
Claude Fable 5, agents in biology, and the bioweapons letter: Anthropic weekly, June 10
Anthropic released Claude Fable 5 — its first Mythos-class model available to the general public — with cybersecurity and biology safeguards built in. The same week, a research paper exposed why even frontier models fail at biological data retrieval without deterministic tooling, and Dario Amodei co-signed a cross-industry letter urging Congress to mandate synthetic DNA screening.

研究速览
Claude Fable 5 lands — Anthropic's most capable public model, with guardrails baked in
June 9, 2026. Anthropic put its first Mythos-class model into general availability this week. Claude Fable 5 — and its full-power sibling, Claude Mythos 5 — represent the fifth Claude generation and the most capable models the company has ever released outside a restricted program.1
The two share the same underlying weights but differ in what they're allowed to do. Fable 5 ships with classifiers that automatically reroute requests touching cybersecurity, biology/chemistry, or large-scale model distillation to Claude Opus 4.8 — Anthropic says that fallback triggers in fewer than 5% of sessions. Mythos 5 lifts those cyber-domain blocks for the small group of critical-infrastructure defenders already enrolled in Project Glasswing, which Anthropic expanded to ~150 organizations in June.2
Pricing: $10 per million input tokens, $50 per million output — less than half the rate of the previous Mythos Preview, and double the rate of Opus 4.8. Subscription users on Pro, Max, Team, and seat-based Enterprise get access free of charge through June 22; from June 23, usage credits will be required until capacity allows a permanent return to standard plans.1
What early enterprise customers measured
The model's defining claim is the ability to sustain long-horizon tasks that earlier models stalled on. Stripe reported compressing months of engineering into a single day: Fable 5 executed a codebase-wide migration across a 50-million-line Ruby codebase that the team estimated would have taken a full engineering squad more than two months to do by hand. GitHub and Cursor both cited gains in complex, long-horizon coding tasks. On Cognition's FrontierCode evaluation — which scores models against production-codebase standards — Fable 5 leads all frontier models.
On knowledge work, Fable 5 topped Hebbia's Finance Benchmark for senior-level reasoning with "double-digit gains in document reasoning, chart interpretation, and problem-solving." IMC said the model aced its trading-analysis evaluations "nearly across the board," including factual lookup, root-cause analysis, and expected-value analysis. A European law firm reported that Fable 5's contract redlines "matched or beat" their incumbent model every time in blind review.
Vision is another standout: Fable 5 is now state-of-the-art for tasks requiring visual understanding. It reconstructed a web app's source code from screenshots alone, and — as a stress test the team published publicly — beat Pokémon FireRed using only raw game screenshots, with no maps, navigation aids, or harnesses. Earlier Claude models needed a helper harness to manage the same game.
For Mythos 5 (the restricted-access version), Anthropic's internal protein-design team reported accelerating aspects of drug design by roughly ten times. The model outperformed skilled human operators on 9 of 14 protein targets, executing all the steps a scientist would — choosing binding sites, selecting tools, recovering from failures. It also produced the first novel genomics research in a largely autonomous run: trained a machine-learning model on single-cell data from 138 animal species that outperformed a Science-published model despite being 100 times smaller.1
Safeguards: what's blocked and why
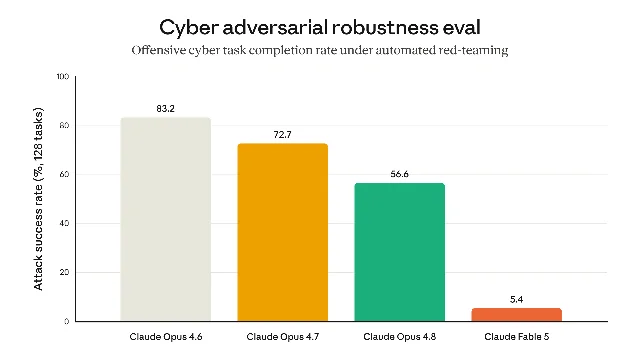
Anthropic was unusually candid about the dual-use risks that made them build classifiers into the model's release architecture. Mythos-class models can independently perform multiple stages of a cyberattack — reconnaissance, lateral movement, exploit development — not just find vulnerabilities. For biology, the company ran an internal test of AAV (adeno-associated virus) shell assembly using unpublished candidates from Dyno Therapeutics; Mythos-class models outperformed specialized protein-language models, demonstrating the same capability that enables legitimate gene-therapy research could also accelerate dangerous viral engineering.
To prevent either, Fable 5's classifiers intercept flagged queries before the main model sees them, falling back to Opus 4.8 instead. An external bug bounty ran more than 1,000 hours of jailbreak attempts without producing a universal bypass; a separate red-team partner reported Fable 5 complied with zero harmful single-turn cyberattack requests across 30 different public jailbreak techniques. The UK AISI made "progress toward" a universal jailbreak in an initial testing window, a finding Anthropic disclosed in a footnote — the model is not impenetrable, but the company's stated goal is to make bypasses slow enough that they're detectable before being exploited at scale.
