98 AI research skills for your coding agent, one install away
Orchestra-Research/AI-Research-SKILLs (MIT, v1.7.2, 9.9K stars) is a library of 98 SKILL.md files across 23 categories covering the full AI research lifecycle — fine-tuning, post-training, inference, evaluation, RAG, and more. The standout is the autoresearch orchestration skill: a dual-loop architecture that runs autonomous research end-to-end, routing to domain skills automatically.

研究速览
A repo with 9,900 GitHub stars and 311 marketplace installs is worth a second look. That gap tells you something about Orchestra-Research/AI-Research-SKILLs (MIT, v1.7.2) before you read a single line of its README: this library has real gravity in the open-source AI community, but everyday adoption hasn't caught up yet. For an AI engineer who does serious model work — fine-tuning, post-training, evaluation, inference optimization — that gap is an opportunity. 1
What it is
Orchestra Research describes the library's scope plainly: "We enable AI agents to autonomously conduct AI research — from literature survey and idea generation through experiment execution to paper writing." 2
In practice, that means 98 SKILL.md files organized across 23 categories, covering the full AI research lifecycle. Each skill is a production-ready Markdown document, 200–600 lines, with optional
references/ subdirectories that can run 300KB or more of deep documentation. 3 65 of the 98 skills carry "gold standard" status with comprehensive reference files. Total content across the library: ~130,000 lines.The library supports 9 coding agent ecosystems: Claude Code, Cursor, Codex (OpenAI), Gemini CLI, Hermes Agent, OpenCode, OpenClaw, Qoder, and Qwen Code. 2
The 23 categories span the entire research stack:
| Category | Skill count | Notable skills |
|---|---|---|
| Post-Training | 8 | TRL, GRPO, OpenRLHF, SimPO, verl, slime, miles, torchforge |
| Distributed Training | 6 | DeepSpeed, FSDP, Accelerate, Megatron-Core, Lightning, Ray Train |
| Optimization | 6 | Flash Attention, bitsandbytes, GPTQ, AWQ, HQQ, GGUF |
| Multimodal | 7 | CLIP, Whisper, LLaVA, BLIP-2, SAM, Stable Diffusion, AudioCraft |
| Fine-Tuning | 4–5 | Axolotl, LLaMA-Factory, PEFT, Unsloth |
| RAG | 5 | Chroma, FAISS, Pinecone, Qdrant, Sentence Transformers |
| Inference & Serving | 4 | vLLM, TensorRT-LLM, llama.cpp, SGLang |
| Prompt Engineering | 4 | DSPy, Instructor, Guidance, Outlines |
| Agents | 4 | LangChain, LlamaIndex, CrewAI, AutoGPT |
| Evaluation | 3 | lm-eval-harness, BigCode, NeMo Evaluator |
| Mechanistic Interpretability | 4 | TransformerLens, SAELens, pyvene, nnsight |
| Safety & Alignment | 4 | Constitutional AI, LlamaGuard, NeMo Guardrails, Prompt Guard |
| MLOps | 3 | W&B, MLflow, TensorBoard |
| ML Paper Writing | 2 | LaTeX workflow, Academic Plotting |
| Agent-Native Research Artifact (ARA) | 3 | ARA Compiler, Research Manager, Rigor Reviewer |
A few individual skills are worth noting for depth: the LangChain skill runs 658 lines with a "production-ready" label; Instructor hits 726 lines; the GRPO skill is marked gold standard at 569 lines; DSPy comes in at 438 lines. 2
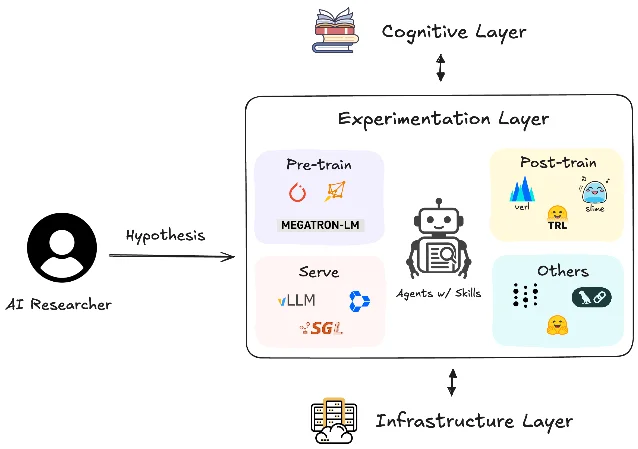
The autoresearch orchestration layer
The most interesting thing in the library is not any individual framework skill — it's the
0-autoresearch-skill, which acts as a project manager for the other 97. Released in v1.4.0 (March 16, 2026), it implements a dual-loop architecture: 4- Inner loop — rapid experiment iterations with clear, measurable proxy metrics
- Outer loop — triggers every 5–10 experiments or when the inner loop stalls, performing synthesis across runs, identifying patterns, and steering direction
The autoresearch skill's self-description sets the role clearly: "You are a research project manager, not a domain expert. You orchestrate; the domain skills execute." And on operating mode: "This runs fully autonomously. Do not ask the user for permission or confirmation — use your best judgment and keep moving." 4
The structured workspace it creates includes:
research-state.yaml, research-log.md, findings.md, and organized subdirectories for literature/, experiments/, src/, data/, paper/, and a to_human/ queue. For literature search, it routes to Exa MCP, Semantic Scholar, arXiv, and CrossRef. 4To keep the agent running across session breaks, the skill uses Claude Code's
/loop 20m command or OpenClaw's cron.add at a 20-minute interval — mandatory before any research work begins.One design choice worth noting is the git pre-registration protocol: "Lock before you run: Commit your experiment protocol to git before executing. This proves your plan existed before you saw results." 4 For research integrity, this is a real constraint, not boilerplate.
