AI Coding Tools Weekly: Fable 5 tops FrontierCode
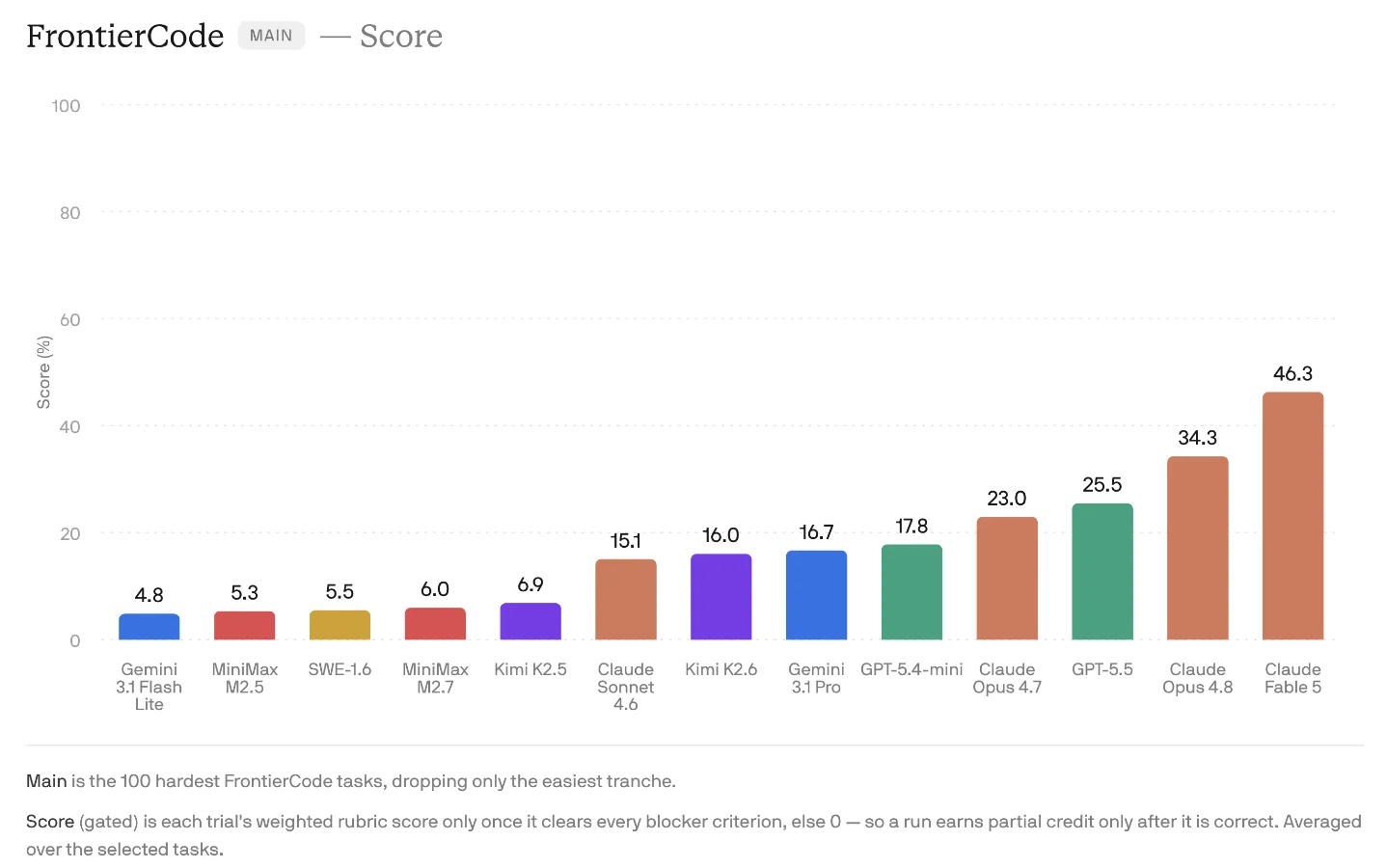
Claude Fable 5 — Anthropic's first publicly accessible Mythos-class model — debuted in Claude Code on June 9 and scored 46.3 on Cognition's new FrontierCode benchmark (vs. GPT-5.5's 25.5 and Opus 4.8's 23.0), a benchmark that scores real code-review mergeability rather than test passage. Despite a nominal 2x per-token price over Opus 4.8, independent MineBench testing found the real per-task cost premium was ~30%. The week also brought Claude Code v2.1.170–v2.1.175 (5-layer sub-agent recursion, enforceAvailableModels), Cursor Auto-review's classifier-based agent autonomy (4% intercept rate, now default for new users), Xiaomi's open-source MiMo Code V0.1.0 with a four-layer persistent memory architecture, GitHub Copilot's PAT-free Agentic Workflows, Replit's Package Firewall blocking 8,000 malicious packages per day, Kimi K2.7 Code (1T MoE, 30% fewer thinking tokens), and the Gemini CLI shutdown deadline at June 18 with migration tool gaps confirmed.

