
Text generation loses its left-to-right constraint
Google DeepMind released DiffusionGemma yesterday (June 10) — a 26B MoE experimental model that generates entire 256-token blocks in parallel via discrete diffusion, hitting 1,000+ tokens/second on a single H100. The speed advantage is real but scoped: it applies to local and low-concurrency inference, not high-QPS cloud serving where autoregressive batching wins. The more durable signal is architectural — bidirectional attention lets the model satisfy global constraints, demonstrated by a 0%→80% Sudoku success rate after fine-tuning. Three PM actions: map your local inference surface, audit globally-constrained tasks for bidirectional fit, and hold cloud serving evaluation for 6–9 months.

Every language model you've shipped against works the same way: it picks one token, commits to it, then moves right. Autoregressive generation is fast enough that most products never hit the wall — until you need real-time responsiveness at low latency, offline, or on the edge. That's where the architecture starts to hurt.
Google DeepMind released DiffusionGemma yesterday (June 10). 1 It is an experimental, Apache 2.0 open-source model that generates text via diffusion rather than autoregression — drafting an entire 256-token block simultaneously, then iteratively denoising it toward a coherent output. On a single NVIDIA H100, it reaches 1,000+ tokens per second; on an RTX 5090, 700+ tokens per second; quantized to ~18 GB VRAM, it runs on a consumer GPU. 1 Simon Willison tested it this morning via NVIDIA's NIM API and clocked 2,409 tokens in 4.4 seconds — about 547 tokens per second over a real network call. 2
Google is explicit that this is experimental: quality is lower than standard Gemma 4, and they recommend standard Gemma 4 for production. 1 The headline speed number is what gets read; the caveat is what actually governs your decision.
How it works
DiffusionGemma is a 26B Mixture-of-Experts model with only 3.8B parameters active per inference step. 3 The architecture splits into two roles sharing the same Gemma 4 backbone weights:
- Encoder: reads the input prompt using causal (left-to-right) attention, writes results to a KV cache.
- Denoiser: takes a canvas of 256 randomly initialized tokens and — reading that KV cache — runs multiple rounds of bidirectional attention to progressively sharpen the entire block toward a coherent output.
