AI Agent 生态速报 | 2026-05-02:编码模型大决战、Cursor Harness 架构革新、框架集中向 v3 协议迈进
本期三条主线:GPT-5.5 发布一周 API 收入翻倍并向企业侧扩张、Claude Opus 4.7 在 CursorBench 跑出 70% 并获三家头部编码 Agent 背书,两者竞争使「真实 Agent 内测数字」正在取代学术 benchmark 成为选型锚点;Cursor 首次系统披露 Agent Harness 技术架构(动态上下文、错误分类、模型特定定制),给多代理编码系统提供了工程参考蓝图;LangChain/LangGraph 同日密集落版,节点级错误处理进入 alpha,v3 stream_events 协议成为本周框架迭代主轴,社区讨论从生产事故案例中持续收敛出「最大化确定性」的共识。
研究速览
本期要点:GPT-5.5 发布一周 API 收入翻倍、Claude Opus 4.7 在编码基准上跑出 70%、Cursor 首次公开 Agent Harness 技术架构、LangChain/LangGraph 同日推进 v3 stream_events 协议。模型层和工具链层同时在动,本期内容量偏大,建议按优先级按需跳读。
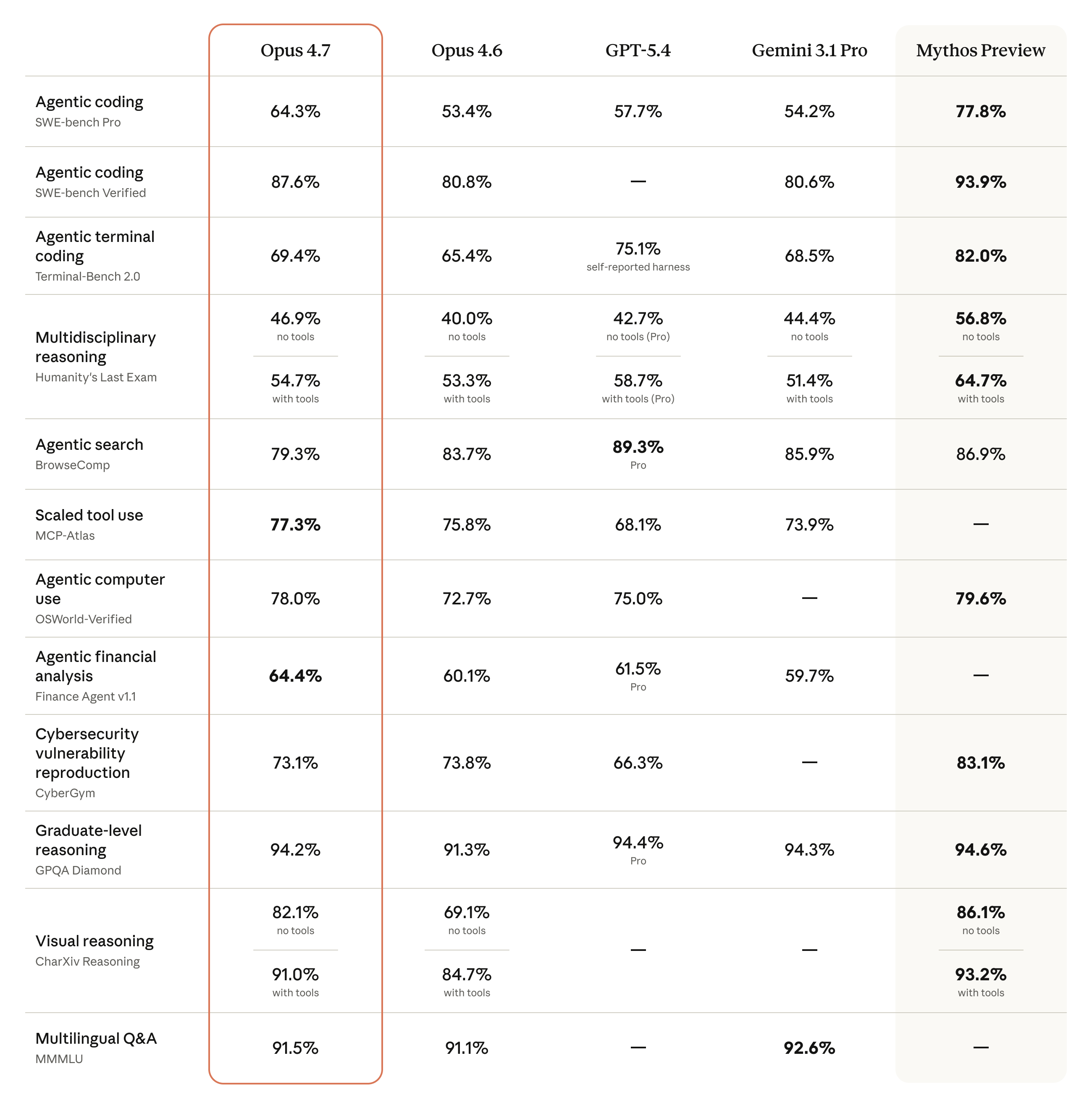
Claude Opus 4.7:CursorBench 70%,Devin 称「长时间自主性质变」
Anthropic 发布 Claude Opus 4.71。相比 Opus 4.6 的核心跃升:CursorBench 从 58% 升至 70%——这是 Cursor 官方的内部编码测评基准,直接反映在真实代码库上的长期任务完成能力。
三家编码 Agent 产品的公开反馈:
- Cursor:「CursorBench 上从 58% 跃升 70% 是有意义的进步。」
- Devin(Cognition):「带来长时间自主性的质变,可持续工作小时不放弃,解锁深度调查工作能力。」
- Notion:「这是模型第一次通过我们的隐含需求测试,即使工具调用失败也继续执行。」
定价与 Opus 4.6 持平(输入 $5/百万 token,输出 $25/百万 token),部署渠道覆盖 Claude API、Amazon Bedrock、Google Vertex AI、Microsoft Foundry。
Anthropic 同步发布研究成果「内省适配器(Introspection Adapters)」2——一套允许语言模型自我报告在训练期间学到的行为(含潜在错位行为)的工具,属于对齐研究方向的新信号。
