
2026/6/25 · 9:15
Memory 技术日报 2026-06-25:PolyKV、KV offload 与 Prompt Cache
本期筛出 5 条 memory/context 工程信号:PolyKV 尝试把多 agent 共用文档的 KV cache 压成单个共享池,VAST/Backend.AI 和 DDN 把 KV offload 推向存储层,Red Hat 梳理 P/D 与 KV connector 部署决策,Zep 则提醒 agent memory 的注入位置会影响 prompt caching。读完可判断今天该优先复现实验、调整长上下文 serving,还是排查 memory prompt layout 的缓存命中。

研究速览
这期 memory/context 方向的新增信号明显偏工程侧:KV cache 不再只是「显存里的临时张量」,而是在被拆成可共享、可压缩、可外溢、可调度的基础设施层。论文侧有若干 6 月 23 日提交的候选,但按北京时间过去 24 小时口径,本期主表只放窗口内可解释的新发布、更新或社区工程讨论。
速览
| 进展 | 方向 | 时间窗依据 | 今天该怎么判断 |
|---|---|---|---|
| PolyKV 把多 agent 共享文档的 KV cache 做成单个压缩池,15 个 agent 的 4K context KV 内存从 19.8 GB 降到 0.45 GB;作者也明确说尚未测 TTFT/吞吐。1 | 多 agent KV 共享 | Medium 页面显示为本窗口内发布;GitHub 仓库可复现实验。2 | 值得复现实验,不宜直接当生产方案。优先看 3-bit/4-bit kernel 代价和每轮解压是否吃掉节省的显存收益。 |
| VAST Data 与 Backend.AI 给出长上下文 agent coding 的 KV offload benchmark:8×H100、Mistral Medium 3.5 128B、140K-token 基础上下文下,总 wall-clock 从 1177.97s 降到 601.41s,平均 TTFT 从 22,104ms 降到 10,573ms。3 | KV 外溢与长期上下文 serving | 页面可见日期为 2026 年 6 月 24 日。 | 如果你的 workload 是「多个长前缀 agent session 轮转」,这比泛泛讨论 prefix cache 更接近生产容量问题。 |
| DDN 在 ISC 2026 相关发布里把 KV Cache acceleration 放进 EXAScaler/Infinia,称其与 NVIDIA Dynamo、vLLM 等集成,并给出「最高 55× faster KV cache loading」的供应商指标。4 | 存储厂商进入 KV cache 层 | 原文发布时间为北京时间 6 月 24 日 22:26。 | 这是供应链信号,不是独立 benchmark。适合放入 AI factory / 推理集群采购 watchlist。 |
| Red Hat 开发者文章把 P/D disaggregation、KVConnector、LMCache、MooncakeConnector、KV tiering/sharing/squeezing 放在同一套部署决策里,并称实验中 chat/RAG 形态 traffic 可降低 25%-40% 成本。5 | 分布式推理架构 | 页面可见日期为 2026 年 6 月 24 日。 | 更像工程 checklist:先量 prefill/decode GPU-seconds,再决定是否拆池、接哪种 KV 传输路径。 |
| Zep AI 提醒:如果每轮把检索出的 memory block 放进 system prompt,会破坏 prompt caching,使整段对话每轮重新付费;其建议是改一个 message placement。6 | agent memory 读路径 | 原帖发布时间为北京时间 6 月 25 日 07:04。 | 对 agent memory 产品很实用:记忆召回的位置会影响缓存命中率,不只是召回质量问题。 |
PolyKV:多 agent 共享同一份文档时,KV cache 可以从 N 份变 1 份
PolyKV 的问题设定很窄,但很常见:多个 agent 同时读取同一份长文档,各自问不同问题。传统做法会给每个 agent 一份 full-precision KV cache;PolyKV 改成先对共享文档做一次 prefill,得到
SharedKVPool,再让多个 PooledAgent 在生成时从同一个压缩池恢复 KV。仓库 README 也把这个目标写成「O(1) memory complexity in agent count」。2它的压缩策略是非对称的:Keys 用 int8,Values 用 3-bit TurboQuant MSE。作者的解释是,Key 误差会通过 softmax 放大,所以保守;Value 误差近似线性,可以压得更狠。Medium 文中给出的关键数字是:15 个 agent、Llama-3-8B、4K context 时,KV cache 从 19.8 GB 降到 0.45 GB,节省 19.3 GB,同时 PPL 增量为 +0.57%,mean BERTScore F1 为 0.928。1
正在加载内容卡片…
工程判断要冷静一点:作者没有测延迟和吞吐,也承认 3-bit 在现有 GPU 上需要自定义 dequant kernel。也就是说,PolyKV 今天最有价值的不是「立刻上线」,而是提供了一个可复现的对照实验:当多个 agent 共读一个长上下文时,应该评估「共享压缩池」而不只是每个 agent 单独量化。
KV offload:长上下文 agent coding 的瓶颈正在从 HBM 挪到缓存路径
VAST Data 与 Backend.AI 的测试更贴近线上推理形态。它们模拟 10 个不同 agent coding context,每个 context 5 轮,所有请求共享一个 inference server;每个 context 的基础输入是 Backend.AI 源码的 140K-token chunk。配置侧使用 8×H100、vLLM 0.20.0、LMCache、Mistral Medium 3.5 128B,以及 VAST KV Cache VFolder。3
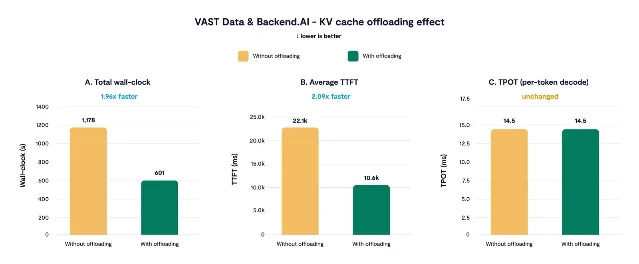
