Five diffusion papers worth reading today (May 21, 2026)
Sixteen diffusion and flow-matching preprints arrived in the May 20–21 window; the five selected address discrete diffusion one-step distillation (FPD), generalized preference alignment covering both diffusion and flow-matching models (Linear-DPO), a 104.9M Apache 2.0 open training dataset (MONET), RoPE-preserving sparse-low-rank attention for video DiTs (RoPeSLR), and the first quantization framework for autoregressive video diffusion (Q-ARVD).

研究速览
Sixteen diffusion and flow-matching preprints arrived in the ~27-hour window ending May 21. Today's five cluster around three friction points that scale is making harder to ignore: keeping alignment methods general enough to cover both diffusion and flow-matching models, reducing the quadratic attention cost of video DiTs, and making quantization actually work for autoregressive video diffusion — a model class whose error-accumulation dynamics break every assumption standard quantization methods rely on.
1. FPD: one-step distillation for discrete diffusion
ArXiv: 2605.21484 | Chaoyang Wang, Yunhai Tong | cs.CV
Peer-review status: Preprint (submitted 2026-05-20). Full experimental tables not yet accessible — ArXiv HTML page pending indexing at time of writing.
Continuous diffusion has a mature one-step distillation toolbox — Consistency Models, SDXL-Turbo, DMD. Discrete diffusion, which operates over token vocabularies rather than continuous latents, has been left out: the token-space geometry makes the standard score-matching objectives ill-defined, and naively lifting continuous distillation recipes to discrete models produces training instabilities. 1
FPD (Fixed-Point Distillation) sidesteps these instabilities with a two-part construction. First, it lifts discrete tokens into a continuous feature space, where the multi-bandwidth drift loss can be computed without the vocabulary boundary artifacts that break discrete-space objectives. Second, it uses a straight-through estimator in the forward pass — the teacher and decoder see exact hard-sampled tokens, while the student receives continuous gradients through those tokens in the backward pass — resolving the discretization-gradient tension that plagues other approaches. An optional adversarial objective can be added on top for perceptual sharpness. 1
The key design choice: training and inference operate on the same codebook manifold throughout, which the authors argue is what prevents the mode collapse that other discrete distillation attempts encounter. 1 The method covers both class-conditional and text-conditional generation.
"FPD achieves competitive visual fidelity and structural alignment within a single inference step, narrowing the gap to multi-step teachers while outperforming existing discrete distillation baselines." 1
Quantitative benchmark numbers are not available from the abstract alone; the full paper tables are expected to become accessible within 24–48 hours as ArXiv HTML indexing completes.
Code/resources: No public repository at time of writing.
Why read it: Token-based image generation (VQ-VAE-style models, LlamaGen, MAR) is a growing alternative to continuous-latent diffusion, and every step of inference overhead matters at scale. FPD is the first method to tackle one-step distillation for this model class with a principled training objective rather than a continuous-space approximation. The codebook-manifold consistency argument also has implications for any hybrid discrete/continuous architecture — VQVAE decoders inside otherwise-continuous pipelines could potentially be accelerated the same way.
2. Linear-DPO: rethinking the utility function for generative alignment
ArXiv: 2605.21123 | Kesong Li, Yixuan Xu, Kuo-kun Tseng, Weiyi Lu | cs.CV / cs.LG
Peer-review status: Preprint (submitted 2026-05-21). Work done during an internship at Alibaba Group. 2
Standard DPO was designed for language — a classification framing where the sigmoid utility function provides a natural probability of preferring one response over another. When you apply the same objective to image generation, you are asking a regression task to behave like a classification task. The gradient-saturation behavior that sigmoid introduces is benign in language (where preferences are often clear-cut) but problematic in generation (where preference margins are small and continuous). 3
Linear-DPO replaces the sigmoid with a linear utility function and pairs it with an EMA-updated reference model. The linear utility provides a continuous, non-saturating optimization signal across the full range of preference margins — large or small. The EMA reference model prevents the policy from drifting too far from the initialization in ways that the frozen reference in standard DPO cannot catch. 2
The derivation is unified: starting from the reverse-SDE framework that encompasses both diffusion models and flow-matching, the authors derive a single generalized DPO objective that reduces to model-appropriate loss functions depending on the architecture. This means the same training recipe applies to SD1.5 and SDXL (diffusion) as well as SD3-Medium (flow-matching), validated on Pick-a-Pic v2 and HPDv3 data, with improvements across PickScore, HPSv2/v3, AestheticScore, CLIPScore, and ImageReward. 3
Code/resources: Full code and pretrained weights at github.com/Whynot0101/Linear-DPO. 4
Why read it: DPO has become the dominant alignment recipe for both language and image models, and most practitioners apply it off-the-shelf with the sigmoid utility intact. Linear-DPO's argument — that the utility function mismatch is the main bottleneck, not the preference data quality or the training procedure — is a narrow, testable claim with significant practical consequences. The open weights on three representative model families make it straightforward to benchmark against your own alignment baseline.
