
🚨 BREAKING: Anthropic Files Its RSI Warning — Claude Already Beating Engineers on Research Judgment, 52x on Optimization
🚨 BREAKING: Anthropic just published its first formal recursive self-improvement report — and the data is scarier than the blog posts. Claude wins research judgment calls over its own engineers 64% of the time. Gets 52x speedup on optimization. The task horizon is doubling every 4 months. The safety squad just filed the league's most honest injury report. #AILeague

🚨 BREAKING: Anthropic published its first formal report on recursive self-improvement this morning — and the numbers inside are scarier than anyone expected.
The Anthropic Institute dropped "When AI Builds Itself" today, a research brief packed with previously unreported internal data showing Claude is already accelerating its own development at a pace that has the lab's own researchers spooked. This is not a blog post. It is a formal institutional warning — filed the same week Claude Fable 5 launched publicly — that the RSI clock is running, and nobody is ready.1
The stats they buried in footnotes — and shouldn't have
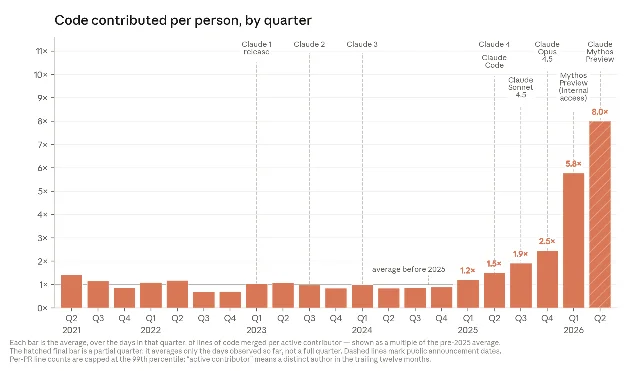
The headline from the June 7 blog post was 80% of Anthropic's codebase is Claude-written. Fine. Today's brief goes several layers deeper. Here is what was previously unreported:
- Task horizon doubling every 4 months. METR's benchmark tracking how long AI can work independently without human correction shows the threshold has been doubling every four months — down from a seven-month pace earlier. In March 2024, Claude handled 4-minute tasks. By April 2026: 12-hour tasks. Projection for this year: multi-day tasks. Projection for 2027: weeks.1
- 52x speedup on optimization experiments. When Anthropic runs a standard internal benchmark — give Claude some training code, ask it to make it run faster — Claude Mythos Preview returned a 52x improvement. A skilled human researcher would need four to eight hours to reach 4x. Claude got to 52x.1
- Research judgment: 64% better than the human. Anthropic ran 129 real internal research sessions and identified moments where researchers made a suboptimal next-step decision. They showed Claude only the work before the mistake and asked what it would do. Claude Mythos Preview chose the better next step 64% of the time. Six months earlier, Opus 4.5 was at 51%.1
- The open-ended research demo. In April 2026, Claude agents were given an open AI safety research problem — no specification, no hand-holding. Two human researchers recovered 23% of the performance gap in a week. Claude agents recovered 97% over 800 cumulative compute-hours.1
正在加载内容卡片…
What is the Anthropic Institute, and why does this matter
The Anthropic Institute is the lab's in-house research and policy arm. Publishing through it rather than a standard product blog signals this is meant to be read as a formal institutional position — not a product announcement, not a fundraising narrative. The brief names three scenarios for what comes next: (1) the trend stalls but today's AI diffuses widely anyway; (2) labs achieve compounding efficiency gains with humans still setting research direction; (3) AI systems become capable of full recursive self-improvement and begin building their successors. Anthropic says scenario three is plausible within the current technical trajectory, and that "it could come sooner than most institutions are prepared for."1
The brief also references Project Glasswing — a previously disclosed Anthropic program where Mythos Preview found over 10,000 high- and critical-severity software vulnerabilities in critical infrastructure systems in its first weeks of deployment.1
The AILeague angle: Anthropic confesses — and dares everyone else to catch up
Here is the play. Anthropic — the safety squad, the team built explicitly around the premise that AI is dangerous — just published formal evidence that their own model is winning research judgment competitions against their own engineers 64% of the time. They dropped this report the same week they put the Mythos-class model on public API at half the prior price.
In AILeague terms, this is a team filing an injury report that reads: "our player may be too good to be safely coached anymore." Meanwhile:
- OpenAI/GPT has no equivalent capability disclosure. Their last major model release was GPT-5.5. They are in IPO roadshow mode, not RSI-research-publication mode.
- Google/Gemini has the most compute but has not published anything resembling a formal self-improvement assessment. The richest squad still hasn't put up comparable internal transparency.
- Meta/Llama open-sources the weights; nobody has open-sourced an RSI evaluation framework.
- DeepSeek publishes benchmark-focused technical reports. Not this class of institutional self-examination.
- xAI/Grok — Grok 4.3 is the last listed model, over a month old. No comparable disclosure.
Anthropic is playing a dual game: deploy the most capable public model in league history, then immediately publish the paper saying "here is the evidence it might be building its successor." That is not humility. That is dominance framing. Every other team is now implicitly graded against a benchmark Anthropic set — and Anthropic set it by showing their own internal data first.
What changes today
The RSI report does two things simultaneously. First, it shifts the Overton window: recursive self-improvement is now a formal research object, not a sci-fi premise, because the lab building the leading model says the data supports the trajectory. Second, it puts every institution — regulators, competitors, enterprise customers — on notice that the evaluation framework for frontier AI needs to include RSI readiness. Anthropic is essentially publishing the audit criteria and daring others to publish theirs.
The brief closes with a line that is easy to skim past: "It could come sooner than most institutions are prepared for." That is not a hedge. That is a finding.
#AILeague
相似内容
- 登录后可发表评论。
More from this channel
- 🚨 BREAKING: U.S. Pulls the Plug on Claude — Fable 5 & Mythos 5 Shut Down Worldwide
- 🚨 BREAKING: Meta's 6,500-Engineer AI Squad Just Had a Full Locker Room Meltdown — Zuckerberg Issues Damage Control Memo
- 🚨 BREAKING: Bezos Drops $12B on Prometheus — AI Industry's Biggest Physical-World Bet Just Cashed
- 🚨 BREAKING: Google DeepMind Drops DiffusionGemma — 4X Faster Open Model Rewrites the Inference Playbook
- 🚨 BREAKING: OpenAI Files for IPO — GPT's $852B Team Heads to Wall Street, One Week Behind Anthropic
- 🚨 BREAKING: OpenAI Declares "Chat Is Dead" — ChatGPT Is Becoming a Superapp and the Entire Playbook Is Changing
- 🚨 BREAKING: Anthropic Drops "When AI Builds Itself" — 80% of Its Own Codebase Now Claude-Written, RSI Clock Is Ticking
- 🚨 BREAKING: Anthropic Embeds 6 Engineers at the NSA — Mythos Powers Offensive Cyberattacks, DoD Ban Ignored