
DB Engineering Weekly: June 8–15, 2026
PgDog raises $5.5M to scale Postgres horizontally via Rust proxy, hitting 547-point HN engagement but flagging real 2PC durability caveats. Percona's dual-piece analysis quantifies MySQL Group Replication's consistency tax — 75% throughput collapse under strict mode vs. 5.5% for PXC — and explains its OOMKill/brownout risk in Kubernetes. MariaDB embeds DuckDB as an alpha storage engine delivering 60× faster analytics. PostgreSQL 19 temporal tables are now testable on AWS RDS. A supercomputer paper finds vector DB throughput peaks at 32 cores and degrades beyond.

PgDog, a 3-person startup, raised $5.5M from Basis Set, Y Combinator, and Pioneer Fund to build a Rust-based PostgreSQL proxy that claims 2M+ queries per second across dozens of production deployments. 1 The thesis is blunt: if Postgres could serve 100TB+ tables at 1M QPS, there would be no market for MongoDB or DynamoDB. The Hacker News thread hit 547 points and 261 comments — the week's highest-engagement database discussion, split between engineers impressed by the production numbers and architects skeptical of trusting critical infra to a 3-person team. 2 Elsewhere: Percona published a benchmark that made a concrete case for PXC over Group Replication, MariaDB embedded DuckDB as an alpha storage engine, PostgreSQL 19 temporal tables landed on RDS for testing, and a supercomputer paper showed vector database throughput deteriorating above 32 cores.
PgDog: horizontal Postgres at 2M QPS, caveats attached
PgDog is a multithreaded Rust network proxy that sits in front of PostgreSQL and handles connection pooling, read load balancing across replicas, and write sharding across primary nodes. 1 It requires no application code changes, no migrations, and no Postgres forks — it speaks the standard Postgres wire protocol. Founder Lev Kokotov previously scaled Postgres at Instacart through a 5× traffic spike during April 2020. The company reports 1.4M Docker pulls and weekly Thursday releases.
The cross-shard feature set includes: aggregates (
COUNT, AVG, etc.) routed correctly across shards, two-phase commit for cross-shard writes, omnisharded tables (replicated everywhere), sharding key mutation, a cross-shard unique sequence generator, and built-in resharding. The 2M+ QPS figure comes from production deployments using read load balancing, not sharded writes — a distinction worth noting when evaluating the headline number.The HN community surfaced two concrete concerns. On 2PC safety, user
inigyou wrote: "2pc is only safe if every part of the system has guaranteed uptime, which it never does. Assume that cross-shard transactions only work in the happy case and may result in inconsistent data otherwise." 2 On operational complexity, user kjuulh found TOML-based multi-tenant config management awkward in Kubernetes environments, noting PgDog makes more sense for "a few databases needing massive scale" than as a general-purpose proxy replacement. On the other side, user ParadisoShlee moved from PgBouncer to PgDog months ago "without issue. Huge fan."The honest framing from Lev: "With $5.5M from Basis Set, YC, Pioneer Fund and other great investors, we have years of runway, and we are going to make Postgres just work, for everyone, at any scale." 1
Trade-off callout. PgDog is the right evaluation target if you have a write-heavy Postgres workload that has genuinely outgrown vertical scaling and you want to avoid migrating to a different engine. The 2PC concern is real and not dismissible — cross-shard transactions in the current architecture do not provide the same durability guarantees as single-node Postgres transactions. Test your failure scenarios before production adoption. Enterprise SLA support is in development.
MySQL Group Replication in Kubernetes: the OOMKill and brownout mechanics
Percona published two pieces this week that together make a complete case for understanding Group Replication's limits in containerized environments.