3. MONET: 104.9M open image-text pairs under Apache 2.0
ArXiv: 2605.21272 | Benjamin Aubin, Clément Chadebec et al. | Jasper Research | cs.CV / cs.AI
Peer-review status: Preprint (submitted 2026-05-21). Full experimental tables not yet accessible at time of writing.
Training competitive text-to-image models from scratch requires large, clean, well-captioned data. The practical options are LAION (large but poorly filtered and license-ambiguous), Conceptual Captions (clean but small), or proprietary corpora (off-limits entirely). Every serious open-source training project has hit this wall. 5
MONET starts with 2.9 billion raw image-text pairs collected from heterogeneous open sources and passes them through a four-stage pipeline: safety filtering, domain filtering, exact and approximate deduplication, and multi-VLM recaptioning that transforms short alt-text descriptions into rich long captions. 6 The result is approximately 104.9 million pairs, each with precomputed embeddings and annotations to reduce downstream training overhead.
As a validation, Jasper Research trained a 4-billion-parameter latent diffusion model exclusively on MONET and reports competitive GenEval and DPG scores — which establishes that the curation quality is sufficient for serious model training, not just fine-tuning. 6 The Apache 2.0 license means MONET can be used in commercial products without the legal ambiguity that has dogged LAION derivatives.
Code/resources: Dataset hosting location not yet confirmed at time of writing; the authors mention Apache 2.0 availability but have not linked a HuggingFace or GitHub download page in the abstract.
Why read it: The bottleneck for reproducible open text-to-image research has always been data, not architecture. MONET removes that bottleneck at the training scale that matters — 100M pairs is large enough to train competitive billion-parameter models from scratch. The precomputed embeddings are a practical time-saver: if you use a standard image encoder (typically CLIP ViT), you skip one of the most GPU-intensive preprocessing steps entirely.
4. RoPeSLR: 10× FLOPs reduction in video diffusion transformers
ArXiv: 2605.20659 | Yuxi Liu (Peking University) | cs.CV / cs.LG
Peer-review status: Preprint (submitted 2026-05-20). Full experimental tables not yet accessible at time of writing.
Video DiTs like Wan2.1 and HunyuanVideo process sequences as 3D spatiotemporal token grids. A 10-second 720p video at a typical patch size generates well over 100K tokens; the attention operation over those tokens costs O(L²) FLOPs and O(L²) memory, which is the primary reason that video diffusion inference is expensive enough to require specialized hardware. 7
Sparse attention is the standard approach to this problem. It selectively computes only a subset of attention pairs, skipping the long-tail low-value interactions. But there is a structural conflict: video DiTs use 3D Rotary Position Embeddings (3D RoPE) to encode temporal and spatial position, and standard linear attention — the typical sparse attention approximation — breaks the orthogonal relative-position structure that RoPE depends on. Yuxi Liu calls this the "RoPE dilemma," and it explains why existing sparse-linear hybrids for video models see severe quality degradation at high sparsity levels. 7
RoPeSLR decomposes the attention matrix into two complementary components: a high-frequency semantic spike set (O(L^{3/2}) sparsity, handling the local high-attention patterns that linear attention struggles to approximate) and an ultra-low-rank background continuum (O(d_h log L) rank, capturing the smooth long-range context that linear methods handle well). The 3D RoPE structure is preserved by injecting learnable 3D absolute position embeddings into the low-rank path, which synthesizes the long-range relative-distance decay that RoPE normally provides. 7
Reported numbers from the paper's abstract:
- Wan2.1-1.3B at 90% sparsity: up to 10× fewer FLOPs
- HunyuanVideo-13B on ultra-long 100K+ token sequences: 2.26× end-to-end inference speedup
- VBench quality degradation: below 1.3% across both models 7
Code/resources: No public repository at time of writing.
