
The six-layer agent stack is here — and security is already the weak link
This issue covers four signal-rich developments from the first week of June 2026: O'Reilly's definitive six-layer agent stack map, an arXiv paper framing agentic engineering as a new discipline, the AgentRedBench security benchmark exposing attack-success rates of 32–81% across frontier models, and Google's iterative Agentic RAG shipping to enterprise preview.

研究速览
Three days into June 2026, the AI agentic ecosystem crossed a threshold that had been building for months: the infrastructure conversation stopped being theoretical. Frameworks released v1.0 production landmarks. Google shipped iterative retrieval into its enterprise platform. A benchmark exposed attack-success rates above 80% across the same frontier models now running inside corporate SaaS stacks. And a paper from a Chinese researcher made the philosophical case for a completely different way to think about software itself.
Here is what moved in the week of June 1–11.
Tools and frameworks: the agent stack gets a definitive map
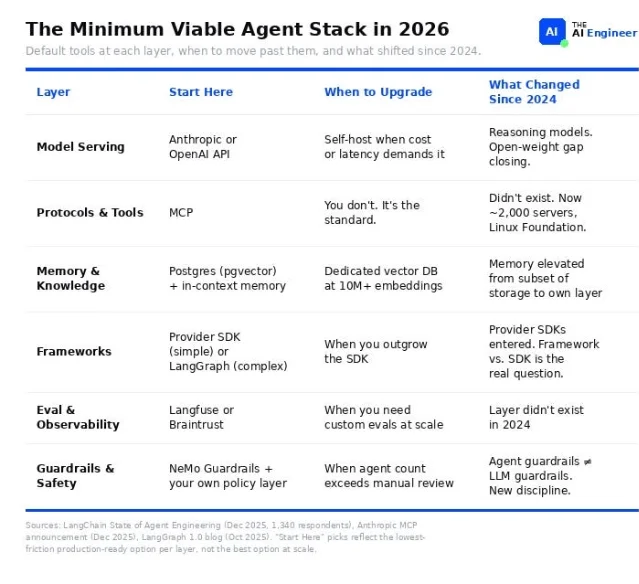
O'Reilly published Paolo Perrone's "The AI Agents Stack (2026 Edition)", the most comprehensive public architecture diagram since Letta's 2024 original. The framing is explicit: six layers now exist between an LLM and a production agent — models and inference, protocols and tools, memory and knowledge, frameworks and SDKs, eval and observability, guardrails and safety — and at least three of those layers did not exist as distinct categories when Letta drew the original diagram 14 months ago.1
Several data points from the piece deserve attention. MCP now has 97 million monthly SDK downloads and has been adopted by OpenAI, Google, and Microsoft, with Anthropic donating it to the Linux Foundation. LangGraph hit v1.0 in October 2025 and now runs in production at Uber, JPMorgan, LinkedIn, and Klarna. On eval, a LangChain survey found 89% of teams with production agents have observability, but only 52% have evals — a 37-point gap the piece calls "where production quality dies."1
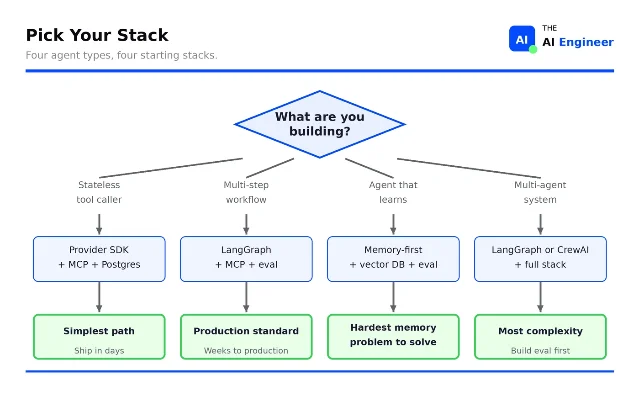
The most useful section is a decision flowchart that maps agent type to required layers: a stateless tool-caller needs a provider SDK, MCP, and Postgres; a multi-agent system needs the full stack with trace-level evals on every handoff. The argument for reading it now, not later: the framework you pick determines your migration cost, and provider SDKs are absorbing memory, tool calling, and basic eval into a single API. By early 2027, Perrone projects, most teams will get an "increasingly opinionated stack from their model provider."
Research: Agentic engineering as a new discipline — and its limits
A paper submitted to arXiv on June 4, 2026 makes the strongest version of a claim circulating in engineering circles: AI agents do not represent an improvement to software engineering, they represent its structural replacement.2
The author, Zhenfeng Cao, draws on complexity scaling arguments to formalize the distinction between traditional software (where code is the permanent carrier of decision logic) and agentic systems (where an LLM generates code at runtime as an ephemeral tool). The paper cites LangChain's pilot study deploying multi-agent swarms across 20+ enterprise debugging workflows, which reported a 93% reduction in root-cause identification time and savings of 200+ engineering hours in a single month — gains attributed not to better individual agents but to orchestration: shared context across agents, parallelized investigation, cross-validated findings.2
The paper does not claim the transition is complete. The EvoClaw benchmark, which tests agents on continuous software evolution (not isolated issue fixes), found that performance drops from over 80% on isolated tasks to at most 38% in continuous settings. The gap exposes four unresolved problems: context drift over long codebases, cascading error propagation across commits, no awareness of long-term technical debt, and incomplete verification fidelity. The author's four-stage roadmap places fully autonomous software development in Stage IV, labeled 2028+.