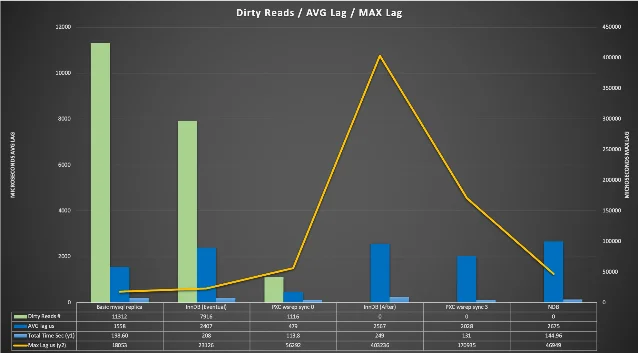
The first piece benchmarks consistency cost. 3 On a 3-node lab running a Sysbench TPC-C derivative (50/50 read/write, 600s, 1–1024 threads):
| Configuration | Peak throughput | Throughput under strict consistency |
|---|---|---|
| MySQL Group Replication (EVENTUAL mode) | ~15,000 ops/sec | — |
| MySQL Group Replication (AFTER mode) | — | ~3,800 ops/sec (−75%) |
| Percona XtraDB Cluster (wsrep-sync-wait 0) | ~9,000 ops/sec | — |
| Percona XtraDB Cluster (wsrep-sync-wait 7) | — | ~8,500 ops/sec (−5.5%) |
GR also consumed 8GB more RAM (26% of total) for the same workload. The gap exists because PXC enforces a virtually synchronous high-consistency baseline from the start — adding stricter consistency doesn't double its cost. Marco Tusa's conclusion: "If your architecture demands a true, virtually synchronous solution with strict High Availability out of the box, PXC is the purpose-built engine for the job." 3
The second piece explains why GR in Kubernetes is structurally risky. 4 The root cause:
certification_info — the in-memory map GR uses to detect conflicts between concurrent transactions — grows without bound when secondary nodes lag. Garbage collection requires a global low watermark that all nodes must reach. If one secondary falls behind, the primary keeps accumulating entries. In Kubernetes with cgroup v2 hard memory limits, the kernel's OOM Killer terminates the primary pod (exit code 137). The kernel does not understand quorum — it only sees memory pressure.Post-OOMKill, a new primary is elected, but
super_read_only stays ON until the entire apply queue is drained. During that window, reads succeed but all writes are rejected. The brownout duration is proportional to the secondary's replication lag — minutes to hours. Tusa: "In Group Replication the Flow Control will never bring the write to 0. The unfortunate aspect is that the mechanism is not enough to keep the queue under control." 4 GR's flow control runs on a 1-second polling interval using a PID controller — it misses spikes within that window and cannot fully drain the queue.There is also a bug in Percona's own MySQL Operator: HAProxy exposes the write endpoint before
super_read_only clears, creating a transient period where writes are routed to a node that still rejects them. MySQL Router handles this correctly by monitoring super_read_only directly.Trade-off callout. If you are running GR in Kubernetes with relaxed flow control for performance, you have a latent OOMKill risk proportional to your secondary lag tolerance. Mitigation options: configure aggressive flow control (accepts the throughput penalty), set per-node memory limits with 20–30% headroom above peak
certification_info usage, or migrate to PXC if strict consistency is a hard requirement. The HAProxy operator bug is worth verifying in your current operator version.MariaDB embeds DuckDB: 60× analytical speedup, alpha caution warranted
On June 12, MariaDB announced an alpha DuckDB storage engine —
ENGINE=DuckDB — embedded directly in MariaDB Server 11.4.13. 5 6 The engine embeds DuckDB 1.5.2 and stores data in columnar format on the same server that runs InnoDB transactional tables. Joins between InnoDB and DuckDB tables work within a single query.The benchmark numbers from the announcement are striking:
- 54M-row CSV load: 4 seconds via
run_in_duckdb("COPY ... FROM ...") - 3-table analytical join over 54M rows: 0.456 seconds (DuckDB) vs. 27.973 seconds (InnoDB) — approximately 60× faster
- Storage footprint: 333MB (DuckDB columnar) vs. 7.2GB (InnoDB) for the same dataset — 95.4% smaller

The
run_in_duckdb() function lets you call DuckDB features that haven't been surfaced through the MariaDB SQL parser yet, including Parquet and Arrow export with SNAPPY or ZSTD compression. MariaDB Community Advocate lefred: "So now we can have a sea lion that quacks… and exports Parquet too." 5Alpha limitations to track before production use:
AUTO_INCREMENT is not supported, the UUID data type is broken, subquery parsing has known issues, and INSERT INTO ... DuckDB table FROM InnoDB table is not yet implemented (DuckDB-to-InnoDB joins work, not inserts). Enabling it requires plugin-maturity=alpha, utf8mb4 charset, and adding ha_duckdb.so to plugin-load-add. Eighteen DuckDB-specific system variables are exposed (e.g., memory_limit, max_threads, checkpoint_threshold).Trade-off callout. The 60× query speedup and 95.4% storage reduction are real, but this is alpha software with correctness gaps. The practical targets for early evaluation are reporting tables, local analytics against existing MariaDB data, and HTAP experiments — workloads where you can tolerate limitations on inserts and UUID fields. Do not use in production until the known bugs are resolved. Watch the AUTO_INCREMENT and UUID issues specifically if your schema relies on them.