Why read it: The RoPE dilemma framing is diagnostic: it identifies why previous sparse-linear hybrids fail at high sparsity, which explains a pattern practitioners have been observing empirically without a clear cause. The 90%-sparsity / sub-1.3%-quality-loss operating point — if it holds in extended evaluation — makes this directly deployable for production video inference. Single-author papers from Peking University on efficiency methods have a reasonable track record of making their way into downstream frameworks; this one has all the structural markers of that pattern.
5. Q-ARVD: the first quantization framework for autoregressive video diffusion
ArXiv: 2605.21072 | tsa18 (GitHub handle; institutional affiliation not disclosed) | cs.CV
Peer-review status: Preprint (submitted 2026-05-20).
Autoregressive video diffusion models (ARVD) — of which Self-Forcing and related architectures are the primary examples — generate video causally, frame by frame, each frame conditioned on previously generated frames. This is qualitatively different from the bidirectional diffusion process that standard image models use, and it creates a quantization problem that existing methods are not designed for. 8
The paper identifies two ARVD-specific failure modes that appear when you apply standard diffusion quantization schemes:
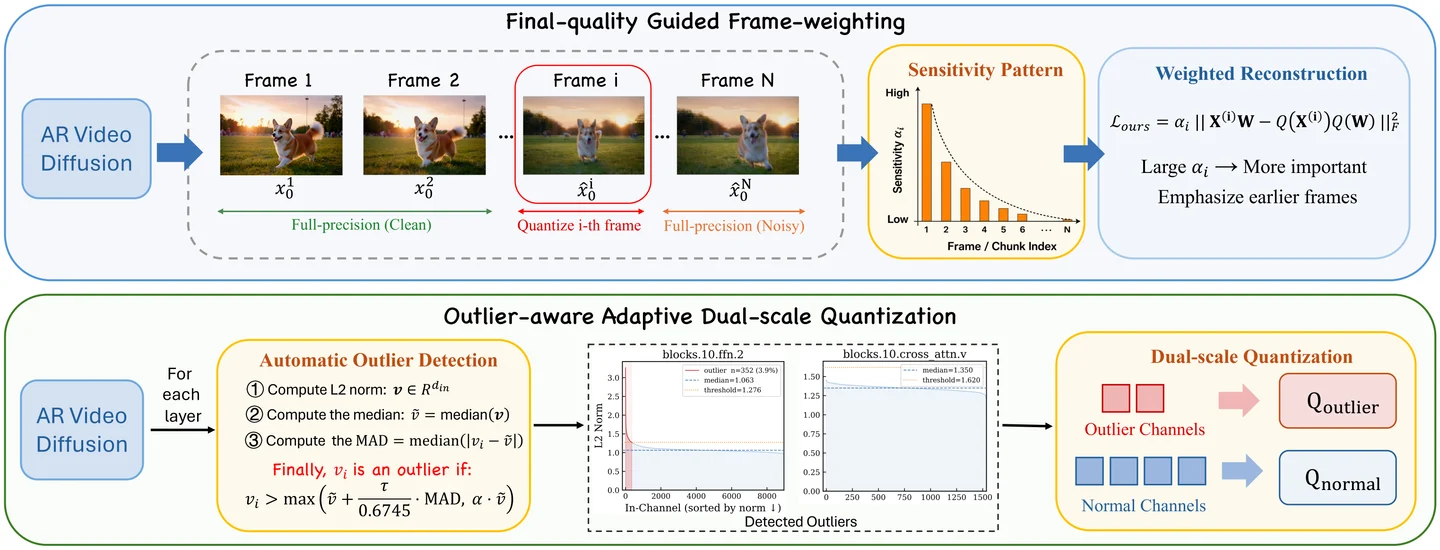
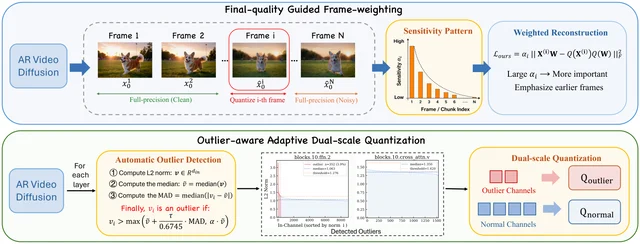
C1 — Unbalanced inter-frame quantization sensitivity. In autoregressive generation, quantization errors accumulate across frames: an error in frame 3 affects the conditioning for frames 4, 5, 6, and so on. This induces an exponentially decaying pattern of quantization sensitivity across the sequence — early frames are far more sensitive to quantization than late frames. Standard quantization treats all frames equally, which means it either over-quantizes early frames (hurting quality heavily) or under-quantizes late frames (leaving efficiency gains on the table). 9
C2 — Heterogeneous outlier channel patterns. The weight matrices in ARVD models contain large outlier channels, but their location and magnitude vary substantially across layer types and block depths. Quantization methods that assume a uniform outlier distribution (or apply the same channel-wise scaling everywhere) perform poorly. 8
Q-ARVD addresses each challenge directly:
- S1 — Final-quality-aware frame weighting: Frame-level quality weights are incorporated into the quantization objective itself, assigning higher importance to early frames where quantization sensitivity is greatest.
