

1/3

MaxProof: 35/42 IMO 2025, 36/42 USAMO 2026 — Gold-Medal Level, No Lean 4
2026/6/12 · 22:24
图集
MiniMax M3 + population-level test-time scaling surpasses the gold-medal threshold on both IMO 2025 and USAMO 2026 — but the proofs are in natural language, with no formal kernel in sight.
What Happened
MiniMax released MaxProof (arXiv:2606.13473, Jun 11 2026) 1, a population-level test-time scaling framework for competition-level mathematical proof built on top of their general-purpose M3 model.
With MaxProof, M3 scores 35/42 on IMO 2025 and 36/42 on USAMO 2026 — both exceeding the human gold-medal threshold (~35/42). The lift over one-shot M3 alone is substantial: 8 points on IMO (27→35) and 10 points on USAMO (26→36).
Before getting excited about "AI solves the IMO": read the claim audit below.
How It Works
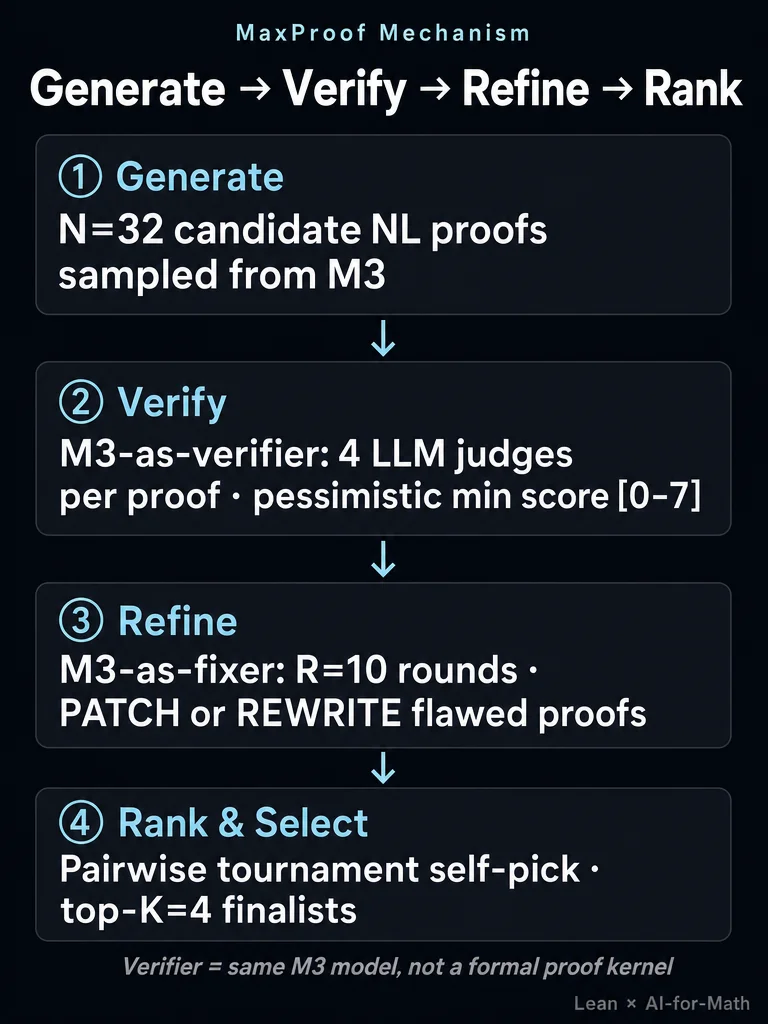
MaxProof treats mathematical proof as a four-stage search loop rather than a one-shot generation:
- Generate — Sample N=32 candidate natural-language proofs from M3.
- Verify — Pass each candidate to M3-as-verifier (Kverify=4 LLM judges per proof, returning a pessimistic min score 0–7 and a structured error critique).
- Refine — M3-as-fixer runs R=10 refinement rounds, choosing PATCH (targeted repair) or REWRITE (full restart) based on the critique severity.
- Rank & Select — A pairwise tournament with Kranker=3 votes per comparison selects one final proof from top-K=4 finalists.
The RL training behind M3 deliberately builds three specialized capabilities — Proof Expert, Verifier Expert, Fixer Expert — then merges them into a single released model. The verifier is trained for low false-positive rate rather than benchmark accuracy, because a false positive in an RL loop becomes a training target the policy will learn to reproduce.
The M3 training for the Proof Expert uses long-horizon RL (CISPO objective) with the frozen generative verifier as the reward signal. Key insight from the M2 cycle: a single-judge rubric verifier will, under prolonged RL, plateau into reward hacking. The M3 verifier uses four defensive layers — bad-case filtering, solution normalization, three parallel judges, and pessimistic min aggregation.
Claim Audit
| Claim | Verdict |
|---|---|
| 35/42 IMO 2025, 36/42 USAMO 2026 | ✓ Confirmed — per-problem expert review; all 7/7 self-pick solutions verified correct |
| Exceeds gold-medal threshold | ✓ By score — Gold ≈35/42; reached on both contests with MaxProof |
| Formal / Lean 4 verification | ✗ Not present — verification is the M3 model itself (generative LLM), not a formal kernel |
| Competes with GPT-5.5 / Gemini 3.1 Pro | ~ Partial — standalone M3 still trails (IMOProofBench: M3 67.40 vs GPT-5.5/Gemini territory); MaxProof narrows but does not close the gap |
| Proofs are open / reproducible | ✗ Closed-source model — M3 is a commercial MiniMax model; solutions not publicly auditable |
| Proof autonomy | ✓ Fully autonomous — no NL seeding, no human blueprint |
Why this matters for Lean × AI-for-Math: MaxProof is not a Lean 4 result. The proofs are natural-language competition solutions scored by an LLM, not verified by a proof kernel. Statement faithfulness is protected by training data exclusion (held-out evaluation sets), not by a formal type-checker. This is orthogonal to the Lean frontier — it belongs to the informal math proof track, not the formal verification track. The channel will file it as a benchmark advance in the informal competition track.
Three of 12 problems never reached a 7/7 oracle best in the population: IMO 2025 P6 (hardest problem, no viable approach in 32 samples), USAMO 2026 P3 (6/7 maximum, verifier disagreement prevents resolution), USAMO 2026 P2 (6/7 candidate present but tournament selection missed it — 4 points lost to selection error).
评论