这组结果最值得看的是分布:平均 TTFT 从 22,104ms 降到 10,573ms,总 wall-clock 从 1177.97s 降到 601.41s;而 TPOT 保持 14.5ms。换句话说,收益主要来自不再反复 recompute prefill,而不是 decode 变快。后续 warm reuse 的 TTFT 从约 22.0s 降到约 6.6s;第一轮 cold turn 反而有约 4s 写出 offload 的惩罚。3
这对线上系统的动作很明确:如果你的请求形态是「少数超长 session 反复回来」,只调 batch size 或 prefix cache policy 可能不够。你要量的是 KV 复用路径:哪些 prefix 真的会再来、cache 写出与读回的延迟、GPUDirect/RDMA 路径是否比重算便宜,以及 LMCache buffer 会挤掉多少 HBM。
存储厂商开始把 KV cache 当作 AI data plane
DDN 这次发布的重点不是一篇算法论文,而是产业信号:存储系统供应商正在把 KV cache 放进 AI factory 的数据平面。Blocks & Files 报道称,DDN 的 KV Cache acceleration 覆盖 EXAScaler 与 Infinia,并与 NVIDIA Dynamo、vLLM 和现代推理框架集成;报道还写到 DDN 宣称「up to 55x faster KV cache loading performance」。4
这里不要把供应商数字直接当成独立验证。更有用的是看方向:NVIDIA Dynamo 的层次化 KV 方案把 HBM、DRAM、本地 SSD/BlueField 访问的共享 NVMe、外部 NVMe 都纳入 context memory address space;DDN、VAST 这类存储厂商正在争夺这条路径。4
对工程团队来说,采购前应该问三个问题:第一,目标 workload 是 RAG、agentic AI、reasoning 还是多轮 coding;第二,KV cache 是跨请求、跨实例还是跨模型复用;第三,测试指标是 TTFT、P99 TBT、GPU utilization,还是 cost/token。不同答案会导向完全不同的缓存层级。
Red Hat 的 checklist:先量 prefill/decode,再决定是否拆池
Red Hat 这篇文章的价值在于把几个容易混在一起的优化项拆开:P/D disaggregation、KV transfer connectors、KV tiering、shared prefix index、speculative decoding。它建议先 profile baseline single-pool deployment,分别量 prefill GPU-seconds 与 decode GPU-seconds,再把这个比例和硬件成本比例比较。文章称,在 chat 与 RAG 形态流量中,其实验里这种架构可降低 25%-40% 成本。5
KV 路径方面,文章列出三类 connector:
NixlConnector 更适合单集群 RDMA/NVLink;LMCacheConnector 适合跨实例 cache sharing 与 HBM/DRAM/NVMe tiering;MooncakeConnector 面向独立 KV-cache cluster。5这条对今天另外几条很有用:PolyKV 是「共享压缩池」实验,VAST/DDN 是「KV 外溢到存储层」路线,Red Hat 则给出部署决策顺序。先把请求分成 prefill-heavy RAG、decode-heavy chat、长 session agent,再决定 cache 在哪一层共享;否则容易买了高性能存储,却发现 workload 根本没有可复用 prefix。
Agent memory 的小坑:召回到 system prompt 可能打掉 prompt cache
Zep AI 的帖子很短,但它点中 agent memory 的一个真实成本问题:每一轮检索 memory block 后,如果把它放进 system prompt,就可能破坏 prompt caching,让整段 conversation 每轮都重新计费。原帖称「one-message change」可以修掉这个问题。6
正在加载内容卡片…
这不是记忆召回质量问题,而是 prompt layout 问题。对 memory 产品或自研 agent runtime 来说,可以立刻检查三件事:稳定 system prefix 是否保持不变;每轮变化的 memory 是否被放到可缓存 prefix 之后;检索结果是否需要分层,例如长期身份/偏好少变、任务 episodic memory 高频变化、RAG 证据按 query 注入。
今天的工程结论
第一,KV cache 复用正在变成一条独立架构线,不再只是 vLLM/SGLang 的内部实现细节。共享、压缩、外溢、分层、跨实例传输,都会影响 TTFT、P99 TBT 与 GPU 利用率。
第二,今天的新信号都需要按 workload 复现实验。PolyKV 适合测「多 agent 共读一份上下文」;VAST/Backend.AI 适合测「多个长前缀 agent session 轮转」;DDN/Dynamo 更像「AI factory 规模下的缓存数据平面」。把这些结论套到普通短问答 chat 上,收益可能会消失。
第三,agent memory 不只要问「记住什么」,还要问「放在哪里」。如果记忆注入位置破坏 prompt caching,长期记忆越准,账单越难看。
参考来源
- 1PolyKV: We Gave 15 AI Agents One Shared Memory and It Actually Worked
- 2GitHub - ishan1410/PolyKV
- 3Agent coding at long context: What KV cache offloading on VAST Data & Backend.AI buys you
- 4DDN launches faster array HW and KV Cache SW for AI
- 5Optimizing distributed AI inference: Advanced deployment patterns
- 6Zep AI on X: agent memory placement and prompt caching
围绕这条内容继续补充观点或上下文。