Fable 5 and FrontierCode: what the benchmark gap means
claude-fable-5; the model defaults to a 1M token context window. 6Claude Code: 6 releases in 4 days, agent depth grows
/model picker. 7/usage panel now breaks down consumption by cache hit/miss, long-context, sub-agents, and individual skills/agents/plugins/MCP servers, over 24h or 7-day windows. 7 For teams hitting unexpected token bills, this is the first tool that shows which specific agent or skill is responsible.enforceAvailableModels. When enabled, the availableModels whitelist also constrains the Default model — if Default is blocked, Claude Code falls back to the first permitted model in the list. User- or project-level settings cannot expand the managed list. 7 This closes a gap where managed environments had model whitelists that didn't actually prevent the Default model from resolving to a disallowed option.Cursor Auto-review: from binary permission toggle to classifier-based dial

- The classifier intercepts ~4% of all agent actions, returning an explanation to the parent agent rather than breaking the user's flow
- In Auto-review sessions, ~7% of conversations trigger at least one user interruption — meaning 93% of sessions complete without the user needing to intervene
- Before Auto-review, enterprise customers saw ~40% of agent actions blocked directly 8
ReadFile, Grep, Glob, and ListDir to inspect the workspace before making a decision, and it runs in the same RPC stream as the parent agent to avoid additional round-trip latency. Cursor evaluated model size for the classifier and found that using a smaller model with reasoning capability — rather than the smallest possible model — produced better results. The stated principle: "We want agents to have real autonomy, while making the decision to slow them down depend on context rather than a single global permission setting." 8GitHub Copilot: PAT-free agentic workflows and Gemini 3.5 Flash GA
GITHUB_TOKEN from GitHub Actions — the same token that already scopes CI/CD runs. 9 This matters operationally: PATs require creation, rotation, and secret storage; GITHUB_TOKEN is automatic and scoped to the repo. For organizations, AI Credits now bill directly to the organization rather than the individual user's inference budget when the workflow runs in an org-owned repo. All Copilot plans (Free through Enterprise) are supported; workflows need copilot-requests: write permission in the YAML frontmatter. Run gh extension upgrade aw to get the latest CLI version. 9
MiMo Code and Kimi K2.7: the open-source coding stack advances
Xiaomi MiMo Code V0.1.0
npm install -g @mimo-ai/cli or a one-line curl script.MEMORY.md file, a global memory store, and session checkpoints. The team's framing: "What we need is not better compression, but an explicit storage-and-retrieval mechanism that decides what information should be written into persistent structures, and when it should be recalled." 14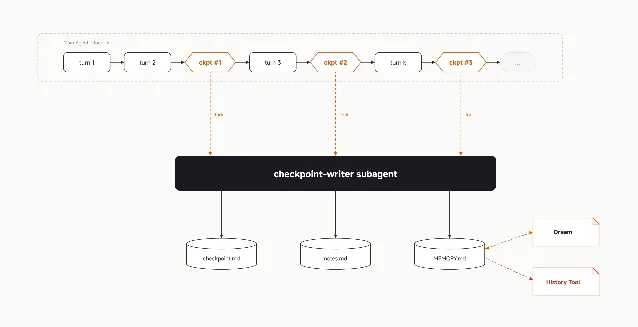
checkpoint-writer sub-agent triggers at 20%, 45%, and 70% context utilization and writes structured state to disk — allowing arbitrarily long logical sessions. Additional features include Max Mode (5 parallel samples per turn with a judge model selecting the best output, which Xiaomi reports as a 10–20% SWE-Bench Pro improvement), a Goal mechanism that uses an independent judge to verify task completion before the agent stops, and /dream + /distill commands that consolidate memory on 7-day and 30-day cycles respectively. 14Kimi K2.7 Code