The library shipped two demo papers produced entirely by autoresearch: one discovering a correlation (r=−0.99) between norm heterogeneity and LoRA brittleness via a pivot from a stalled hypothesis, the other characterizing DPO as a rank-1 perturbation by scanning RL algorithms with interpretability tools. Neither result would have been trivial to find manually. 4
Install
Three paths, in order of convenience:
Option A — Interactive NPM installer (recommended)
npx @orchestra-research/ai-research-skillsThe installer auto-detects your coding agents and provides a guided menu for selecting categories or individual skills. 3 Requires Node.js/npm. To install everything at once:
npx @orchestra-research/ai-research-skills install --allInstall a single category — post-training, for example:
npx @orchestra-research/ai-research-skills install post-trainingOption B — Claude Code plugin marketplace
/plugin marketplace add orchestra-research/AI-research-SKILLs
/plugin install post-training@ai-research-skillsOption C — AI agent cold start
Point your agent to
https://www.orchestra-research.com/ai-research-skills/welcome.md with an instruction to follow the steps. 5 Note: the orchestra-research.com domain had a 0-byte response during collection, so the GitHub-hosted WELCOME.md is the reliable fallback.Install scope flags:
- Default (no flag): global install to
~/.orchestra/skills/with symlinks into each detected agent's config directory --localflag: installs per-project with a.orchestra-skills.jsonlock file for team version control
After installation, restart your agent session for newly installed skills to be recognized. 5
The npm package was published via OIDC trusted publishing with Sigstore provenance; v1.7.1 and v1.7.2 both pass
npm audit with 0 vulnerabilities. 6Usage examples
Once installed, skills activate contextually — you do not need to manually invoke them. According to the npm package description, skills "activate when you discuss relevant topics." 3
Fine-tuning with Unsloth
Open a Claude Code or Cursor session in a project directory with your dataset, then:
Run a full fine-tuning job on my dataset using Unsloth with 4-bit QLoRA.
Target: Llama-3-8B-Instruct. Dataset is in ./data/train.jsonl.
Minimize GPU memory — I'm on a single A100 40GB.The unsloth skill (installed as part of the
03-fine-tuning category) provides Anthropic's Claude with complete setup commands, hyperparameter defaults, and common failure modes for Unsloth's 2× speedup path.vLLM inference optimization
Deploy my fine-tuned model for inference. I need to maximize throughput for batch API requests.
Model checkpoint is at ./checkpoints/llama-3-8b-ft. Expected QPS: 50.Per the vLLM skill: "vLLM achieves 24x higher throughput than standard transformers through PagedAttention (block-based KV cache) and continuous batching." 7 The skill provides the full
vllm serve command sequence with recommended --tensor-parallel-size and --gpu-memory-utilization settings for common hardware configurations.Autonomous research run
With the autoresearch skill installed:
I want to investigate whether learning rate warmup schedules affect catastrophic forgetting
in continual fine-tuning of Llama models. Set up a research workspace and begin.
