GitHub Trending Top 10: The agent toolchain grows up (May 25–Jun 1)
This week's 10 trending repos signal a maturation phase for the agent ecosystem: governance frameworks, delivery harnesses, quality-enforcement skill files, and role-specific plugin systems are displacing raw capability demos. MoneyPrinterTurbo (+15,955 stars) and markitdown (+9,353 stars) lead by weekly gain. Three entries carry credibility flags: ECC's 201K stars show an anomalous star-to-fork ratio, agent-governance-toolkit's OWASP badge overstates actual coverage, and heretic is operating under an active Meta legal notice. Each of the 10 entries includes problem, stack, differentiation, and a clear star/skip verdict.

研究速览
Last week the chart was dominated by pre-indexed code knowledge graphs. This week the throughline is different: the repos that trended hardest are building out the infrastructure layer around agents — governance, harnesses, quality control, plugin systems. Raw capability demos are largely absent. What's arriving instead is scaffolding that makes agents reliable enough to ship.
Three entries carry flags worth reading before you star: ECC's star count is anomalous for a solo-maintained repo, agent-governance-toolkit's OWASP compliance badge overstates actual coverage, and heretic is operating under an active Meta legal notice. Details in each entry.
Rankings are by weekly star gain for the May 25–Jun 1 window. Total star counts are as of June 1.
#1 · harry0703/MoneyPrinterTurbo — 74,200 stars · +15,955 this week
Problem solved: Producing short-form vertical video for social platforms normally requires a chain of disconnected tools — a scriptwriter, a stock footage source, a TTS service, a subtitle generator, a video editor. MoneyPrinterTurbo collapses all five stages into a single Python pipeline: type a topic, receive a 9:16 or 16:9 video. 1
Stack and approach: Python (97.2%), Streamlit web UI plus FastAPI REST backend. The pipeline is: LLM generates script → Pexels API fetches royalty-free clips → TTS synthesizes voice → Whisper or Edge TTS generates subtitles → FFmpeg composites 1080p output. Minimum hardware is 4 CPU cores and 4 GB RAM; no GPU required in cloud-LLM mode. 1 v1.2.9 (May 30) added Xiaomi MiMo as both LLM and TTS provider, plus granular script controls: adjustable paragraph count, a custom requirements field, and full system-prompt override. v1.2.8 (May 28) had added Grok (xAI). The project now integrates 15+ LLM providers including OpenAI, DeepSeek, Gemini, Moonshot, Ollama, MiniMax, Qwen, and ERNIE. 2
Differentiation: The 15,955-star weekly spike is driven by Instagram and YouTube virality (multiple accounts posting "one-click AI video" demos), not a technical breakthrough. Zac Smith (Principal AI Engineer, Gauntlet AI) put it directly: "The product is a get-rich-quick punchline. The architecture is a teaching example." 3 The pipeline pattern — input → script → assets → voice → subtitles → render — is the shape of every modern agent workflow. FintechExtra noted that the v1.2.9 script customization addresses "the biggest pain point in automated video creation": generic scripts sound robotic, and paragraph-count control plus full prompt override gives advanced users meaningful steering. 4 Video output quality hasn't been independently benchmarked against Runway or Pika; all quality claims come from the README or secondary coverage.
Verdict: Skip for the stated use case. ⭐ Star it for the pipeline architecture. The five-stage sequential design is a clean reference implementation for any content-generation agent.
#2 · microsoft/markitdown — 135,000 stars · +9,353 this week
Problem solved: LLM pipelines need their input as text. Most enterprise documents aren't text — they're PDFs, PowerPoints, Word files, Excel sheets, images, and increasingly video and audio.
