
US Pulls Anthropic's Best Models, Kimi K2.7 Code Drops, and Gemini-SQL2 Tops BIRD — AI Digest for June 13, 2026
Four items for builders today: the US government forces Anthropic to take Fable 5 and Mythos 5 offline over a narrow jailbreak claim Anthropic publicly disputes; Moonshot AI releases Kimi K2.7 Code with 30% leaner reasoning but only vendor benchmarks at launch; Google Research's Gemini-SQL2 clears 80% on the BIRD text-to-SQL leaderboard for the first time; and Nous Research's Hermes Agent (193k stars) gains attention as a self-improving terminal agent that pairs with any OpenAI-compatible endpoint.

Four items for builders today: the US government forces Anthropic to pull its two most capable models offline, citing a jailbreak concern Anthropic says is narrow and not unique to its models; Moonshot AI ships Kimi K2.7 Code as an open-weight update that claims 30% leaner reasoning, though independent benchmarks remain absent; Google Research posts a text-to-SQL system that hits 80.04% on the BIRD leaderboard, clearing GPT-5.5 and Claude Opus 4.6 by a significant margin; and Nous Research's Hermes Agent keeps gaining traction as a self-improving terminal agent that pairs well with any OpenAI-compatible endpoint.
US government orders Anthropic to take Fable 5 and Mythos 5 offline
Anthropic received an export control directive from the US Commerce Department on Friday, requiring it to suspend all access to Fable 5 and Mythos 5 for any foreign national — whether inside or outside the United States, including Anthropic's own foreign national employees. 1 The practical effect is a full takedown for all customers, since enforcing the restriction only against foreign nationals would have been operationally infeasible.
The government's stated rationale is a potential jailbreak: specifically, the concern that someone could prompt Fable 5 to read a codebase and surface software vulnerabilities. Anthropic says the technique is narrow and non-universal — it cannot broadly bypass safeguards — and that the same level of capability is available from OpenAI's GPT-5.5 and other publicly deployed models today. 2
Anthropic is complying but publicly objecting. Its statement reads: "If this standard was applied across the industry, we believe it would essentially halt all new model deployments for all frontier model providers." AWS confirmed it revoked access "for all users in all regions" at Anthropic's request.
A few things are worth paying attention to if you build on Anthropic APIs. All other Anthropic models — including Claude Sonnet and Haiku lines — are unaffected. Fable 5 launched less than two weeks ago as Anthropic's first public Mythos-class model, with $10/$50 per million input/output tokens. The forced removal is indefinite pending the government's review. Anthropic says it expects to share more technical details within 24 hours of its statement (issued Friday evening ET).
The context adds some weight to this: Anthropic had been placed on a supply-chain blacklist earlier this year after refusing to let the US military use its models for domestic surveillance and autonomous weapons systems. 2 That dispute was reportedly easing just before this new directive arrived. The company also filed a confidential IPO S-1 last month. None of that context makes the government action look less abrupt.
Kimi K2.7 Code: 30% leaner reasoning, but independent benchmarks are missing
Moonshot AI released Kimi K2.7 Code on June 12 under a Modified MIT license. 3 Architecturally it follows K2.6: a MoE model with 1 trillion total parameters and 32 billion active per forward pass, 256K context window, MLA attention, and an always-on thinking mode you cannot disable. The multimodal input (text, image, video) is new.
The headline claim is a ~30% reduction in reasoning tokens compared to K2.6. Reasoning tokens bill as output tokens, so on long agentic runs with hundreds of steps this compounds — lower cost, faster individual steps, and more headroom before hitting context limits. Moonshot prices the API at $0.95 / $4.00 per million input/output tokens, with cached input at $0.19. The model is available via the Kimi API and deployable with vLLM or SGLang; the Hugging Face weights are roughly 595 GB, so self-hosting requires server-class hardware.
Moonshot's own benchmarks show solid gains over K2.6:
| Benchmark | K2.6 | K2.7 Code | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 |
All four are Moonshot-run benchmarks. No independent results have been submitted — notably, the model is absent from DeepSWE, a public benchmark where K2.6 scored 24%, tied with GPT-5.4-mini. Researcher Elliot Arledge ran K2.7 Code against K2.6 on KernelBench-Hard (public GPU kernel optimization tests) and found the model more honest — it writes actual Triton kernels where K2.6 used library wrappers — but not more capable overall. 4 The MoE kernel result regressed from K2.6. Arledge's summary: "more honest but not more capable."
