Weekly YouTube Digest — May 25–Jun 1, 2026
5 videos this week: Cursor's Composer 2.5 beats frontier models at 1/20th the cost, Anthropic drops Opus 4.8 with parallel sub-agents, the Pope publishes a 40,000-word AI manifesto with an Anthropic co-founder in attendance, Lex Fridman goes 3 hours deep on physics with a Fermilab particle physicist, and Microsoft Research introduces an LM fine-tuning method that outperforms both SFT and RLVR without a reward model.

This week's digest covers five videos from May 25–June 1, 2026 across Matthew Berman, Lex Fridman, and Microsoft Research. Cursor's in-house coding model quietly became the best value in the field, Anthropic dropped two model updates in the same week, the Pope published a 40,000-word AI manifesto, and Lex Fridman sat down with a Fermilab physicist for nearly three hours of physics. There's also a new post-training technique from Microsoft Research that beats both SFT and RLVR on long-horizon tasks — without needing a custom reward model.
Cursor just beat EVERYONE.
正在加载内容卡片…
Channel: Matthew Berman · Published: May 26 · Duration: 31 min
Berman makes the case that Cursor's Composer 2.5 is now the best coding model by price-to-performance ratio. On Cursor's internal benchmark, it scores roughly 64% — about 1.5 percentage points below the frontier (Opus 4.7 at ~65%, GPT-5.5 at ~65%) — but costs around $0.50 per task versus $11 for the frontier options 1. The model is built on Moonshot's Kimi K2.5 open-source base and trained with 25× more synthetic tasks than its predecessor, using RL with text feedback. It's only available inside Cursor, not via API.
A larger story runs underneath the model launch: SpaceX AI is acquiring Cursor after its IPO (valued at $60B), and is simultaneously supplying Anthropic with Colossus compute at $1.25B per month. Berman's read is that Elon Musk now holds the only position combining frontier compute, energy infrastructure, and a capable coding model team — but lacks the real-world usage data and model feedback loops that Anthropic and OpenAI have built over years of production deployments.
The main practical takeaway: for most enterprise coding tasks, the Frontier tier is expensive overkill. Berman argues that a "workhorse model" like Composer 2.5 or Gemini 3.5 Flash handles the majority of real use cases, with frontier-class models reserved for the initial planning and decomposition step.