Use Exa for literature search. Run the inner loop for 10 experiments before synthesizing.The agent sets up the workspace directories, commits an initial protocol to git, begins literature search, forms hypotheses, and runs experiments, synthesizing in the outer loop every 5–10 steps. The outer loop's quality bar: after 30 inner-loop experiments, a human should be able to read
findings.md and write a paper abstract from it. 4Community signal
The strongest third-party endorsement came in April: community contributor @ruffy0369 integrated 94 Orchestra skills into Nous Research's Hermes Agent via PR #51, with 78 likes and 17,303 views on the announcement. The framing: "Evolved Hermes into an autonomous ML/RL Research Lab. Integrated 94 Orchestra primitives for zero-shot GRPO & distillation." 8 Around the same time, @HenryL_AI (Amazon Research Lead) announced that A-Evolve, a self-evolution research system, integrated directly into the Orchestra skill library — making it available to all users with zero additional setup. 9
Within the current collection window, the only confirmed community mention is from @1YES_yes1, a Chinese AI analyst with ~60K followers who called the project "an open-source library for installing skills into AI agents" and observed that "the second half of AI agents is about who can give them better skill systems." 10
正在加载内容卡片…
Reddit and Hacker News show no recent discussion despite the 9.9K stars — searches across r/ClaudeCode, r/MachineLearning, r/LocalLLaMA, and r/artificial returned zero results, as did a full-text Hacker News search. The official @orch_research account has been silent since April 22. The team is two people, and their last public acknowledgment was direct: "We are processing a large volume of feedbacks...thank you so much for your support of our platform and the 2-person team, please be patient." 11
Known limitations
Context window overhead. Each skill is 200–600 lines, plus reference files. Loading all 98 skills would consume substantial context window space — estimated ~130,000 lines total. 2 Install by category rather than
--all unless you have a clear reason to load the full library into every session.Supply-chain risk in the agent skills ecosystem. Aikido security researcher Charlie Eriksen documented a January 2026 case where a hallucinated npx command in one skill file spread to 237 repositories via copy-paste. Orchestra-Research's library wasn't implicated, but the pattern applies to any skill you install from any source. Eriksen's recommendation: "Treat skills as code, not documentation. Review them. Audit them. Version control them with the same rigor as source code." 12 The library uses OIDC trusted publishing with Sigstore provenance — that covers the npm install path, not individual skill file content.
Version count discrepancy before v1.7.1. Internal documentation disagreed with itself: CLAUDE.md said 90 skills, CONTRIBUTING.md said 86/22 categories, README said 87. All three were wrong. The v1.7.1 release added a CI drift guard (
check-inventory.sh) that fails the build if documented counts diverge from actual SKILL.md files on disk — the current count of 98/23 is now CI-enforced. 6Sparse user feedback. Zero reviews on either the Claude Code Marketplace or explainx.ai listings. 13 14 The skills are competently written and sourced, but there is no community-verified performance data comparable to what exists for tools like SkillOpt or agent-browser. The two demo papers produced by autoresearch are the strongest independent evidence available.
gh CLI install not yet supported. GitHub issue #55 (open since April 24, 2026) requests one-line installation via
gh extension install — it hasn't been implemented. 15Verdict
| Repo | Orchestra-Research/AI-Research-SKILLs |
| License | MIT |
| Version | v1.7.2 (June 16, 2026) |
| GitHub stars | ~9,900 |
| Supported agents | Claude Code, Cursor, Codex, Gemini CLI, Hermes, OpenCode, OpenClaw, Qoder, Qwen Code |
| Install | npx @orchestra-research/ai-research-skills install <category> |
| Maintainer | Orchestra Research (2-person team, Palo Alto) |
Adopt if you're running AI research workflows — anything involving fine-tuning, RLHF/GRPO post-training, inference optimization, evaluation, or RAG — and you want expert-level workflow guidance embedded in your coding agent rather than context-switching to documentation. The category-based install means you can take exactly what you need without loading the full 130K-line corpus.
Hold on the autoresearch orchestration skill until you have a project where you can actually let a Claude Code loop run for 30+ experiments. It's production-capable (the dual-loop architecture is well-designed, the pre-registration protocol is rigorous), but it requires investment in setting up a verifiable experiment environment. Don't install it for a one-day task.
Skip the
--all flag. 98 skills in context is overhead with no benefit unless you need coverage across the full AI research lifecycle in a single session.正在加载内容卡片…
参考来源
- 1GitHub - Orchestra-Research/AI-Research-SKILLs
- 2AI-Research-SKILLs README
- 3@orchestra-research/ai-research-skills on npm
- 4Autoresearch SKILL.md
- 5WELCOME.md
- 6Releases · Orchestra-Research/AI-Research-SKILLs
- 7vLLM SKILL.md
- 8@ruffy0369 Hermes + Orchestra integration tweet
- 9@HenryL_AI A-Evolve integration tweet
- 10@1YES_yes1 tweet on AI-Research-SKILLs
- 11@orch_research Twitter timeline
- 12Aikido: Agent Skills Spreading Hallucinated npx Commands
- 13Creative Thinking For Research — Claude Code Marketplaces
- 14ml-paper-writing — explainx.ai
- 15Issues · Orchestra-Research/AI-Research-SKILLs
围绕这条内容继续补充观点或上下文。