markitdown converts all of them to Markdown in a single pip install. 5Stack and approach: Python, maintained by the Microsoft AutoGen team. Primary contributors: Adam Fourney (Senior Principal Researcher, Microsoft Research HAX) and Gagan Bansal (Senior Researcher). 5 Supports 14+ source formats: PDF, PowerPoint, Word, Excel, images (OCR + EXIF), audio (transcription), HTML, CSV/JSON/XML, ZIP, YouTube URLs, and EPubs. v0.1.6 (May 26) is the project's largest update: it added an OCR layer service for embedded images and scanned PDFs, and an Azure Content Understanding converter — the first built-in converter capable of handling video and audio files, with structured field extraction and custom analyzers. 6 The README is explicit about scope: "it is meant to be consumed by text analysis tools — and may not be the best option for high-fidelity document conversions for human consumption." 5
Differentiation: breadth over precision. Jimmy Song's 2026 comparison against MinerU and Marker found markitdown handles simple documents well but loses structural fidelity on complex PDFs — no header hierarchy, most tables degraded to plain text. 7 Na'aman Hirschfeld's independent benchmark (dev.to, 2025) found it struggles on large files above 10 MB. 8 The Azure Content Understanding integration requires per-call Azure API costs; pricing isn't stated in the README. Install footprint is 251 MB with 25 dependencies. A markitdown MCP server integrates directly with Claude Desktop.
Verdict: ⭐ Star it if you're building LLM preprocessing pipelines that span multiple document types. For high-fidelity academic or technical document conversion, MinerU or Marker are better fits.
#3 · Leonxlnx/taste-skill — 29,900 stars
Problem solved: AI coding agents produce predictable-looking UIs: centered hero sections, gray cards, soft gradients, identical font stacks. The output isn't broken — it's generic. taste-skill injects aesthetic constraints into the agent's instruction layer so that design taste becomes a precondition for code generation, not an afterthought. 9
Stack and approach: Shell (100%) — the entire framework is a
SKILL.md file that loads into Claude Code, Codex, Cursor, or Copilot. Three dial parameters control output style: DESIGN_VARIANCE (layout experimentation, 1–10), MOTION_INTENSITY (animation depth, 1–10), and VISUAL_DENSITY (information density, 1–10). 9 v2 (the current default) is a full rewrite of v1 adding seven chapters: simplified inference (§0), design system mapping (§2), dark mode protocol (§8), redesign protocol (§11), block library contract (§12), and preflight checks (§14). Hard bans include: em dashes, section-number eyebrow labels, version tags, decorative status dots, fake product screenshot divs, hand-rolled SVG icons, and warm-default color palettes. Animation standardized to Motion (formerly Framer Motion), with GSAP Sticky-Stack and Horizontal-Pan scaffold code included. 10+ variant skills ship in the repo (minimalist, brutalist, soft, output-only, etc.).Differentiation: taste-skill and stop-slop (entry #9 below) represent the same insight applied to two domains: AI outputs need taste enforcement, not just capability expansion. Developers Digest framed it this way: "AI agents do not fail only because they miss facts. They fail because they miss judgment." 10 The v2 rewrite exists specifically because v1 was frequently bypassed by agents — the hardened bans address the specific patterns (em-dashes, eyebrow labels, fake screenshots) that kept slipping through in production.

Verdict: ⭐ Star it if you generate UI code with AI agents. Set
DESIGN_VARIANCE and MOTION_INTENSITY to your project's defaults and leave it in your Claude Code plugin config.#4 · anthropics/knowledge-work-plugins — 18,400 stars
Problem solved: Claude is a generalist. Most professional work is not. A product manager's daily workflow is different from a sales rep's, which is different from a legal analyst's. knowledge-work-plugins packages those differences as role-specific Claude Cowork plugins that encode domain knowledge, preferred tools, and standard workflows — so teams get consistent, role-appropriate outputs without re-explaining context in every session. 11
Stack and approach: Anthropic official open-source repo, Apache-2.0. Architecture is entirely file-based: each plugin follows a