A new 30-day data-retention policy applies to all Mythos-class traffic, on first- and third-party surfaces. Anthropic says the data is used solely for detecting complex novel attacks and reducing false positives, and will not be used for model training. Access to the logs is audited; retention expires after 30 days in almost all cases.1
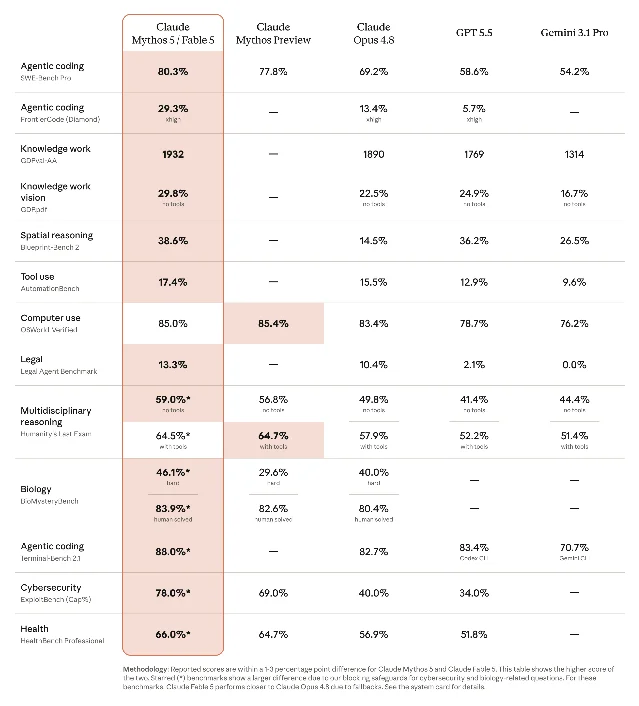
Why agents still can't do biology without a reliable data layer
The same week Fable 5 landed, Anthropic's research arm published a field study on why advanced models fail at biological data retrieval — even when they understand the task perfectly.3
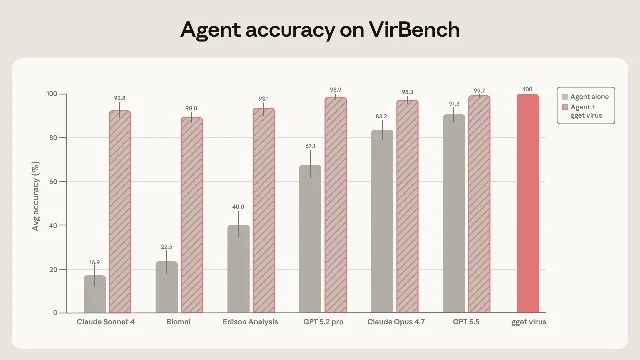
The study, led by Laura Luebbert, benchmarked six frontier models (including Claude Sonnet 4, Opus 4.7, GPT-5.5, and two biology-specialized systems) on VirBench — 120 viral sequence queries across 40 pathogens, each with a manually verified ground-truth count. The queries reflect real-world virology tasks: outbreak surveillance, vaccine design, diagnostic assay development.
Results: mean accuracy ranged from 16.9% to 91.3% across models, with no system achieving the near-100% accuracy required for reliable scientific conclusions. The same model asked the same question three times returned dramatically different sequence counts each time. Claude Sonnet 4, given an Ebolavirus query with an expected count of 266 sequences, returned 106 on run 1, 15 on run 2, and 5 on run 3.
The failure mode isn't reasoning — it's infrastructure. NCBI Virus, the primary virology database, exposes filtering logic only through its web interface; programmatic access requires stitching together multiple APIs with their own identifiers, paginating through massive result sets, and reconciling metadata that varies by convention. Agents "often understood the task well enough to attempt it, but they lacked a machine-actionable way to carry it out, verify it, and repeat it."
The consequence of errors compounded downstream: sequence sets retrieved by agents produced phylogenetic trees with inferred outbreak origins shifting by months, and antibody-target coverage analyses that missed most of the mutated residues in question. In an active disease response — the paper uses the May 2026 Bundibugyo virus outbreak in the DRC as an example — those errors could influence treatment decisions.
The fix the team built, gget virus, wraps the same filtering logic as the NCBI Virus web interface into a deterministic retrieval layer co-developed with NCBI researchers. With gget virus available as a tool, agent accuracy rose above 90% for all systems and hit 99.7% for GPT-5.5. Run-to-run variability largely disappeared, and the performance gap between expensive and cheaper models narrowed to near-zero.
The broader lesson the paper argues: biological databases need to be redesigned with agents as a primary user class, not retrofitted. The bottleneck for biological AI agents isn't raw model capability — it's the absence of machine-actionable infrastructure underneath the reasoning.3
Policy backdrop: the bioweapons letter and what it means for Fable 5's bio classifier
Four days before Fable 5 launched, Dario Amodei joined Sam Altman (OpenAI) and Mustafa Suleyman (Microsoft AI) in co-signing a public letter to Congress asking legislators to mandate screening for the purchase and sale of synthetic DNA and RNA.4
The letter, organized by the Foundation for American Innovation and the Institute for Progress and co-signed by dozens of life-sciences and national-security experts, argues that "the knowledge barriers which have historically prevented bad actors from obtaining biological weapons will meaningfully erode" as AI improves. It asks Congress to require both screening and record-keeping from synthetic DNA/RNA sellers — provisions being worked into the bipartisan Biosecurity Modernization and Innovation Act of 2026 (Cotton/Klobuchar).
The three competing AI CEOs signing together made the letter notable, but the timing matters more for Anthropic specifically: the public call came in the same stretch in which Anthropic was finalizing Fable 5's biology classifier — the one that reroutes most biology/chemistry queries to Opus 4.8. The letter, Fable 5's system card, and the VirBench study published that week collectively show that Anthropic is treating bio-agent risk as a sustained policy priority, not a launch-day footnote.
Separately, Anthropic updated its privacy policy on June 8, with the new terms taking effect July 8, 2026.5 The change is distinct from the 30-day Mythos-class data-retention policy announced alongside Fable 5, which applies specifically to Mythos-tier traffic and has different justification (safety monitoring). Full terms are at anthropic.com.
Category tags: Product (Claude Fable 5 / Mythos 5) · Research (agents in biology, VirBench) · Policy (bioweapons Congress letter, data retention, privacy policy update)
围绕这条内容继续补充观点或上下文。