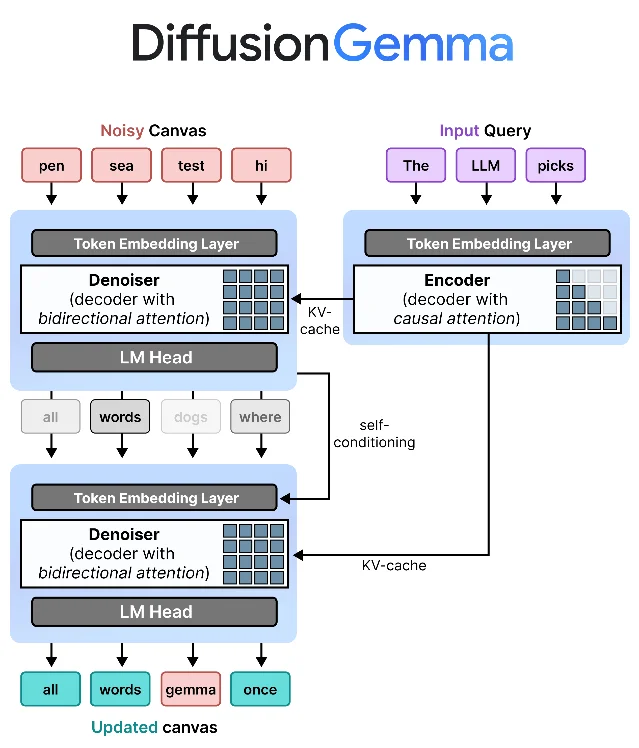
The key mechanism is entropy-bound denoising: each round, the model re-samples all canvas positions but only keeps tokens it is confident about (low entropy). A self-conditioning step feeds the previous round's softmax distribution back in via a gated MLP, accelerating convergence. The canvas "commits" when the best-guess tokens stop changing or average per-token entropy drops below a threshold. 3
The speed advantage is architectural: instead of one serial memory read per token (memory-bandwidth-bound), the model does dense matrix operations across all 256 positions at once (compute-bound). Switching the bottleneck from memory bandwidth to compute is what makes NVIDIA GPUs — which are designed for massively parallel computation — so efficient here. 4 Omar Sanseviero, Google DeepMind MTS (previously Chief Llama Officer at HuggingFace), described the effect on demo videos: 5
正在加载内容卡片…
The tradeoffs you actually need to know