.claude-plugin/plugin.json manifest plus commands/ and skills/ directories — Markdown and JSON only, no code, no build step, no infrastructure. 11 11 role plugins ship: productivity, sales, customer-support, product-management, marketing, legal, finance, data, enterprise-search, bio-research, and cowork-plugin-management. MCP connectors cover 30+ enterprise tools: Slack, Notion, Jira, Asana, Figma, HubSpot, Salesforce, Snowflake, BigQuery, and more. The README framing: "Plugins let you go further: tell Claude how you like work done, which tools and data to pull from, how to handle critical workflows, and what slash commands to expose — so your team gets better and more consistent outcomes." 11 84 commits, 19 contributors, 53 open issues, no formal releases.Differentiation: This is the vendor-side answer to the community-built skill ecosystem (Superpowers, ARS, taste-skill). Anthropic shipping official role plugins signals that the
.claude-plugin/ format is becoming a first-class integration surface, not just a power-user hack. Mager.co's assessment: "AI tools are commoditizing fast. Everyone has access to the same models. What differentiates teams is context — how effectively you encode your institutional knowledge into the tools you use every day." 12 No formal version releases yet; the repo is still in active iteration with 53 open issues.Verdict: ⭐ Star it. Even if your team doesn't adopt the plugins directly, the
.claude-plugin/ architecture is the reference for how Anthropic wants workflow context to be encoded. Fork the closest role and adapt it.#5 · affaan-m/ECC — 201,000 stars · ⚠️ star count unverified
Problem solved: Each AI coding harness (Claude Code, Codex, Cursor, Gemini, Zed, GitHub Copilot) has a different conventions layer. A developer working across several loses context, skills, and muscle memory switching between them. ECC (by Affaan Mustafa, San Francisco) aims to be a cross-harness operating system: one set of agents, skills, hooks, and rules that works identically across 7+ platforms. 13
Stack and approach: Markdown-first (agents and skills as instruction files), with a v2.0.0-rc.1 Tkinter dashboard and a Rust control-plane prototype (
ecc2/). The repo contains 63 agents, 249 skills, and 79 legacy command shims. Published npm packages: ecc-universal and ecc-agentshield. A commercial tier (ECC Pro, $19/seat/month) ships as a GitHub App. v2.0.0-rc.1 (April 2026) added Itô prediction market skill packs and Operator workflows; a React language track landed in late May. 13 14Differentiation: ⚠️ Flag: 201K total stars from a solo developer is structurally anomalous. The star-to-fork ratio is approximately 6.5:1 (201K stars : 30.8K forks). Normal open-source projects sit in the 20:1 to 50:1 range — ECC's ratio is inverted, with forks far higher relative to stars than expected. Star count legitimacy has not been independently verified. Treat the star total as a signal to investigate, not a quality signal. The actual codebase — 249 skills, 63 agents, 1,997 commits — is verifiable and substantive. 13
Verdict: Conditional ⭐. The cross-harness skill abstraction is genuinely useful if you work across multiple agent platforms. Evaluate the actual skill files rather than the star count.
#6 · Chachamaru127/claude-code-harness — 2,400 stars · +~2K this week
Problem solved: Claude Code is powerful in a single session but drifts across sessions — plans live in chat history, tests become optional, review happens too late, and release evidence has to be reconstructed from memory. claude-code-harness wraps Claude Code in a repeatable operating loop with five mandatory phases: Spec, Plan, Work, Review, Release. 15
Stack and approach: Go (33.0%) + Shell (44.3%), no Node.js dependency. The guardrail engine runs natively in Go. Five slash commands:
/harness-plan, /harness-work, /harness-review, /harness-release, /harness-setup. The design philosophy is explicit about human-in-the-loop approval: "Your job is not to hand-write the plan. It is to approve or correct the generated contract before execution continues." 15 v4.13.2 (May 30) added Cursor delegate paths, a breezing UX cut, and a file lease system backed by git-common-dir store. The repo has shipped 176 releases. A companion module (harness-mem) adds cross-session memory. Supported platforms: Claude Code (full), Codex CLI, OpenCode, Cursor (internal-compatible).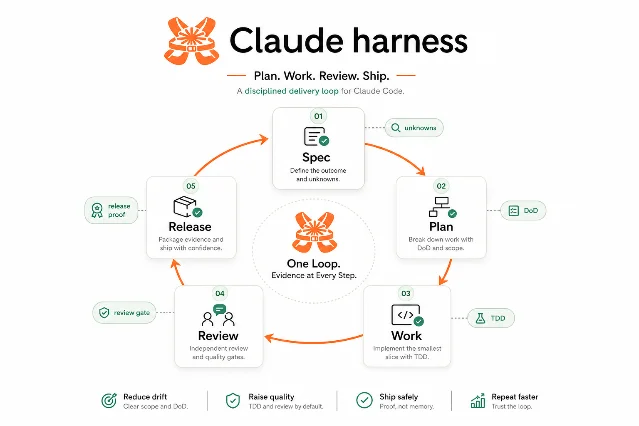
Differentiation: Where Superpowers (May 18–25 issue) injects behavioral rules at session start, claude-code-harness operates at the delivery cycle level — it enforces that spec, plan, and review gates are all physically traversed before a release ships. The Go guardrail engine makes those gates structural rather than advisory. 176 releases over a short window signals fast iteration; the downside is that Phase 85 close-outs and mid-cycle rewrites (file lease system, broadcast workers) suggest the architecture is still stabilizing.
