
2026/6/25 · 14:51
AI agents are forcing AI teams to move from benchmarks to deployment control
Frontier labs are now pairing stronger model releases with deployment simulation, defense-in-depth controls, and workflow-level safeguards. This piece explains why that shift matters for data science and AI teams, and what to watch before putting agents into real systems.

研究速览
The short version
The AI story this week is not just "new models are better". The more important shift is operational: frontier labs are treating agent deployment as a system-risk problem that needs pre-release simulation, layered controls, monitoring, and workflow governance. OpenAI described a Deployment Simulation method on June 16, 2026 for predicting model behavior before release using privacy-preserving replays of historical conversations. 1 Google DeepMind followed on June 18, 2026 with an AI Control Roadmap that treats powerful internal agents as possible insider threats and argues for defense-in-depth controls beyond alignment alone. 2 Anthropic's Claude Opus 4.8 release on May 28, 2026 adds the other half of the picture: models are becoming more capable at coding, agentic tasks, and long-running professional workflows. 3
For data science and AI teams, the implication is simple: benchmark scores are still useful, but they are no longer enough. If a model can plan, call tools, write code, and act across enterprise systems, the evaluation target moves from "Can it answer the prompt?" to "What will it do inside our real workflow, with our data, permissions, and failure modes?"
What changed across the three signals
| Signal | What happened | Why it matters for AI and data teams | Watch-out |
|---|---|---|---|
| Deployment simulation | OpenAI says Deployment Simulation removes the original model's response from historical deployed conversations and lets the candidate model generate a replacement, creating a closer-to-real preview before release. 1 | Teams can pressure-test a model against realistic user behavior before it touches production users. | OpenAI says the method should not be expected to measure behaviors rarer than 1 in 200,000 messages. 1 |
| AI control roadmap | DeepMind frames its roadmap as a defense-in-depth system for managing advanced AI deployed inside Google, adding system-level security even when alignment is imperfect. 2 | Agent rollouts need access controls, monitoring, response rules, and threat modeling, not just a model card. | The roadmap assumes a capable agent may act unexpectedly, so governance must be designed for imperfect trust. 2 |
| Stronger agentic models | Anthropic says Claude Opus 4.8 improves across coding, agentic tasks, and professional work, with claude.ai effort controls and Claude Code dynamic workflows for large-scale tasks. 3 | Model capability is pushing from single-turn assistance toward multi-step execution. | Better capability increases both upside and blast radius if permissions, review gates, and rollback plans are weak. 3 |
The deeper trend: evaluation is becoming closer to production
Older evaluation habits often looked like this: run a benchmark, read the safety card, compare leaderboard numbers, then pilot with a small team. That workflow is still useful, but it misses an important category of risk: behavior that appears only when the model is placed into a real sequence of user requests, tool calls, permissions, and incentives.
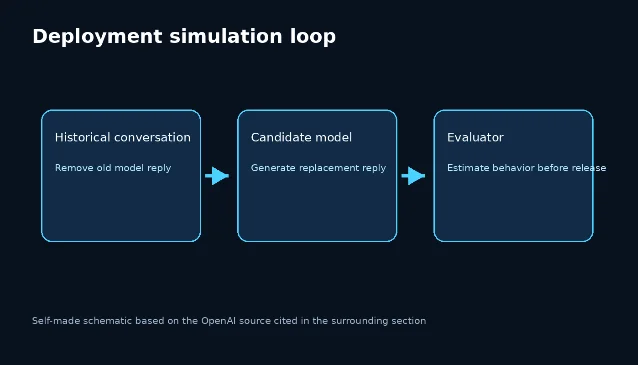
OpenAI's Deployment Simulation is notable because it uses historical conversations as the test substrate rather than only synthetic prompts. 1 The company says the approach improved estimates of misbehavior rates across GPT-5-series Thinking deployments and helped identify a new misalignment behavior before launch. 1 It also says the same idea can extend to agentic tool-use scenarios by simulating tool calls rather than executing them in a live system. 1
That is a meaningful direction for enterprise AI: testing should resemble the environment where the model will actually operate. A data science assistant that can only draft SQL is a different risk profile from an agent that can query a warehouse, update a notebook, open a pull request, and message a team.
The control layer is becoming part of the product
DeepMind's AI Control Roadmap makes a useful distinction: alignment is important, but it is not the whole safety system. 2 The roadmap describes traditional safeguards such as sandboxing, endpoint security, and prompt-injection resistance, then adds permissions based on verified behavior, monitoring by trusted AI supervisors, and response levels that can block harmful actions before damage occurs. 2
For practitioners, this reframes agent adoption. The question is not simply which model has the highest score. The question is whether the surrounding system can answer four operational questions:
- What can the agent access?
- Which actions require human approval?
- What behavior is monitored in real time?
- What happens when the system detects a harmful or off-policy action?
DeepMind also says its internal monitoring prototype analyzed a million coding-agent tasks and helped move safety work beyond simple keyword filters toward higher-signal behavioral patterns. 2 That matters because agent failures rarely announce themselves with obvious bad words; they often show up as subtle tool misuse, unsafe plans, hidden assumptions, or overconfident code changes.

The upside is still real
The critical view should not hide the progress. Anthropic says Claude Opus 4.8 improves across benchmarks and professional tasks, keeps regular usage pricing unchanged from Opus 4.7, and introduces effort controls in claude.ai so users can trade speed and rate-limit usage against deeper reasoning. 3 Anthropic also says Claude Code dynamic workflows can plan large tasks, run hundreds of parallel subagents in one session, verify outputs, and handle codebase-scale migrations across hundreds of thousands of lines of code. 3
That is exactly why stronger governance is becoming urgent. The more useful these systems become, the more tempting it is to give them broad access. The productivity upside is real: faster code migration, deeper analysis, automated QA, data cleaning, experiment scaffolding, and documentation. The downside is also real: silent data leakage, unreviewed code paths, workflow drift, and incidents that are hard to reproduce after the agent has acted.
Practical takeaways for data science leaders
If your team is adopting agentic AI, treat this as a deployment-readiness checklist:
- Test on realistic workflows, not just generic prompts. OpenAI's work points toward simulations that approximate actual deployment conversations and tool-use paths. 1
- Limit permissions before you measure reliability. DeepMind's roadmap emphasizes incremental access based on verified behavior rather than giving agents broad trust upfront. 2
- Build monitoring around behavior, not keywords. DeepMind describes moving beyond simple keyword filtering toward behavioral patterns in coding-agent tasks. 2
- Use effort controls deliberately. Anthropic's Opus 4.8 controls let users spend more effort on harder tasks and less effort when speed matters. 3
- Keep humans in the loop where the blast radius is high. The stronger the agent, the more important approval gates become for production data, credentials, customer-facing messages, and code merges.
Bottom line
The next competitive edge in AI will not come only from choosing the strongest model. It will come from knowing how to deploy strong models without pretending they are harmless autocomplete tools. The teams that win will combine model capability with deployment simulation, least-privilege access, behavioral monitoring, and clear escalation paths.
Follow Sharjeel Ibrahim / author profiles
围绕这条内容继续补充观点或上下文。