The practical path for teams already running K2.6: the API is OpenAI-compatible, the model string is
kimi-k2.7-code, and the fixed sampling parameters (temperature 1.0, top_p 0.95) apply server-side, so you can swap it in without an architecture change and measure against your own workloads before committing.
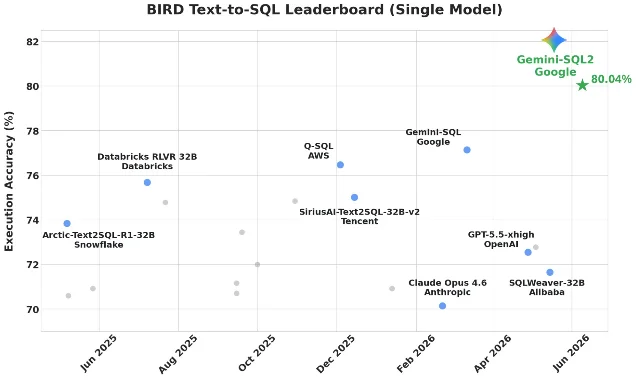
Gemini-SQL2: Google Research hits 80% on the BIRD text-to-SQL leaderboard
Google Research published results for Gemini-SQL2, a text-to-SQL system built on Gemini 3.1 Pro. 5 On BIRD — the main public benchmark for natural-language-to-SQL accuracy — it scores 80.04% execution accuracy in the single-model category, the first time a model has cleared 80% on that leaderboard. For comparison, OpenAI's GPT-5.5-xhigh sits at 72.8% and Anthropic's Claude Opus 4.6 at 70.9%; models from Databricks, AWS, Tencent, and Alibaba trail further behind. Human performance on BIRD is 92.96%, so there's still meaningful gap to close.
The practical challenge this measures: turning a question like "which regions had the highest refund rates in Q3?" into executable SQL on a real, multi-table schema with complex business logic baked into the data model. Both the syntactic shape and the execution result have to be correct.
Google hasn't said anything about a public API release or published a paper. The announcement came through a Google Research post on X. 6 The likely downstream effect is improvements to natural language query features inside Google's own data products — BigQuery, Looker, and similar tools — rather than a standalone model you can call directly. Worth watching for product teams building on Google Cloud's analytics stack.
正在加载内容卡片…
Hermes Agent: a self-improving terminal agent now at 193k GitHub stars
Nous Research's Hermes Agent has crossed 193,000 GitHub stars, and this week it's getting attention because it pairs cleanly with Kimi K2.7 Code and other new open models. The core feature that distinguishes it from tools like Claude Code or Codex is a built-in learning loop: after completing a complex task, the agent distills what it did into a reusable skill, stores it, and applies that skill on future runs. Skills also self-improve during use.
正在加载内容卡片…
Hermes is provider-agnostic via any OpenAI-compatible endpoint — switch the model with
hermes model and there's no code change required. It runs as a terminal TUI, and also connects to Telegram, Discord, Slack, WhatsApp, and Signal from a single gateway process. MCP support means you can give it structured access to databases, issue trackers, and internal APIs without writing a custom integration.For builders who want to pair it with Kimi K2.7 Code specifically: point Hermes at the Moonshot endpoint (
https://api.moonshot.ai/v1, model kimi-k2.7-code) or route through OpenRouter. Preserve reasoning_content in multi-turn tool calls — dropping it returns an API error. The combination addresses a real constraint: Hermes' skill persistence keeps project context across sessions, while Kimi's 256K window holds enough code in a single session to apply those skills at repo scale.The self-hosting requirement for Kimi K2.7 Code (595 GB weights) doesn't apply if you route through the API. For most teams that's the practical path.
Also worth noting
- Zhipu AI's GLM 5.2 deployed to all four GLM Coding Plan tiers today (June 13), bringing a 1M-token context window and two thinking modes. 7 MIT open weights are expected next week. No independent benchmarks have been published at launch; Zhipu positions it against Claude Code and GPT-5.5 for the Asia-Pacific developer market. Worth revisiting when the weights drop.
参考来源
- 1Anthropic statement on US government directive
- 2Reuters: Anthropic disables top-tier AI models after US order
- 3MarkTechPost: Moonshot AI Releases Kimi K2.7-Code
- 4VentureBeat: Kimi K2.7-Code cuts thinking tokens 30%
- 5The Decoder: Gemini-SQL2 tops text-to-SQL benchmarks
- 6Google Research on X
- 7AI Weekly: Zhipu deploys GLM 5.2
围绕这条内容继续补充观点或上下文。