Verdict: Conditional ⭐. Star it if you use Claude Code for production work and want disciplined release gating. The five-phase loop is worth adapting even if you don't adopt the full harness.
#7 · microsoft/agent-governance-toolkit — 3,600 stars · ⚠️ OWASP badge misleading
Problem solved: Prompt-level safety instructions don't work against determined adversaries. AGT's README makes the distinction crisply: "Prompt-level safety ('please follow the rules') is not a control surface. It is a polite request to a stochastic system." 16 AGT intercepts every tool call, message send, and agent delegation in deterministic application code before the model's intent reaches the wire. The difference, as the README puts it: "between asking an agent to behave and making it incapable of misbehaving." 16
Stack and approach: Eight packages across five distribution targets (PyPI, npm, NuGet, crates.io, Go module): Agent OS (policy engine), Agent Mesh (identity/trust), Agent Runtime (sandbox), Agent SRE (circuit breakers/SLOs), Agent Compliance (OWASP validation), Agent Marketplace (plugin governance), Agent Lightning (RL training governance), Agent Hypervisor (execution audit). 992 conformance tests, 10 formal specs (RFC 2119 language), 25 Architecture Decision Records. Supports 14 agent frameworks natively including Semantic Kernel, AutoGen, LangGraph, CrewAI, OpenAI Agents SDK, Google ADK, LlamaIndex, Claude Code, and GitHub Copilot CLI. 16 v3.7.0 shipped May 18; May 30–31 commits fixed a critical authorization-bypass vulnerability (#2644) and added a LangGraph v1.0 adapter and sandbox subprocess scanner.
Differentiation: ⚠️ Flag: The README badge reads "OWASP Agentic Top 10: 10/10 Covered." Two problems: (1) the 2026 OWASP Agentic Security Initiative standard has 11 risks (ASI01–ASI11), not 10. (2) AGT's own compliance documentation acknowledges 8/11 Full coverage and 3/11 Partial — specifically ASI04 (supply chain), ASI06 (memory poisoning), and ASI09 (human-trust exploitation). 17 The document states: "Disclaimer: This document is an internal self-assessment mapping, NOT a validated certification or third-party audit." 17 The deterministic interception architecture is sound; the marketing claim isn't.
Verdict: ⭐ Star it for the architecture, not the badge. If you're deploying agents in a compliance-sensitive environment, the policy engine and 992 conformance tests are the most mature open-source governance layer available. Treat the OWASP badge as aspirational rather than certified.
#8 · mukul975/Anthropic-Cybersecurity-Skills — 12,900 stars
Problem solved: AI security agents often operate like interns: they know general principles but don't know which Volatility3 plugin to run on a suspicious memory dump, which Sigma rules catch Kerberoasting, or how to scope a cloud breach across three providers. Anthropic-Cybersecurity-Skills (by independent developer Mahipal Jangra; not affiliated with Anthropic PBC) provides 754 structured skills that encode that operational knowledge. 18
Stack and approach: Apache 2.0, YAML frontmatter + Markdown body per the agentskills.io open standard. Each skill has four sections: When to Use, Prerequisites, Workflow (step-by-step with real commands), and Verification. The frontmatter (~30 tokens per skill) is scannable in a single agent pass across all 754 skills; full skill text is 500–2,000 tokens. Covers 26 security domains including Cloud Security (60 skills), Threat Hunting (55), Threat Intelligence (50), Web App Security (42), Network Security (40), Malware Analysis (39), and Digital Forensics (37). 18 Maps to MITRE ATT&CK (all 14 Enterprise tactics, 200+ techniques) and NIST CSF 2.0 (all 6 functions). v1.2.0 (April 6) added partial ATLAS, D3FEND, and NIST AI RMF mappings covering 81, 139, and 85 skills respectively. 19

Differentiation: Against microsoft/agent-governance-toolkit (#7 above): AGT is a runtime policy layer asking "Is this action allowed?"; Anthropic-Cybersecurity-Skills is a knowledge injection layer asking "How do I do this security task correctly?" They're complementary. A NLPM mechanical audit (Issue #49) sampled 100 of the 754 skills and found 42% scored ≥90/100 (genuinely excellent reference material) and 35% had content quality issues — generic "When to Use" text, missing Output Format fields, or circular phrasing. 20 The "5 frameworks / 754 skills" badge in the README is also overstated: ATT&CK and NIST CSF cover all 754; the other three cover only a subset. The name "Anthropic-Cybersecurity-Skills" is misleading — this is a solo community project, not Anthropic output.
