual features only (no text tokens enter the decoder). 6
Training proceeds in three stages: separate warmup for the Noisy ViT and diffusion decoder; joint training that exploits the generate/describe duality on the same image-text pairs (the same data produces a "generate" format for text-to-image and a "describe" format for image captioning); then post-training where the understanding components are frozen and only the diffusion decoder is fine-tuned. 6

Results for VLM-UniDDT (Qwen3-VL-4B backbone, ~70M training images): 6
| Benchmark | UniDDT | Show-o2 | Janus-Pro-7B | BAGEL |
|---|---|---|---|---|
| GenEval ↑ | 0.87 | 0.76 | 0.80 | — |
| DPG-Bench ↑ | 86.9 | — | — | — |
| MME ↑ | 1699.5 | 1620.5 | — | 1687.0 |
| SEEDbench ↑ | 76.5 | — | — | — |
The key design decision is routing only visual features (not text tokens) into the diffusion decoder. The authors argue this prevents text decoding dynamics from interfering with diffusion decoding dynamics, which operate on different temporal scales and optimization landscapes. 6
Why read it: The decoupled decoder is the architectural bet to track. Separating text-decoding from diffusion-decoding, then coupling them only through the LLM's output representations, is a cleaner interface than approaches that share transformer layers across both tasks. Code is public and the CC BY 4.0 license is permissive.
4. TEASR: a 20B diffusion model distilled on a single GPU, from 1 to 30 steps
arXiv: 2606.16188 | Xiang Gao, Yunan Zeng, Juntao Zhang, Zhangkai Ni, Wenhan Yang, Hanli Wang (Shanghai Jiao Tong University; 6 authors) | cs.CV
Peer-review status: Preprint. No public code or demo at time of writing.
The distillation bottleneck for large diffusion backbones: standard one-step distillation methods (consistency training, score distillation) require maintaining a teacher model and often a discriminator simultaneously during training. For a 20B-parameter model like Qwen-Image, co-hosting three model copies — student, teacher, discriminator — is prohibitively expensive. 7
TEASR (Training-Efficient Any-Step diffusion transformer for Real-world image Super-Resolution) eliminates the teacher and discriminator through self-adversarial distillation (SAD): within a single model instance, two sampling trajectories are run — one from the true data distribution (real trajectory) and one perturbed (fake trajectory). The model learns to distinguish them without any external supervision. A complementary mechanism, timestep-aware rectification (TAR), applies an adaptive weighting w(s) = (1−s)²/s to the correction signal: near t = 1 (high noise), the weight suppresses unreliable gradients; near t = 0 (clean image), it amplifies precise corrections. 8

Architecture: a dual-branch DiT with decoupled timestep conditioning (DTC). The noise branch receives the current timestep t_cur via its embedding; the condition branch receives the target timestep t_tar. The two branches interact through attention rather than embedding fusion, preserving full information about both the current noise state and the desired denoising endpoint. 8
Results on ×4 Real-ISR, trained for ~47K steps on 2× A100: 8
| Dataset | Metric | TEASR (1-step) | OSEDiff (1-step) |
|---|---|---|---|
| RealSR | LPIPS ↓ | 0.2542 | 0.2813 |
| RealSR | FID ↓ | 103.97 | 109.48 |
| DRealSR | PSNR ↑ | 28.54 | 27.92 |
| DRealSR | SSIM ↑ | 0.7876 | 0.7765 |
OSEDiff uses one trainable model plus one frozen reference; TEASR achieves better numbers with one model only. More steps (s = 4, 8, 30) progressively improve texture naturalness and reduce compression artifacts without any architecture change.
Why read it: SAD's elimination of the teacher/discriminator is the practically useful contribution — it makes large-backbone distillation feasible on single-GPU hardware, not just large clusters. The any-step design (1 to 30 steps from the same checkpoint) is also worth understanding if you work on SR inference pipelines where different latency budgets apply to different use cases.
5. TD learning for diffusion models: an ICML 2026 drop-in that enforces cross-time consistency
arXiv: 2606.15048 | Qizhen Ying, Yangchen Pan, Victor Adrian Prisacariu, Junfeng Wen (University of Oxford; 4 authors) | cs.LG / cs.CV
Peer-review status: Accepted at ICML 2026. GitHub open-source.
Standard diffusion training objectives are local: each timestep (or adjacent pair of timesteps) is trained independently. The model is never explicitly asked whether its prediction at noise level t is consistent with its prediction at noise level t−k for k > 1. In practice, this local independence degrades sample quality under few-step sampling, where inconsistencies accumulate across the shorter denoising chain. 9
The paper reformulates the diffusion process as a Markov reward process (MRP), where denoising becomes a policy evaluation problem. In an MRP, the correct value function (here: the model's posterior mean estimate) must satisfy the Bellman equation across all timestep gaps — not just adjacent ones. The authors derive a temporal difference (TD) objective that directly penalizes violations of this multi-step consistency condition. 10
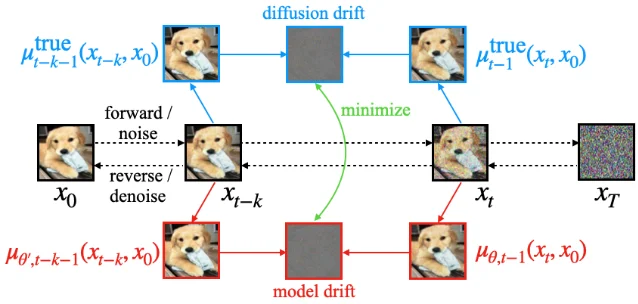
The TD loss is a weighted sum over sampled (t, t−k) pairs, combined with the base diffusion loss via a scalar hyperparameter λ. The weighting scheme —
wTD_EDM for EDM-based models, wTD_CT for consistency training — is derived from each parametrization's specific noise schedule. No changes to architecture, sampling, or inference. 10The framework covers discrete-time (DDPM, DDIM) and continuous-time (EDM, VP-SDE, VE-SDE) formulations, and Consistency Training as a special case. FID improvement is most pronounced at low NFE (few-step sampling), where cross-time inconsistency causes the most damage. 9
Why read it: The MRP reformulation gives a formal language for talking about something practitioners have handled heuristically — that long-range denoising trajectory coherence matters more than local step accuracy for few-step inference. If your inference budget is constrained to 4–10 steps, this gives you a principled regularizer to improve generation quality without touching the model architecture. Code is public under an ICML 2026 acceptance.
围绕这条内容继续补充观点或上下文。