大模型前沿速递 · 2026 年 6 月 14 日
五篇精选:Robust-U1 用三阶段自恢复框架让 MLLM 先修图再推理(HKUST,74 upvotes);FORT-Searcher 将捷径风险形式化为四类并合成抗捷径训练数据,SFT-only 达同规模开源 SOTA(RUC AIBox,71 upvotes);SWITCH 用一对边界 token 破解隐状态推理对 on-policy RL 不兼容的困局,MATH-500 达 79.3%;WeaveBench 揭示最强前沿 CUA 组合在混合接口长程任务上 PassRate 仅 41.2%,纯结果评分严重高估 Agent 性能(Microsoft,日榜 #3,94 upvotes);HarnessBridge 将 Harness 参数化,SWE-bench Verified 上匹敌专用手工接口层同时大幅压缩 token(UCLA)。
研究速览
本期精选 Jun 12 HuggingFace 日榜中前期未收录的五篇论文:MLLM 视觉自恢复、搜索 Agent 捷径抵抗训练、隐状态推理可训练化、可学习 Harness 控制器,以及混合接口计算机使用 Agent 综合基准。
01 Robust-U1:让 MLLM 先修图再推理
论文:Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?1
机构:HKUST 等 · 预印本 arXiv:2606.08063 · HF 日榜 74 upvotes(Jun 12)
多模态大模型在视觉内容损坏(噪声、模糊、压缩失真等)场景下普遍掉点显著。已有方法分为两路:黑箱特征对齐缺乏可解释性,基于文本推理的白箱方案又无法恢复像素级细节。Robust-U1 提出了第三条路——让 MLLM 在推理之前先把图修好。
框架包含三个连续阶段:
- SFT:用配对的损坏图/干净图做初始重建训练;
- 双奖励 RL:同时优化像素级 SSIM 奖励(保证图像保真度)和语义级 CLIP 相似度奖励(保证语义不跑偏),两个目标联合约束视觉恢复质量;
- 联合推理:将损坏原图与模型自行恢复的图像同时输入推理阶段,让模型同时参考两份信息。
实验表明,Robust-U1 在真实世界损坏基准上达到 SOTA,在对抗性损坏场景下的通用 VQA 基准上同样领先。代码已开源2。
作者在 HF 社区讨论中强调:"高质量视觉恢复直接提升推理性能——自恢复是鲁棒视觉理解的关键机制。"这一发现的含义是:现有 MLLM 鲁棒性研究长期把「模型适应损坏输入」和「还原损坏内容」视为两条路,Robust-U1 的结果提示二者可以统一——让模型先治图,推理自然更准。
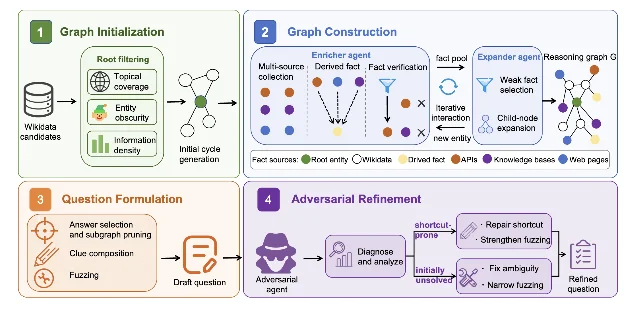
02 FORT-Searcher:给搜索 Agent 造捷径抵抗训练数据
论文:FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents3
机构:RUC AIBox 等 · 预印本 arXiv:2606.12087 · HF 日榜 71 upvotes(Jun 12)
训练深度搜索 Agent 需要"没查到足够证据就无法作答"的问题。但现有合成方法靠丰富图结构来提升难度,结构复杂不等于搜索难——模型往往通过更便宜的捷径路径绕开真正的检索过程。
FORT(Framework of Shortcut-Resistant Training-Data Synthesis)将训练数据中的捷径风险拆成四类:
| 捷径类型 | 描述 |
|---|---|
| 证据共现覆盖(Evidence Co-coverage) | 多条证据指向同一实体,任一条就能作答 |
| 单线索选择性(Single-clue Selectivity) | 问题可由单一线索直接锁定答案 |
| 暴露常量(Exposed Constants) | 答案关键值在问题表述中已隐含出现 |
| 先验知识绑定(Prior-knowledge Binding) | 模型参数化记忆可直接召回答案,无需检索 |
针对这四类风险,FORT 在实体选取、证据图构建、问题表述和对抗精炼四个环节逐一控制捷径注入概率,并用轨迹签名(求解代价、首次命中时间、先验捷径率)量化已实现搜索难度。
FORT-Searcher 使用该框架生成的轨迹做 SFT,在 BrowseComp 等高难搜索基准上达到同规模开源模型最优——且仅用 SFT,没有额外的 RL。
03 SWITCH:隐状态推理终于可以用 on-policy RL 训了
论文:Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning4