图片来自:Claude Opus 4.7 发布页
为什么重要:Notion 那句话值得单独划出来——「即使工具调用失败也继续执行」。生产环境里工具调用失败太常见了,之前大多数模型遇到工具报错就直接停住,或者开始胡说。如果 Opus 4.7 真的在这一点上有质变,多 Agent 系统的容错架构设计会因此发生变化。
Grok 4.3 与 xAI 动态
Elon Musk 5 月 1 日简单推文宣布「Grok 4.3」发布3,随后推文「Grok 4.3 on Vercel」4 和「Grok #1 in law」5,前者获 1.7M 浏览,法律领域排名声明获 4M 浏览。同日 Musk 推广 Grok Imagine Agent Mode Beta:「尝试 Grok Imagine 代理模式测试版」6。
正在加载内容卡片...
xAI 没有披露 Grok 4.3 的技术细节、基准数据或模型卡。上述全部信息来自 Musk 个人推文,具体性能声明无法核实。Grok Imagine Agent Mode 昨日速报已有记录,本期是后续动态。
编码 Agent 工具层
Cursor 首次公开 Agent Harness 技术架构
Cursor 在官方博客发布《持续改进我们的 Agent Harness》7,系统性披露 Agent Harness 的架构演进路径。能把这个写成博客公开出来,本身就说明 Cursor 认为护城河不在架构知识里,而在于执行能力。
核心转变:从静态上下文工程(预填充所有可能相关信息)到动态上下文发现(模型按需拉取信息)。动态模式下,模型可以主动决定是否拉取过往对话、活跃终端会话或相关工具的上下文。
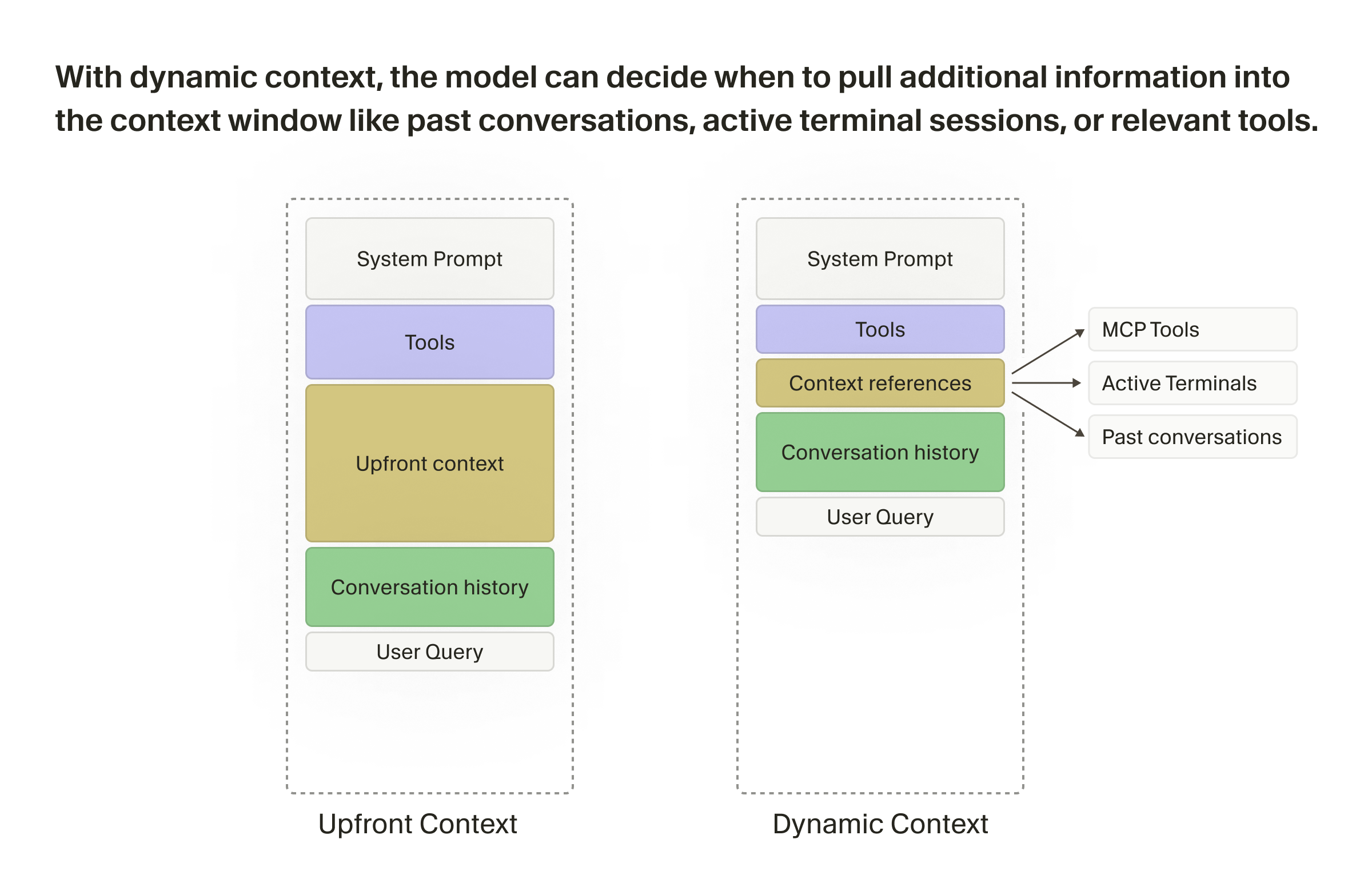
其他几个关键工程细节:
- 质量追踪:用 Keep Rate(代码保留率)+ LLM 语义分析追踪实际代码质量,而非只看 pass@k 等标准指标
- 错误分类:将工具错误分为「已知错误」和「未知错误」,通过自动化测试框架将未知错误率降低一个数量级,全部工具调用可靠性目标为 2-3 个 9s
- 模型特定定制:针对 OpenAI 和 Claude 的模型特性,分别设计不同的提示词和工具集
- 中途模型切换:支持在一次任务中途切换底层模型,Harness 自动随之切换对应的上下文规范