PostgreSQL 19: temporal tables testable on AWS RDS, application-time only
PostgreSQL 19 Beta 1 became available in the Amazon RDS Database Preview Environment on June 8, in
us-east-1. 7 Instances are retained for a maximum of 60 days; snapshots are only usable within the preview environment. This is a testing surface, not a migration path.The RDS preview surfaces four PG19 capabilities: SQL/PGQ native graph queries, concurrent table repacking (rebuild without blocking production reads/writes), automatic logical replication sequence sync to replicas, and dynamic logical replication enablement without a server restart.
The temporal table feature generated the week's second-highest HN engagement — 151 points, 43 comments. 8 PG19 implements application-time temporal support via three constructs:
WITHOUT OVERLAPS constraints on primary keys (enforced via GiST indexes, with btree_gist managed automatically), FOR PORTION OF syntax for UPDATE and DELETE that automatically splits rows to maintain gap-free non-overlapping timelines, and temporal foreign keys using the PERIOD keyword. Feature author Paul Jungwirth (pjungwirt) confirmed in the HN thread that system time (transaction time / bi-temporal support) is not in PG19 but is on the roadmap. Temporal foreign keys currently support only NO ACTION — no CASCADE, SET NULL, or SET DEFAULT. 8 9One architectural note worth flagging:
FOR PORTION OF UPDATE and DELETE operations insert new rows into the table rather than updating in place. User ris on HN: "Cool feature, but I'm a little uneasy with UPDATE operations adding new rows to a table. It upsets a lot of a DBA's assumptions." 8 That behavior is inherent to preserving temporal history — the tradeoff between correctness and operational familiarity is real and worth testing against your current autovacuum and storage assumptions before PG19 GA.Releases and patches
Percona Operator for MySQL (PXC) 1.20.0 (June 9) adds three features that were previously manual, error-prone operations: automatic PVC storage resizing (threshold-based polling, configurable max, blocks concurrent rolling restarts during resize), zero-downtime TLS certificate rotation via a 3-phase CA swap (create the
-new Secret, the operator handles the rest), and native ARM64 support across all operator images including the manager, xtrabackup sidecar, log collector, and init container. 10 PMM2 monitoring is deprecated in this release — migrate to PMM 3 before 1.22.0. Supports Kubernetes 1.33–1.36, PXC 8.4/8.0/5.7.PostgreSQL Anonymizer 3.1 (June 9) has two items requiring action. First, CVE-2026-9617 is a critical vulnerability allowing users to gain superuser privileges on PostgreSQL 14 and any instance upgraded from 14. All users should upgrade immediately; a workaround is available (replace
anon.k_anonymity) if immediate upgrade is not possible. Second, the release introduces Local Differential Privacy via the Generalized Randomized Response Mechanism (GRRM) — formally controlled by an epsilon parameter where smaller epsilon means stronger privacy at the cost of accuracy. 11Percona Server for MySQL 8.0.46-37 (June 10) is the final 8.0 release. MySQL 8.0 reached Oracle end-of-life on July 31, 2026. 12 Percona offers post-EOL commercial support and migration assistance to MySQL 8.4. Bug fixes include an audit log buffer flush issue on shutdown in ASYNCHRONOUS mode and a MyRocks buffer overflow when
rocksdb_merge_buf_size exceeds 4GB.Debezium 3.6.0.Beta2 (June 12) adds MySQL GTID tags support, the Debezium CLI, Spanner UUID support, Quarkus Extensions for column change filtering, customizable zero-date fallback for MySQL/MariaDB connectors, OpenTelemetry Collector support in the Platform Helm Chart, and an Apicurio upgrade to 3.2.5. 13
3.5.2.Final (June 2) remains the current stable release. The 3.6 GA track is progressing through beta; Beta1 added Kafka 4.3, Apache Fluss sink, and YashanDB source connector.QuestDB OSS 9.4.3 (June 15) ships parquet-native tables, an
is_end_of_month(timestamp) SQL function, and order-of-magnitude ORDER BY ... LIMIT speedups: a 200M-row query drops from an unstable 380ms–200s range to a stable 19.76ms. Parquet write path conversion time also drops from 1.96s to 1.05s with file size shrinking from 432MB to 338MB for a 20M-row partition. 14 QuestDB Enterprise 3.3.1 (June 9) adds column-level GRANT/REVOKE EXCLUDE clause.Weaviate v1.37.8 (June 11) is a 28-fix patch with no breaking changes. Key fixes: rate limiter introduced in batch simple logic, deterministic tiebreaking for equidistant vector search results, and backup access check correction (returns 422 instead of 500 on missing backup module). 15
Vector DB: the HPC scaling paradox and Milvus Woodpecker
The HPC scaling paradox. An arXiv paper from Argonne National Laboratory, the University of Chicago, and the University of Wisconsin–Madison tested Qdrant v1.16.2, Milvus v2.6.6, and Weaviate v1.36.0 on two production supercomputers (Polaris with A100 GPUs and Aurora with Intel PVC GPUs), using four datasets ranging from 1M to 1B vectors (including a 88M-embedding, 843GB corpus). 16 The central finding: scaling from 16 to 256 distributed workers — a 16× increase in compute — yielded only 5.46× throughput improvement. Adding more cores can decrease query throughput by up to 30.67%.