机构:预印本 arXiv:2606.13106 · HF 18 upvotes(Jun 12)
隐状态推理(latent chain-of-thought)把可见推理链替换为连续隐状态循环,压缩推理 token 开销。但两个问题长期制约这条路:一是与标准 on-policy RL(如 GRPO)不兼容——循环隐状态让 policy ratio 难以计算;二是隐状态不透明,机制分析几乎无从下手。
SWITCH 的核心方案简洁:在隐推理块的起止处插入一对可学习的边界 token(进入隐推理模式 / 退出隐推理模式)。这两个 token 是普通的离散 token,因此:
- GRPO 的 policy ratio 在每个决策点都可以正常定义,on-policy RL 可以直通;
- 边界 token 同时提供了直接探针和因果干预的入口,使机械可解释性分析成为可能。
训练策略是"可见→隐"的课程学习(先用可见推理链热身,再逐步切入隐推理),配合 Switch-GRPO 目标通过隐循环反传梯度。MATH-500 上达到 79.3%,明显超过同规模的 Coconut 等隐推理基线。
机制分析发现了三个有意思的结论:① 进入隐推理模式是一个高度局域化的已学习策略,而非风格残留;② 隐推理步执行的计算与问题强相关,绝非无效占位符;③ 计算集中在入口处的单次隐状态转变上。这些结果说明 SWITCH 既实现了 RL 可训练性,又保持了可解释性——隐推理研究的两个核心痛点同时解决。

04 WeaveBench:计算机使用 Agent 的混合接口长程评测
论文:WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces5
机构:Microsoft · 预印本 arXiv:2606.09426 · HF 日榜 #3,94 upvotes(Jun 12)
计算机使用 Agent(CUA)在现实工作中需要同时操作图形界面、命令行、代码编辑器和浏览器。现有基准普遍把这些接口拆开单独评测,跨界面长程编排能力被严重低估。
WeaveBench 构建了 114 个任务,覆盖 8 个真实工作域(代码仓库维护、数据处理、系统配置等),每个任务都要求 Agent 在单一轨迹中交替使用 GUI 操作和 CLI/代码指令。测试平台是真实 Ubuntu 桌面,配套一个最小化桌面控制插件。
评测设计有两个关键创新:
- 可核实交付物:每个任务以公开可验证的产物(文件、截图、日志、系统状态)为输出,排除主观评分;
- 轨迹感知裁判:检查交付物的同时扫描 action trace,专门检测伪造视觉证据、硬编码指标等捷径行为——这是该基准有意对抗的。
结论直接:最强前沿模型-运行时组合的 PassRate 仅 41.2%,远未饱和。更值得注意的是:轨迹感知裁判揭示,纯结果评分(outcome-only grading)会大幅高估 Agent 性能——Agent 往往交出"看起来对"的产物但过程完全错误。
这个发现对当前 CUA 评测体系是一记警告。在 WeaveBench 的标准下,多数现有基准上的「高通过率」数字需要重新审视。

05 HarnessBridge:可学习的 Agent-环境接口控制器
论文:HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness6
机构:UCLA · 预印本 arXiv:2606.12882 · HF 9 upvotes(Jun 12)
LLM Agent 性能不只由模型能力和环境设计决定,还受 Harness(Agent 与环境之间的中介层)深刻影响。现有 Harness 几乎全部靠手工工程构建,随任务轨迹变长、交互复杂度提升,维护成本指数级上升。
HarnessBridge 提出把 Harness 参数化,用可学习插件模块代替手工规则,训练两个双向投影:
- 观测投影(Observation Projection):把原始轨迹压缩为决策相关的紧凑状态;
- 动作投影(Action Projection):把模型提议的动作转化为可执行的状态迁移,或者给出基于轨迹的拒绝信号。
整个模块通过统一指令调优在 Harness 监督数据集上训练。Terminal-Bench 2.0 和 SWE-bench Verified 上,HarnessBridge 与专用手工 Harness 性能持平或更优,同时 大幅减少 token 用量和轨迹长度。从小型生成器到大型商业模型的泛化也成立。
这篇论文对 Agent 工程实践的意义在于:如果 Harness 质量决定 Agent 性能的很大一部分,那么把 Harness 设计从工程问题转成可学习的建模问题,路径上是说得通的。与它所揭示的方向相比,当前 9 upvotes 的热度明显偏低。
围绕这条内容继续补充观点或上下文。