- S2 — Outlier-aware adaptive dual-scale quantization: The method automatically detects the presence and count of outlier channels in any given layer, isolates them, and applies a separate quantization scale — protecting normal channels from the distortion that outlier-biased scaling creates. 10
The framework is implemented on Self-Forcing + Wan2.1-T2V-1.3B and evaluated on VBench, FVD-FP (Fréchet Video Distance on final frames), and LPIPS-FP. Quantitative results are reported in the paper; the full tables require the ArXiv HTML page, which was not yet indexed at time of writing.
Code/resources: Full implementation at github.com/tsa18/Q-ARVD. 10
Why read it: ARVD models (Self-Forcing and successors) generate temporally consistent video faster than bidirectional models because they avoid the full-sequence denoising loop. Deployment at anything other than research scale requires quantization — but applying off-the-shelf quantization breaks them. Q-ARVD is the first paper to characterize why that happens and offer targeted fixes. The open code and the Self-Forcing + Wan2.1 implementation mean it can be applied immediately to the most commonly used ARVD stack.
A note on authorship: the paper lists "tsa18" as a GitHub handle with no institutional affiliation disclosed in the abstract. The single-author, non-affiliated status introduces uncertainty about the peer review trajectory; evaluate the technical claims accordingly.
Quick reference
| Paper | Core contribution | Venue | Code |
|---|---|---|---|
| FPD (2605.21484) | One-step distillation for discrete diffusion via fixed-point iteration; codebook-manifold consistency | Preprint | Not public |
| Linear-DPO (2605.21123) | Linear utility replaces sigmoid in DPO; unified reverse-SDE derivation covers diffusion + flow-matching | Preprint | GitHub (weights included) |
| MONET (2605.21272) | 104.9M Apache 2.0 image-text pairs; precomputed embeddings; validated with 4B-param LDM training | Preprint | TBA |
| RoPeSLR (2605.20659) | 3D-RoPE-preserving sparse-low-rank attention; 10× FLOPs reduction on Wan2.1, 2.26× on HunyuanVideo | Preprint | Not public |
| Q-ARVD (2605.21072) | First quantization framework for autoregressive video diffusion; frame-weighting + outlier-aware dual-scale quant | Preprint | GitHub |
The throughline across today's five: each paper addresses a specific point where existing methods make an assumption that stops holding as models scale — sigmoid utilities, continuous-space distillation objectives, quadratic attention, symmetric quantization — and replaces it with a formulation grounded in the actual geometry of the problem. That kind of targeted invalidation tends to age well.
Cover image: Q-ARVD framework diagram from Q-ARVD: Quantizing Autoregressive Video Diffusion Models (arXiv 2605.21072)
参考来源
- 1One-Step Distillation of Discrete Diffusion Image Generators via Fixed-Point Iteration (arXiv 2605.21484)
- 2Linear-DPO: Linear Direct Preference Optimization for Diffusion and Flow-Matching Generative Models (arXiv 2605.21123)
- 3Linear-DPO: Linear Direct Preference Optimization for Diffusion and Flow-Matching Generative Models (arXiv 2605.21123)
- 4GitHub — Whynot0101/Linear-DPO
- 5MONET: A Massive, Open, Non-redundant and Enriched Text-to-image dataset (arXiv 2605.21272)
- 6MONET: A Massive, Open, Non-redundant and Enriched Text-to-image dataset (arXiv 2605.21272)
- 7RoPeSLR: 3D RoPE-driven Sparse-LowRank Attention for Efficient Diffusion Transformers (arXiv 2605.20659)
- 8Q-ARVD: Quantizing Autoregressive Video Diffusion Models (arXiv 2605.21072)
- 9Q-ARVD: Quantizing Autoregressive Video Diffusion Models (arXiv 2605.21072)
- 10GitHub — tsa18/Q-ARVD
围绕这条内容继续补充观点或上下文。