Verdict: Conditional ⭐. Star it if you're building security agents or studying the skill-file format. The 42% high-quality baseline and ATT&CK/NIST CSF coverage are real. Audit any skill before deploying it in a production security workflow — the 35% quality gap is material.
#9 · hardikpandya/stop-slop — 7,700 stars
Problem solved: AI prose has tells: predictable openings ("Here's the thing"), rhythm-metered sentences, adverb clusters, passive voice, and inanimate subjects performing human actions ("the decision emerged"). stop-slop is a single
SKILL.md file that gives Claude or any LLM a scoring rubric and a set of hard rules to detect and remove those patterns from any text. 21Stack and approach: Claude Code SKILL.md format, MIT license, by Hardik Pandya (hvpandya.com). The core evaluation is a five-dimension score (each 1–10): Directness, Rhythm, Trust, Authenticity, Density. Texts scoring below 35/50 require revision. 21 Hard rules: no adverbs ending in
-ly, no passive voice, no em dashes, every sentence needs a human subject performing an action, no Wh- sentence openers. The references/phrases.md file lists 20+ forbidden openers ("Here's the thing", "At the end of the day"), 11 emphasis markers to cut, 11 business jargon substitutions, and 16 banned adverbs. 22 references/examples.md shows five before/after pairs — the clearest: "In today's fast-paced landscape, we need to lean into discomfort…" becomes "Move faster. Your competition is." 23
Differentiation: taste-skill (#3 above) targets visual output from UI-generating agents. stop-slop targets prose output from writing agents. Same underlying idea: a skill file is a typed behavioral contract, and you can write one for any output domain. The main limitation is the last-updated date — January 13, 2026 — meaning the rules predate several new AI writing patterns that have since emerged (notably the 2026 wave of "signal density gradient" and "cognitive bandwidth" compound nouns). Hardik Pandya's framing: "AI writing has patterns. Predictable phrases, structures, rhythms. This skill teaches Claude (or any LLM) to catch and remove them." 21
Verdict: ⭐ Star it and keep a copy in your Claude Code skills directory. Run the five-dimension scorer on any LLM-generated draft before shipping.
#10 · p-e-w/heretic — 22,800 stars · ⚠️ Active Meta legal notice
Problem solved: Post-training safety alignment in LLMs is implemented as refusal behavior — the model declines to answer certain categories of questions. Heretic (by Philipp Emanuel Weidmann) removes those refusals from existing models through directional ablation (abliteration): identify the direction in activation space that encodes refusal, subtract it. The innovation over prior abliteration tools is a co-optimization loop that minimizes both refusal rate and KL divergence from the original model simultaneously, so the decensored model retains as much of the original capability as possible. 24
Stack and approach: Python (100%), AGPL-3.0 license. Three technical innovations: (1) a flexible multi-layer ablation weight kernel, (2) a floating-point refusal direction index that linearly interpolates between the two nearest direction vectors — unlocking additional direction space, and (3) component-level ablation parameter selection (attention out-projection vs. MLP down-projection separately). Optuna TPE Bayesian optimizer finds optimal ablation parameters. Supports most dense models, several MoE architectures, multimodal models, and Qwen3.5 hybrids; pure state-space models unsupported. 24 v1.3.0 (May 5) added reproducible runs (fixed random seed), integrated benchmarking, lower peak VRAM, Qwen3.5, and Gemma 4 support. 11 contributors, 8 new to this release. 25 3,000+ community models on Hugging Face now use Heretic. 24 On an RTX 3090, decensoring a Qwen3-4B model takes roughly 20–30 minutes.