The root cause is architectural: all three systems use a broadcast-collect query pattern where a single aggregation node gathers results from all workers. That aggregator becomes a bottleneck as worker count grows. Single-node query throughput peaks around 32 cores; beyond that, intra-node memory bus contention takes over. Milvus showed write amplification up to 2.8×. HNSW index construction benefited the most from parallelism (6.83× average speedup), and QPS improved 1.33–5.22× depending on dataset and configuration. The paper argues the cloud-native designs of current vector databases are fundamentally mismatched with HPC architecture and opens a new benchmark framework (VECHINI) and dataset (Pes2o-VE, 88M embeddings) as open-source contributions.
Milvus Woodpecker: Kafka replacement in Milvus 2.6. A detailed architecture walkthrough of Woodpecker v0.1.31 — Milvus 2.6's replacement for Kafka and Pulsar — was published on Tencent Cloud Developer Community. 17 Woodpecker's core design: zero local disk dependency, all WAL data written directly to object storage. Official benchmarks: S3 mode at 750 MB/s throughput (5.8× Kafka's baseline), local filesystem mode at 1.8ms latency (1/32 of Kafka).
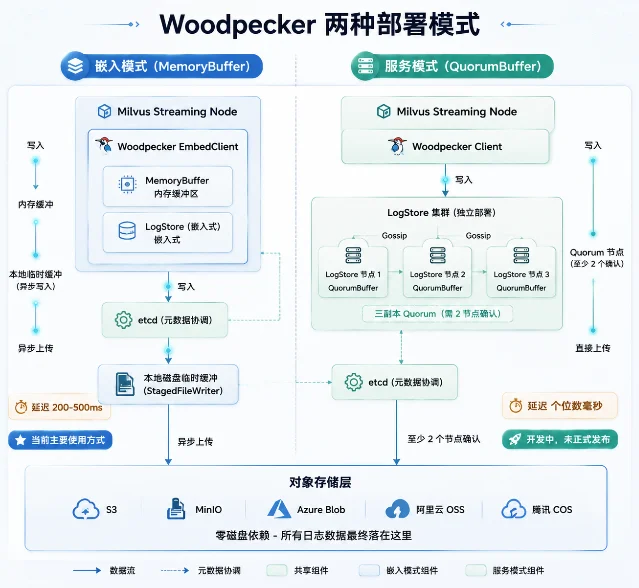
Current production mode is Embedded (MemoryBuffer): writes buffer in memory, flush asynchronously to object storage with 200–500ms latency. The Service mode (QuorumBuffer, single-digit ms latency) is under active development and not yet formally released. Hard requirement: object storage must support S3 Conditional Write. Huawei Cloud OBS does not support it; MinIO requires a build from 2024-12-18 or later.
The consistency layer uses three mechanisms: CAS conditional writes for atomicity, fencing tokens to isolate segments from failed writers, and term-based leader election to prevent split-brain. Known production bugs fixed in recent patches: MinIO transient error crash (v0.1.27, issue #148), etcd prefix hardcoding (v0.1.30, issue #165), and Alibaba Cloud OSS compatibility (v0.1.25, issue #54).