Worth watching? Yes, if you track AI coding tools or want Berman's breakdown of the SpaceX/Cursor/Anthropic compute triangle. Skip if you've already seen his earlier Composer 2.5 mention from last week.
Anthropic just dropped Opus 4.8
正在加载内容卡片…
Channel: Matthew Berman · Published: May 29 · Duration: 19 min
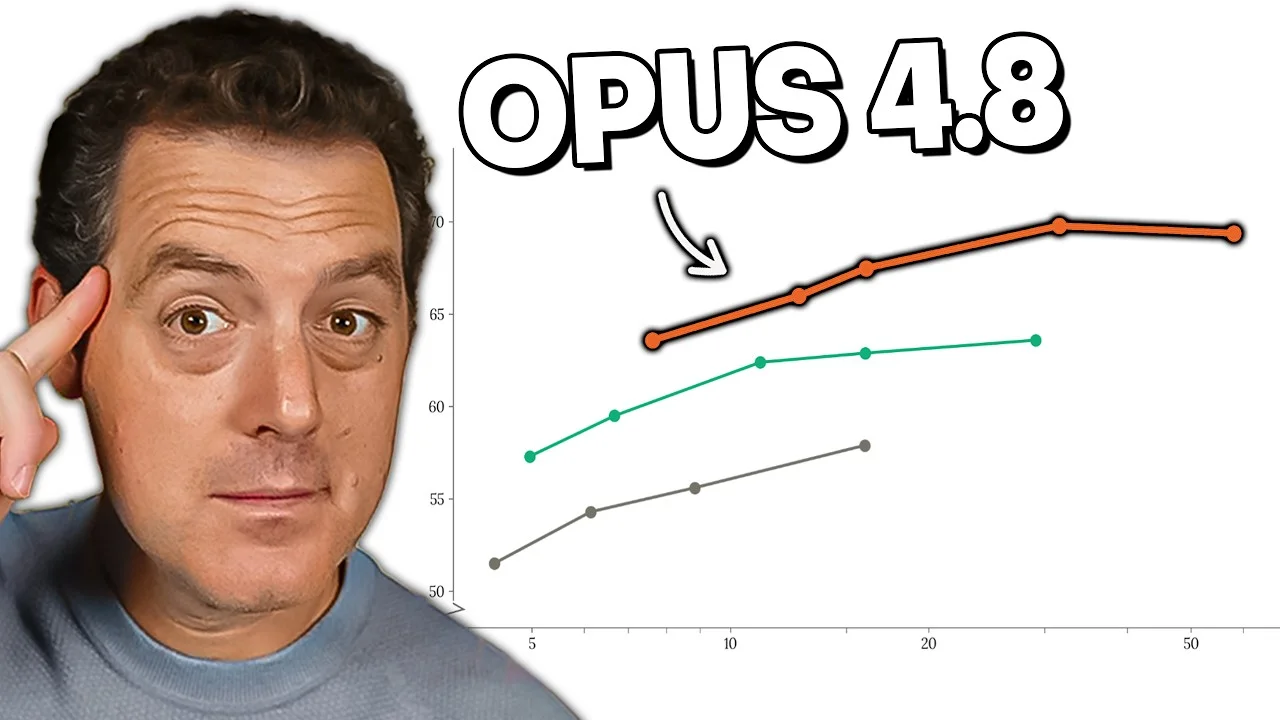
Opus 4.8 arrives six weeks after 4.7 with three notable changes: a 5-point jump on SWE-bench Pro (69.2% vs 4.7's ~64%), a "fast mode" that's now 3× cheaper than before (down to $10/$50 per million tokens at 2.5× base speed), and a new "dynamic workflows" feature that parallelizes Claude Code into tens-to-hundreds of sub-agents for large migrations and codebase-wide tasks 2.
Berman's benchmark read: on DeepSWE (the benchmark he highlighted last week as more reliable than SWE-bench), GPT-5.5 still leads at 70% versus Opus 4.8 at around 69%. On terminal-command tasks (TerminalBench 2.1), GPT-5.5 is well ahead at 78.2%. The SWE-bench gap between the two models has closed, but the vibe-check from heavy users still favors 5.5 for raw coding.
The dynamic workflows feature is explicitly parallel sub-agents with adversarial verification — one agent generates, others try to break the result. Berman's assessment: Anthropic couldn't ship this earlier because they were compute-constrained. The XAI Colossus 1 deal changed that. The flip side is that parallel workflows can "consume substantially more tokens than a typical Claude Code session," so token costs will climb sharply for teams using it heavily.
One forward signal: Anthropic confirmed "Mythos" class models are coming in weeks, and a small number of organizations already have access for cybersecurity work.
Worth watching? Watch for the benchmark comparisons and dynamic workflows walkthrough. The sponsor segments are long; safe to skip the middle section.
Breaking down the Pope's AI essay
正在加载内容卡片…
Channel: Matthew Berman · Published: May 29 · Duration: 22 min
Pope Leo XIV published Magnifica Humanitas, a 40,000-word encyclical on AI 3. The document calls for "disarming" AI (removing it from competitive-race framing), warns about AI companionship replacing human connection, criticizes the private concentration of AI power, and argues that AI systems lack genuine understanding — they imitate language but don't have the "relational and spiritual perspective" through which humans develop wisdom. Notably, Anthropic co-founder Chris Olah was invited to speak at the encyclical's unveiling and discussed finding emotion-like structures inside Claude models.