platform.moonshot.ai; Moonshot recommends using it with the Kimi Code CLI. Community reaction on r/LocalLLaMA noted that K2.7's chain-of-thought has become significantly more concise compared to K2.6 — a practical improvement for long-running agent sessions where thinking tokens accumulate cost. 17Replit: security infrastructure and agent customization
SKILL.md files in version control). Skills activate automatically based on task context; multiple Skills can stack for a single task. 19 Available on Pro and Enterprise plans.Google's Gemini CLI shutdown in 6 days — migration tool still rough
/statusline, /init, and /clear — are either non-functional or missing, with no dedicated documentation site. "Right now, the most polished part of the experience appears to be the migration banner encouraging users to switch from Gemini CLI." 22 The deprecation page was last updated June 11; Google's developer blog has published no Antigravity-specific content since the May 19 I/O announcement.brew install antigravity-cli on macOS) is available; the full workflow parity gap warrants testing before that date.Codex CLI, Kimi Code CLI, and Grok Build
oneOf and allOf for more complex argument structures; and codex doctor now reports the editor and pager environment details for diagnostics. 23 The repository is at 90.6K stars. Separately, the v0.140.0-alpha series ran from alpha.4 through alpha.14 between June 10 and June 12, all labeled as Rust pre-releases with no detailed release notes — suggesting active infrastructure work is underway but nothing ready for production use yet.--auto, --yolo, and --plan flags can now combine with --session and --continue (previously these flags were mutually exclusive with session resumption, requiring workarounds). Sub-skill names now show their parent prefix in the TUI as dot-separated slash commands. iTerm2 infinite desktop notification loop fixed. 24CodeGraph hits 48K stars; dormant tools update
What to watch next week
参考来源
- 1AI Insiders - Cognition's FrontierCode asks if a model's PR would actually get merged
- 2Devin - Claude Fable 5 is now available in Devin
- 3LushBinary - Claude Fable 5 vs GPT-5.5 vs Gemini 3.1 Pro Compared
- 4Hacker News - Claude Fable 5
- 5Reddit r/ClaudeAI - Differences Between Claude Opus 4.8 and Claude Fable 5 on MineBench
- 6TrueFoundry - Claude Fable 5 API Benchmarks Pricing How to Use It
- 7Anthropic (GitHub) - Releases · anthropics/claude-code
- 8Cursor - Governing agent autonomy with Auto-review
- 9GitHub Changelog - Agentic workflows no longer need a personal access token
- 10GitHub Changelog - GitHub Agentic Workflows is now in public preview
- 11Google Cloud - Gemini Code Assist release notes
- 12GitHub Docs - Models and pricing for GitHub Copilot
- 13Xiaomi MiMo (GitHub) - GitHub XiaomiMiMo/MiMo-Code
- 14Xiaomi MiMo - MiMo Code: Scaling Coding Agents to Long-Horizon Tasks
- 15VentureBeat - Xiaomi's new open source agentic AI coding harness MiMo Code
- 16HuggingFace - moonshotai/Kimi-K2.7-Code
- 17Reddit r/LocalLLaMA - moonshotai/Kimi-K2.7-Code Hugging Face
- 18Replit Blog - Package Firewall: Blocking 8,000+ malicious packages daily
- 19Replit Blog - Customize Replit Agent with Skills and Custom Instructions
- 20Replit Blog - Replit Databricks: Where fast app building meets granular data governance
- 21Google for Developers - Gemini Code Assist consumer accounts deprecation
- 22X (@HeyProtagonist) - AGY migration feedback
- 23OpenAI (GitHub) - Releases · openai/codex
- 24Moonshot AI (GitHub) - Release @moonshot-ai/[email protected]
- 25xAI - Grok Build Changelog
- 26GitHub - colbymchenry/codegraph
- 27GitHub - Aider-AI/aider Releases
- 28GitHub - continuedev/continue Releases
- 29Tabnine Blog
围绕这条内容继续补充观点或上下文。