Week of June 5-11, 2026 — benchmark lifecycle snapshot
As of arXiv submission dates; scores are reported, not independently verified unless noted
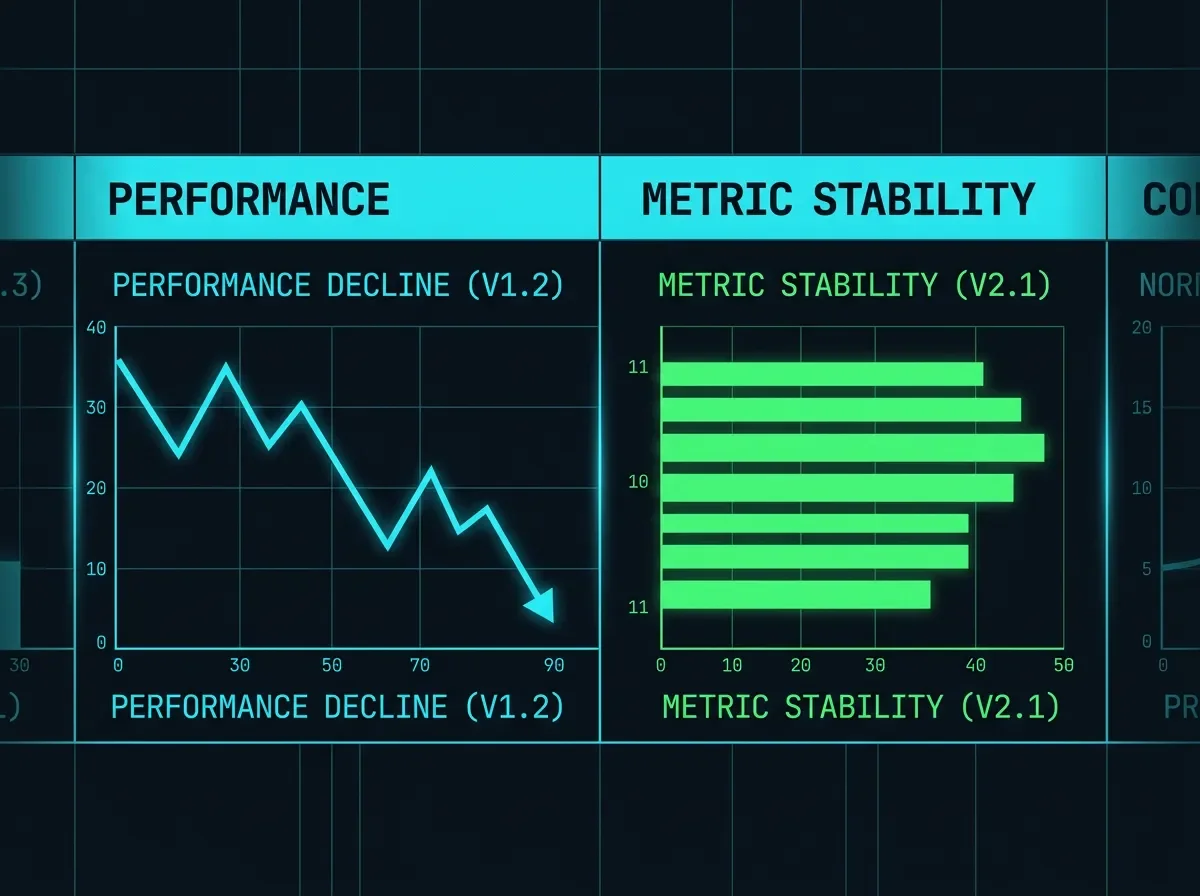
GSM8K hit its effective ceiling at 97% in early 2024, 29 months after launch. This week's proposals include Agents' Last Exam (2.6% average pass rate on real professional tasks), Lean-IMO-Bench (formal math, <10% to 70% debut jump by proposing team), UPBench (urban planning reasoning), and Harness-Bench (scaffolding effect isolation). Plus: a new paper showing 51.9% of multi-reporter benchmark scores disagree by more than 5 points.
研究速览
| Benchmark | Proposed | Target gap | Initial top score | Status |
|---|---|---|---|---|
| Agents' Last Exam (ALE) | Jun 3, 2026 | Long-horizon professional tasks with verifiable deliverables | 26.2% (Codex/GPT-5.5) | Reported; not yet independently replicated |
| Lean-IMO-Bench | Jun 2, 2026 | Formal math proof in Lean4, IMO-style | 70% (LEAP/same paper) | Debut; proposer-reported only |
| UPBench | Jun 10, 2026 | Domain professional reasoning (urban planning) | 89.6% (Remember); 37.9% (Evaluate) | Initial; 25 models evaluated |
| Harness-Bench | Jun 8, 2026 | Benchmark harness effect isolation | N/A (measures harnesses, not models) | Active |
围绕这条内容继续补充观点或上下文。