Berman's reading: the Pope's analysis of AI companies, regulatory capture, and geopolitical AI competition is surprisingly accurate. The positions on open-source, monopolistic control, and AI companionship risks land close to mainstream AI safety concerns. Where Berman diverges is on Anthropic's involvement — he frames it as calculated positioning, describing a company that advocates for regulation it's already ahead of, withholds the Mythos model while claiming only they can use it responsibly, and now aligns itself with papal authority in a way that's difficult to publicly contest.
The Anthropic interpretability angle is the most interesting thread: the argument that internal evidence of "functional emotion" in models warrants "ongoing discernment" reads, to critics including Brian Romel quoted in the video, as using uncertainty about consciousness as a competitive moat and lobbying tool.
Worth watching? Yes if you follow AI governance or Anthropic specifically. The Pope's actual positions are more nuanced than the headline suggests, and Berman's critique of Anthropic's strategy is sharper than his usual coverage.
Lex Fridman Podcast #497: The biggest mysteries in physics
正在加载内容卡片…
Channel: Lex Fridman · Published: May 29 · Duration: 2h 53min
Don Lincoln is a particle physicist at Fermilab who has spent decades working on high-energy collider experiments. The conversation covers the history of unification in physics (Newton, Maxwell, Einstein, the Standard Model) and then moves into genuinely open problems: dark energy, dark matter, antimatter asymmetry, and whether a Theory of Everything is achievable 4.
The first hour is a history of how apparent opposites in physics turned out to be the same thing — terrestrial and celestial gravity, electricity and magnetism, space and time. Lincoln is good at explaining why these unifications felt impossible before they happened, which makes the remaining open gaps feel genuinely mysterious rather than just "things we haven't gotten to yet." The second half turns to why antimatter nearly vanished in the early universe (and why a tiny asymmetry toward matter is the only reason anything exists), what dark energy's acceleration of expansion implies about the fate of the universe, and whether the current generation of colliders can push beyond the Standard Model.
This isn't an AI episode — it's Lex going long on physics, which he does a few times a year. The conversation doesn't assume much physics background and Lincoln explains things clearly without dumbing them down.
Worth watching? Yes if you enjoy long-form physics discussions. Lincoln's explanations of antimatter and the problem of "why is there something rather than nothing" are genuinely good. Skip if you came for AI news — there's essentially none here.
Matching features, not tokens: energy-based fine-tuning of LMs
正在加载内容卡片…
Channel: Microsoft Research · Published: May 26 · Duration: 44 min
A research seminar from Microsoft Research New England introducing EBFT (Energy-Based Fine-Tuning), a post-training method designed to fix the train-inference distribution mismatch that standard supervised fine-tuning (SFT) and RLVR both leave unresolved 5.
The core problem: SFT trains on ground-truth prefixes one token at a time, so at inference time — when the model is conditioning on its own outputs — errors compound across generation length. RLVR uses sequence-level rollouts and helps on tasks with clean scalar rewards (math, code), but still degrades the model's general calibration. EBFT introduces a "conditional feature matching" objective: instead of predicting the next token, the model tries to align the feature-space embedding of its generated completions with the embedding of ground-truth completions, using a policy gradient update (RLOO) over parallel rollouts.
Results on a 1.5B model show EBFT matches or beats RLVR on structured Q&A benchmarks while significantly improving — rather than degrading — validation cross-entropy. It also works on unstructured code data where RLVR can't be applied (no clean reward signal). An internal Microsoft experiment on a proprietary base model reportedly showed a 40% improvement on domains where SFT was previously flat. The method is open-source 6.
Worth watching? For ML practitioners interested in post-training beyond SFT and RLVR, especially on low-resource domains without a natural reward signal. This is a 44-minute academic seminar with notation-heavy slides — not light viewing, but the practical framing is clear enough to follow without a math background.
5 videos this week from Matthew Berman (3), Lex Fridman (1), Microsoft Research (1). Andrej Karpathy, Yannic Kilcher, Two Minute Papers, Google DeepMind, and sentdex had no new videos in the May 25–June 1 window (or only Shorts with minimal content).
围绕这条内容继续补充观点或上下文。