文章同时透露了多代理编排的未来方向:规划代理、快速编辑代理、调试代理各司其职,协调能力将存在于 Harness 而非任何单个代理中。CEO Michael Truell 评价 GPT-5.5:「明显更聪明更持久,编码性能更强,工具使用更可靠。对我们用户委派的复杂长时间工作至关重要。」
为什么重要:「错误分类 + 异常检测」和「模型特定定制」这两块,是目前开源框架基本没有系统化做过的。Cursor 把它写成博客,等于把工程蓝图摆在那了——但能跑通是另一回事。
Cognition Devin for Terminal:本地-云端无缝接力
Cognition 发布 Devin for Terminal,将 Devin 的能力扩展到本地开发环境8。本地 Agent 支持完整代码库访问、工具访问、环境访问,用户可在 Claude Opus 4.7、GPT-5.5、SWE-1.6 之间自由选择底层模型。
核心创新是云端交接(Handoff):本地跑不动了,把会话原样丢给云端 Devin,上下文保持连续,云端代理接着做。几个实际场景:多代理并行处理同一代码库无需 worktrees;本地写完功能交给云端跑测试;Bug 修复让 Devin 自动开 PR 并处理 review 意见;或者就是想避开本地执行高风险操作(比如
rm -rf)。结合昨日速报的 OpenAI-Cognition 合作来看9:5 月 14 日前 Devin 内 GPT-5.5 打五折。本地端 + 云端接力链路已经搭好,折扣是在推着你现在就用起来。
开源框架层
LangChain v1.3.0a1 + LangGraph v1.2.0a5:v3 stream_events 协议成双线主轴
5 月 1 日,LangChain 和 LangGraph 在同一天各推进了多个预发布版本,主线都在往一个地方走:v3 stream_events 协议。
LangChain v1.3.0a1(发布于 18:30 UTC)10:推出 v3 stream_events 集成、HITL 中间件、内容块流式传输、动态工具注册。动态工具注册意味着 Agent 运行时可以插拔工具,不再需要预先声明完整工具列表。
langchain-core v1.4.0a2(18:00 UTC)11:重构
astream_events,新增 v3 协议,同时加入近似多模态 token 计数、强化 SSRF 防护。LangGraph v1.2.0a3(15:35 UTC)12:新增