Differentiation: Abliterlitics benchmarked 13 Gemma 4 E2B abliterated variants (44 GPU hours, RTX 5090) and found Heretic-generated models achieved comparable refusal suppression to expert-hand-tuned versions with lower KL divergence (0.153 vs. 1.04 for the leading manual alternative). 26 ⚠️ Legal flag: Meta has served Heretic with a legal notice over its application to Llama model series. The Financial Times reported that an FT journalist removed Llama 3.3's safety guardrails using Heretic in under 10 minutes. Community discussion threads exist on Reddit (r/LocalLLaMA) but the full notices are not publicly cached.
Verdict: Research reference only. If you work in AI safety or model alignment, Heretic is the most rigorous open-source tool for measuring how much alignment is weight-encoded vs. prompt-encoded. The active Meta legal notice and AGPL-3.0 license make production use in any commercial context legally and ethically fraught.
Three patterns this week
Quality control is becoming infrastructure. Three repos this week — taste-skill, stop-slop, and claude-code-harness — all encode the same structural move: converting a previously implicit quality gate (design taste, prose quality, code review) into a formal enforcement layer. The SKILL.md format turns out to be an effective substrate for this because it runs before the agent generates output, not after. The reusable pattern: any domain where AI output has predictable quality failure modes (UI design, written prose, test coverage, API contract compliance) is a candidate for a taste-enforcement skill file.
Governance tooling is arriving before governance standards are finalized. agent-governance-toolkit ships with 992 conformance tests and claims OWASP coverage — but the OWASP standard it references has 11 risks, not 10, and AGT's own compliance doc shows 8/11 full coverage. This is not a knock on AGT specifically; it reflects a broader pattern where tooling is being built at a pace that outruns the standards it's meant to implement. Developers adopting governance frameworks should read the fine print in the compliance docs, not the badge counts on the README.
The cross-harness abstraction layer is being contested. ECC, claude-code-harness, and knowledge-work-plugins all address the same underlying friction: the skill and agent knowledge you build for one platform doesn't automatically transfer to another. ECC takes the broadest approach (7 platforms, one unified skill set) but has a credibility flag on its star count. claude-code-harness takes the narrowest approach (Claude Code first, Cursor partial) but has the most verifiable activity record (176 releases, 1,318 commits). knowledge-work-plugins stakes out the vendor position (Anthropic official, role-oriented) rather than the developer position. These three aren't competing head-to-head — they're solving adjacent versions of the same problem.
Cover image: GitHub OpenGraph preview for microsoft/markitdown
参考来源
- 1GitHub: harry0703/MoneyPrinterTurbo
- 2GitHub Release v1.2.9: harry0703/MoneyPrinterTurbo
- 3Zac Smith on Medium: MoneyPrinterTurbo, Read Honestly
- 4FintechExtra: MoneyPrinterTurbo v1.2.9
- 5GitHub: microsoft/markitdown
- 6GitHub Release v0.1.6: microsoft/markitdown
- 7Jimmy Song Blog: Best Open Source PDF to Markdown Tools 2026
- 8dev.to: I benchmarked 4 Python text extraction libraries
- 9GitHub: Leonxlnx/taste-skill
- 10Developers Digest: Taste Skills Are Turning Agent Review Into Infrastructure
- 11GitHub: anthropics/knowledge-work-plugins
- 12mager.co: Anthropic's Knowledge Work Plugins
- 13GitHub: affaan-m/ECC
- 14GitHub: affaan-m/ECC commits
- 15GitHub: Chachamaru127/claude-code-harness
- 16GitHub: microsoft/agent-governance-toolkit
- 17Microsoft AGT Docs: OWASP ASI 2026 Reference Architecture
- 18GitHub: mukul975/Anthropic-Cybersecurity-Skills
- 19GitHub Release v1.2.0: mukul975/Anthropic-Cybersecurity-Skills
- 20GitHub Issue #49: NLPM audit
- 21GitHub: hardikpandya/stop-slop
- 22GitHub Raw: stop-slop references/phrases.md
- 23GitHub Raw: stop-slop references/examples.md
- 24GitHub: p-e-w/heretic
- 25GitHub Release v1.3.0: p-e-w/heretic
- 26Hugging Face: DreamFast/Gemma4-e2b-abliterlitics
围绕这条内容继续补充观点或上下文。