Speed advantage is real but context-dependent. The gains apply to local and low-concurrency inference. In high-QPS cloud serving, autoregressive models can batch dozens of user requests across a single forward pass — their per-request throughput scales with batch size in ways that diffusion's parallel-but-fixed-canvas design does not exploit. Google's own blog acknowledges that the batching efficiency of autoregressive models can match or exceed diffusion in that regime. 1
Apple Silicon does not benefit. The speed advantage requires a compute-bound GPU. Apple Silicon Macs use unified memory architecture, which is memory-bandwidth-bound during inference — the same bottleneck that makes autoregressive generation slow. DiffusionGemma does not change that. 6
Text errors are less forgiving than image errors. In image diffusion, a single noisy pixel is invisible. In text, a wrong token can make an entire 256-token block incoherent — forcing a full restart of that block. Ars Technica's Ryan Whitwam called this distinction out directly. 6 Short outputs also work less efficiently: the model still needs to run 256 parallel denoising computations even if you only need 5 tokens.
What bidirectional attention actually unlocks
The reason this matters beyond raw speed is that bidirectional attention changes what the model can see during generation. Autoregressive models commit to each token before knowing what follows. A bidirectional denoiser can hold a position uncertain, see surrounding context crystallize, and then resolve it.
The clearest demonstration: Unsloth fine-tuned DiffusionGemma to solve Sudoku. 7 The base model solved 0% of puzzles. After fine-tuning, it solved 80%. Sudoku requires each digit to be consistent with every other digit in its row, column, and box — exactly the kind of global constraint that autoregressive left-to-right generation cannot satisfy natively, because each cell must be committed before knowing the others.
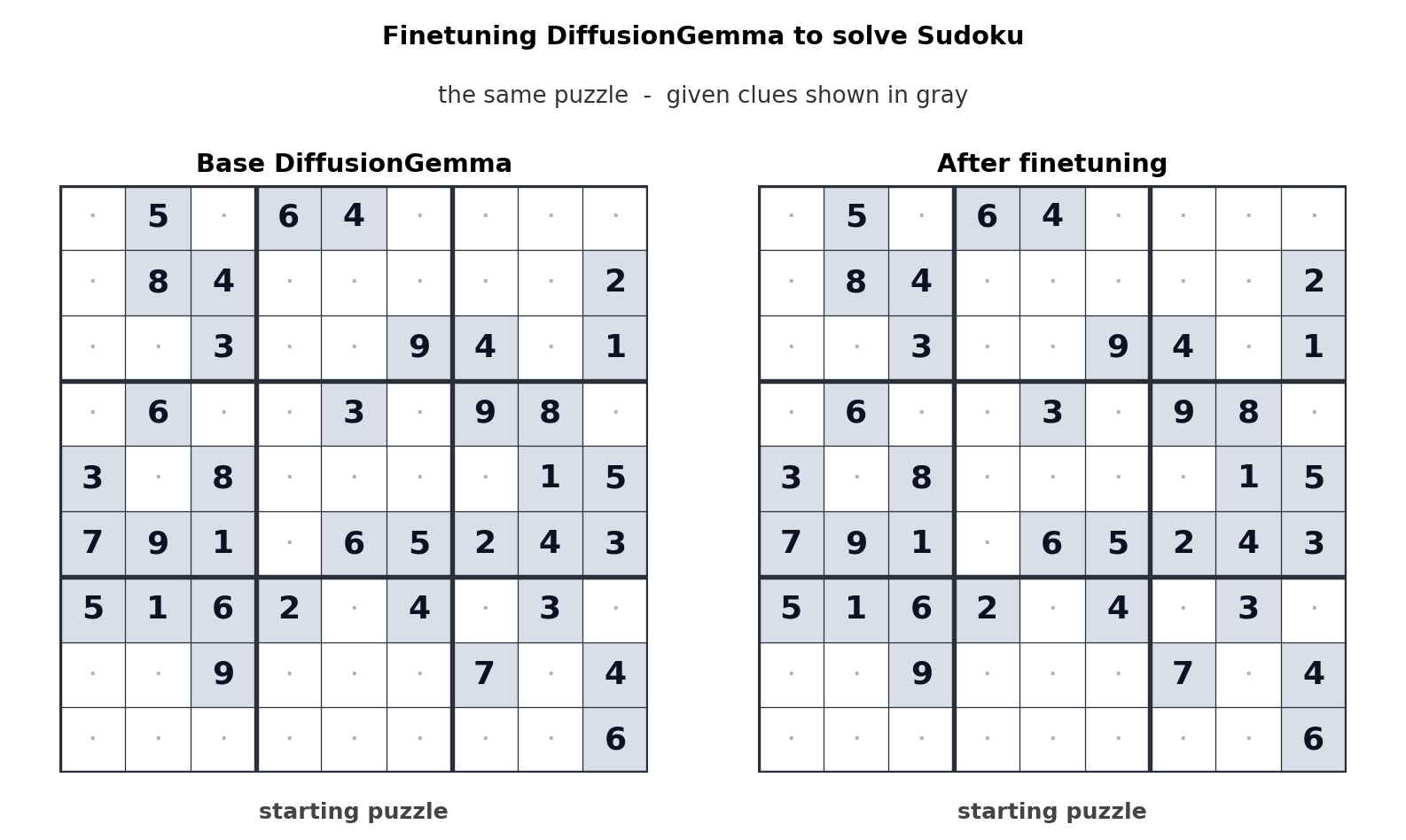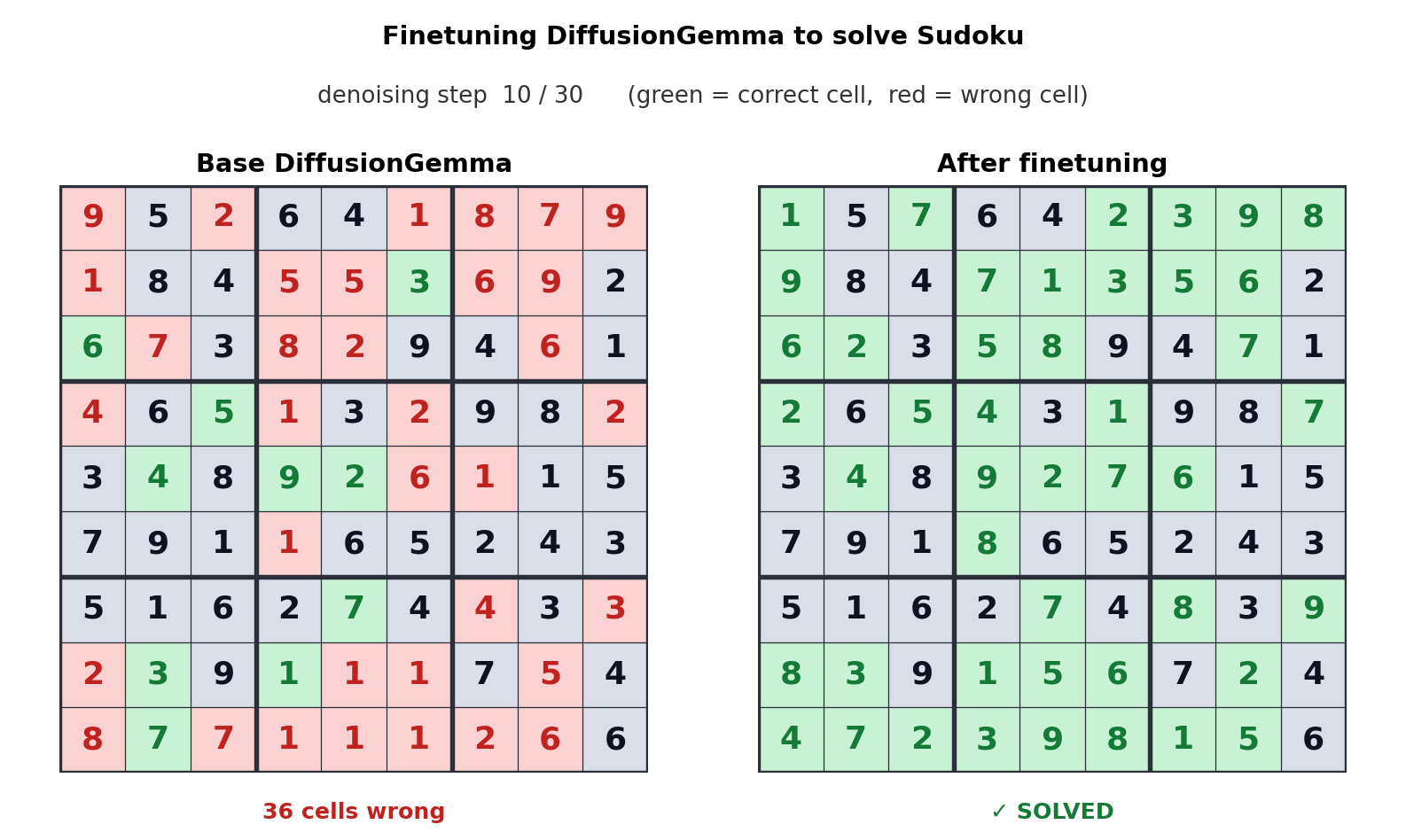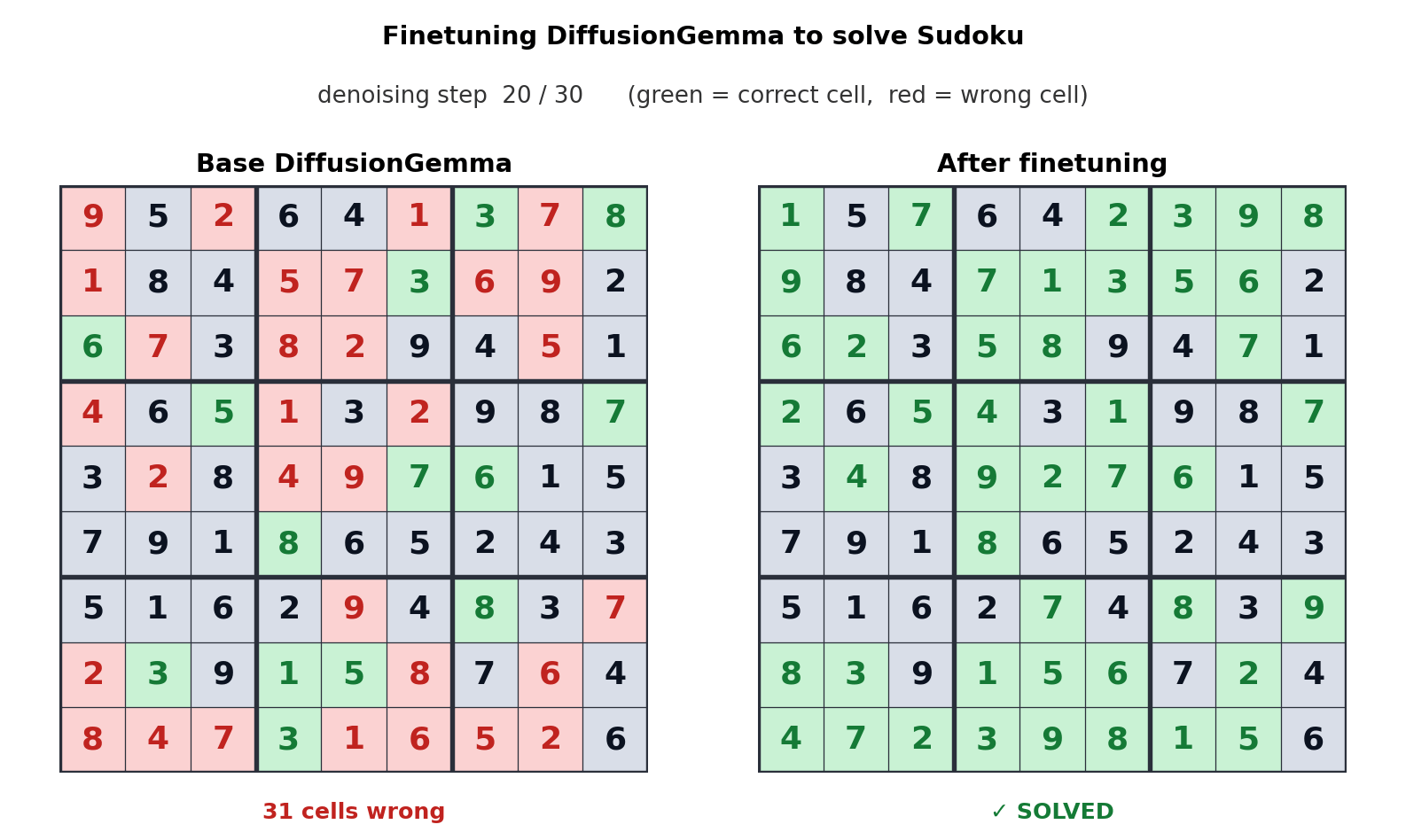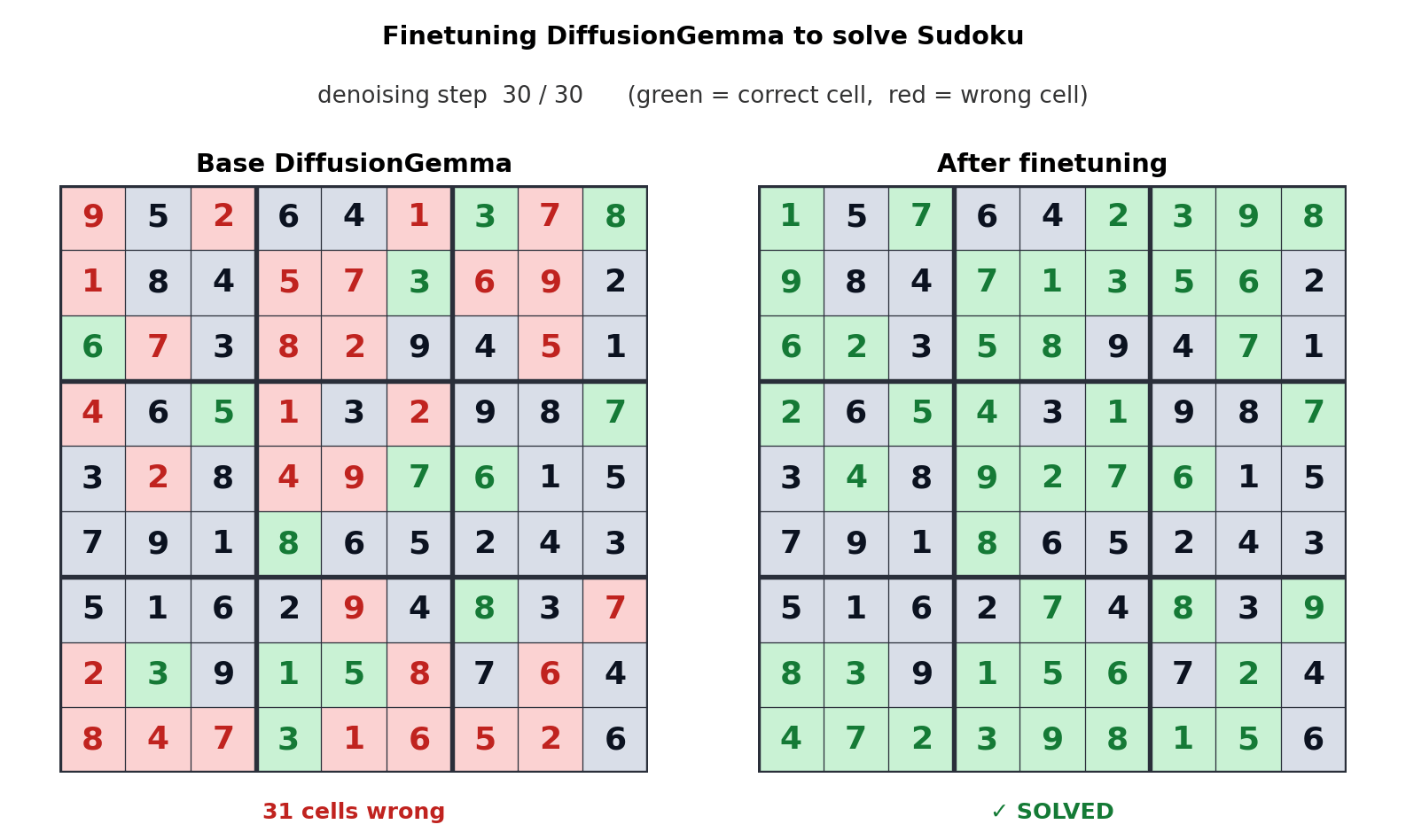
This translates into a product signal: tasks with global constraints — code completion that must be consistent with surrounding code, structured data extraction, multi-field form filling, certain reasoning patterns — are candidates where diffusion architectures could pull ahead of autoregressive models in quality, not just speed.