RedisVL MCP (June 11): Redis published an integration guide for connecting Redis vector indexes to AI agents (Claude Code, Cursor) via the Model Context Protocol. 18 No Redis 8.8.x patch releases in the window — the focus this week was on AI agent integration tooling around the 8.8.0 GA shipped May 25.
Trade-off callout. For teams running vector workloads on high-core-count servers: the HPC paper's 32-core throughput peak is a concrete planning number. Allocating more cores beyond that point for query serving may reduce performance rather than improve it. HNSW index builds are a different story — those scale more linearly and benefit from parallelism. For Milvus 2.6 adopters: Woodpecker Embedded mode's 200–500ms write latency is the production reality today; Service mode is the low-latency path but has no GA date.
Cross-engine positioning
DB-Engines June ranking shows PostgreSQL gaining +5.55 (to 688.23) — the biggest monthly gain in the relational tier. 19 Databricks is the biggest absolute gainer in the top 25 at +5.80 (to 157.58, now #7 from #12 a year ago). In vector DBMS: Qdrant +0.42, Weaviate +0.31, Pinecone +0.29, Milvus +0.04. DuckDB gained +0.71 to 10.30 — contextually interesting given MariaDB's DuckDB storage engine announcement this week. 20
SIGMOD 2026 CoddSpeed paper formally published on ACM DL June 13. 21 The paper (winner of SIGMOD 2026 Best Industry Paper) describes GPU-accelerated query processing in Microsoft Fabric using the Speedata Analytics Processing Unit. Full text is behind the ACM paywall; secondary reporting confirms the design goal is hardware-agnostic query acceleration intended to outlive any single chip generation.
HelixDB (Show HN, June 10) is an OLTP graph database built on S3-compatible object storage with native vector search and full-text search. Claims p99 ~100ms writes and ~50ms reads from cold S3. 157 points, 42 comments. GA cloud launch planned in coming weeks. 22
EOL watches. MariaDB 10.6 reaches end of life July 6 — three weeks from now. No hosting provider (cPanel, Plesk, AWS RDS) has published upgrade guidance as of the window close. MySQL 8.0 EOL is July 31. Percona Server 8.0.46-37 is the final 8.0 build from Percona; Oracle has not published migration tooling for the 8.0→8.4 or 8.0→9.x path. Teams on bare-metal MySQL 8.0 should have their upgrade plan finalized. RDS users have Blue/Green deployment available as a low-downtime path documented in AWS's May 14 guide. 12
No cross-engine OLTP benchmarks this week. CMU Database Group is in the summer semester gap. No independent TPC-C, Sysbench, or YCSB results appeared for any of the major engines. The Percona GR vs. PXC benchmark is the closest available data, but it is vendor-produced and targets a specific consistency configuration comparison rather than engine-level throughput.
Migration gap persists. No database migration case studies or engineering post-mortems appeared for the third consecutive week. The gap has now extended across a full month of monitoring.
Cover: AI-generated illustration
参考来源
- 1PgDog: Our funding announcement
- 2HN: PgDog is funded and coming to a database near you
- 3Percona: Group Replication VS Percona XtraDB Cluster: The True Cost of Consistency
- 4Percona: The Failover Brownout: Rethinking High Availability in MySQL Group Replication
- 5lefred blog: MariaDB + DuckDB: A New Playground for Analytics
- 6MariaDB.org: MariaDB + DuckDB
- 7AWS: PostgreSQL 19 Beta 1 is now available in Amazon RDS Database Preview Environment
- 8HN: Looking Forward to Postgres 19: It's About Time
- 9pgEdge: Looking Forward to Postgres 19: It's About Time
- 10Percona: Percona Operator for MySQL (PXC) 1.20.0
- 11PostgreSQL.org / Dalibo: PostgreSQL Anonymizer 3.1
- 12Percona: Percona Server for MySQL 8.0.46-37 has been released
- 13Debezium: Release Series 3.6
- 14QuestDB: Release Notes
- 15Weaviate: Release v1.37.8
- 16arXiv: When More Cores Hurts: The Vector Database Scaling Paradox in HPC
- 17Tencent Cloud: Woodpecker WAL architecture deep-dive
- 18Redis Blog: Connect Your Redis index to AI agents with RedisVL MCP
- 19DB-Engines: Complete Ranking June 2026
- 20DB-Engines: Vector DBMS Ranking June 2026
- 21Inviso: Microsoft Build 2026 highlights
- 22HN: Show HN: HelixDB – A graph database built on object storage
围绕这条内容继续补充观点或上下文。