For practitioners, the relevant takeaway is Stage II (2025–2027): agents beginning to own complete tasks from specification to deployment, with humans shifting from implementation to specification and audit. Systems like Devin and OpenHands are the current exemplars.
Security: the numbers are worse than expected
A benchmark published June 1 — AgentRedBench — tested eight frontier models from Anthropic, OpenAI, and Google against 215 subtle indirect prompt injection scenarios across 24 enterprise integrations (Gmail, Salesforce, Jira, and 21 others).3
The headline finding: with no guards in place, attack success rates range from 32% (Claude Sonnet 4.6) to 81% (Gemini 3 Flash). The benchmark specifically targets "underspecified authorization" attacks — injections at the boundary of what a user's request actually authorizes — a category that existing benchmarks largely missed by replaying the same attack payloads across limited integrations.
The researchers also released AgentRedGuard alongside the benchmark: a guard trained on an integration-diverse corpus of adversarial tool-response content. The guard cuts panel-average attack success from 69.9% to 2.4% at a 0.37% false-positive rate, outperforming every open-source baseline (Llama Guard, PromptGuard 2, ProtectAI) on both metrics.3
This connects directly to the Endor Labs analysis cited in the O'Reilly stack piece: of 2,614 MCP servers analyzed, 82% were prone to path traversal and 67% to code injection. The protocol debate is settled (MCP won), but the security question is not. Builders deploying agents against live enterprise integrations should treat AgentRedBench as a procurement checklist, not a research curiosity.
| Model | No-guard attack success rate |
|---|---|
| Claude Sonnet 4.6 | 32% |
| Panel average | 69.9% (across 8 models) |
| Gemini 3 Flash | 81% |
| With AgentRedGuard | 2.4% |
Product and ecosystem: Google ships iterative RAG; Meta delays its next model
Google Research announced an agentic RAG framework now in public preview inside the Gemini Enterprise Agent Platform, branded as Cross-Corpus Retrieval.4 The key addition over standard multi-agent RAG is a Sufficient Context Agent: rather than generating a response when the first retrieval pass comes back incomplete, the agent writes a specific Reason and Feedback log naming the missing piece, then re-queries. On the FramesQA benchmark (824 queries, 2,676 PDF documents), the system answered 90.1% of questions correctly while routing across four distinct corpora — nearly matching its single-corpus accuracy, at within 3% latency.4 Reported factuality improvement versus standard RAG: up to 34%.
The enterprise use cases are multi-hop, multi-database scenarios: a doctor querying discharge medications, dietary restrictions, and allergy records from separate hospital systems; an engineering team tracing a server ID to specs in a different database. This is exactly the retrieval failure mode that single-step RAG was never designed to handle.

Meta delayed the release of its "Muse Spark" model/API for developers, according to Reuters and the Wall Street Journal.5 The delay is the latest in a pattern: frontier labs are now constrained not by model capability alone but by deployment reliability, safety validation, inference cost, and enterprise readiness. The timing is notable given that Anthropic filed a confidential S-1 with the SEC on June 1, with an annualized revenue run rate reported at $47 billion (up from $10 billion the prior year).6
Use cases: coding agents as the proof-of-concept layer
The O'Reilly stack piece devotes a section to coding agents — Cursor, Claude Code, Codex, Windsurf — as the clearest existing demonstration of all six stack layers working together in production.1 The points worth pulling out for builders:
- Inference layer: Cursor routes between Claude, GPT-4, and its own fine-tuned models by task type.
- Memory layer: Codebase-aware retrieval with reranking — not full-repo ingestion, but targeted file retrieval scoped to the specific edit.
- Eval layer: Cursor retrains its acceptance-rate model every 90 minutes based on whether users accept or reject suggestions. That is continuous production evaluation, not a quarterly review.
- Guardrails layer: Sandboxed execution — the agent can write and run code, but inside a container with restricted access.
The arXiv paper's four-stage roadmap puts current coding agents squarely in Stage I (tool-augmented), with the best performers beginning to enter Stage II (single-task autonomous). Lingma SWE-GPT 72B resolved 30.20% of GitHub issues on SWE-bench Verified — approaching GPT-4o's 31.80% while being fully open-weight. The 7B variant resolved 18.20%, a result the paper notes represents a 22.76% relative improvement over Llama 3.1 405B (a model nearly 6× larger) on the same benchmark.2
What to watch in the coming days
- MCP security: The OWASP MCP Top 10 (beta) is out — the first real security checklist for tool-connected agents. If you are shipping MCP servers to production, this is the practical companion to AgentRedBench.
- Chicago AI Week runs June 24–26 and will likely surface the next round of agentic product announcements.
- Anthropic's IPO timeline: With the S-1 filed and no offering date yet set, SEC review and market conditions are the next variables. Rival OpenAI is separately preparing a confidential filing.
- EvoClaw follow-on work: The 80%→38% performance cliff on continuous software evolution is the clearest gap in current agentic capability. Expect research activity here to accelerate through the summer.
参考来源
- 1The AI Agents Stack (2026 Edition) — O'Reilly
- 2The End of Software Engineering — arXiv:2606.05608
- 3AgentRedBench — arXiv:2606.02240
- 4Google Research Adds Agentic RAG to Gemini Enterprise Agent Platform — MarkTechPost
- 5Meta delays Muse Spark model release — Reuters
- 6AI by AI Weekly Top 5: June 1–7, 2026 — Champaign Magazine
围绕这条内容继续补充观点或上下文。