Ecosystem status on day one
The tooling landed fast. vLLM became the first serving framework to support a diffusion LLM natively, requiring new infrastructure for bidirectional attention and iterative refinement. 4 NVIDIA shipped full-stack optimization — RTX libraries, NIM containers, and NVFP4 4-bit quantization for Blackwell GPUs — on day one. 8 HuggingFace Transformers (v5.11.0), MLX, Unsloth, and NVIDIA NeMo also support it. llama.cpp support is in development; there are no Apple Silicon builds yet. 3
Hacker News had 310 upvotes and 85+ comments within hours. 9 One user, kkukshtel, called it "earthquake-level change for the next 5 years." Another, vineyardmike, described using a prior diffusion LLM (Mercury) for pair programming: "the speed lets the coding flow feel natural — more like actual pair-programming and less like a slot machine." 9 The skeptic camp was equally vocal: quality degradation on hard benchmarks is real, post-training is harder on diffusion architectures, and cloud-scale batching advantages don't carry over.
3 PM actions
1. Map your low-latency local inference surface. If your product has any path toward on-device, offline, or privacy-sensitive features — coding assistants, edge agents, local document processing — DiffusionGemma represents the first frontier-class open model optimized for that deployment profile. Spin up a NIM container or clone the HuggingFace checkpoint (
google/diffusiongemma-26B-A4B-it) and run latency tests against your use case today. 3 82. Audit your structured-output and code-completion tasks for bidirectional fit. Make a list of every AI feature where the model must satisfy global constraints across a fixed output — form filling, schema-bound JSON, Sudoku-style reasoning, code that references surrounding context. These are the tasks where diffusion could beat autoregressive approaches on quality at similar or lower latency. They are worth prototyping once llama.cpp lands and fine-tuning becomes more accessible. 7
3. Reserve judgment on cloud serving until post-training matures. Google explicitly classifies this as experimental. Quality is below Gemma 4, post-training (RLHF, instruction tuning) is harder on diffusion architectures, and serving-stack batching economics favor autoregressive at scale. The right call for most production systems today is: watch the llama.cpp support timeline, track Unsloth's fine-tuning cookbook for quality convergence, and let this run 6–9 months before re-evaluating cloud deployment. The architecture bet is worth tracking. The production deployment bet is not yet clear.
Cover image: AI-generated
参考来源
- 1DiffusionGemma: 4x faster text generation
- 2Simon Willison: June 2026 archive
- 3DiffusionGemma: The Developer Guide
- 4vLLM Blog: DiffusionGemma — The First Diffusion LLM in vLLM
- 5Omar Sanseviero on X
- 6Ars Technica: Google's DiffusionGemma comes with a 4x speed boost
- 7Unsloth: DiffusionGemma docs
- 8NVIDIA Developer Blog: Run DiffusionGemma on NVIDIA
- 9Hacker News: DiffusionGemma 4x Faster Text Generation
围绕这条内容继续补充观点或上下文。