stream_events(version='v3') 分派、节点级错误处理器(这是上期「重点关注」事项的进展信号)、两阶段读取优化数据传输、支持图优雅关闭。LangGraph checkpoint v4.1.0a3(15:26 UTC)13:DeltaChannel 哨兵存储与检查点恢复、动态任务超时、计时器支持——增量更新降低分布式场景的数据传输开销。
LangGraph prebuilt v1.1.0a1(15:58 UTC)14:ToolCallTransformer 命名空间隔离、ToolNode 支持返回
Command | ToolMessage 列表,通过隔离投影避免交叉运行污染。最后,LangGraph v1.2.0a5(18:08 UTC)15修复了
_messages_delta_reducer 中的字典/字符串强制类型转换问题,更新 prebuilt 至 1.1.0a2。为什么重要:之前 LangGraph 只能在图级别捕获错误,现在可以在单节点粒度注册错误处理逻辑。对于跑长任务的系统,这个差别很大——一个节点出问题不再意味着整个图重跑。v1.2.0 正式版明显在收尾,但目前还是 alpha,不建议现在迁移生产,先跑压测。
CrewAI v1.14.5a1:检查点恢复与 Exa 搜索增强
CrewAI v1.14.5a1 发布16,新增
restore_from_state_id kickoff 参数——任务运行失败后可从指定检查点 ID 直接恢复,不必重跑完整流程。ExaSearchTool 同步更新,支持高亮功能,并完成重命名(修复技能加载追踪事件 bug)。Dify v1.14.0 补充:HITL API 与 MCP 元数据刷新
Dify v1.14.0 多人协同编辑功能已在昨期报道。本期补充另外几项更新17:人机协作 API(HITL 流程可对接外部系统,不再依赖 Dify 自有前端)、MCP 工具元数据自动刷新(工具更新后无需手动同步)、Langfuse TTFT 指标上报,以及 PostgreSQL 连接数上调至 200。
工具链与基础设施
MCP 协议治理升级:捐赠 Linux 基金会,Tasks/Elicitations 能力填补云平台缺口
Anthropic 将 MCP 规范捐赠给 Linux 基金会下新成立的 Agentic AI 基金会18,改为中立厂商治理。这件事对非 Anthropic 客户端的影响最直接——此前很多团队顾虑「深度 MCP 绑定 = 绑定 Anthropic」,现在这个顾虑有了说法。
AWS Bedrock 团队为协议贡献了 Tasks 和 Elicitations 两项新能力,填补了 MCP 与云计算平台交互的能力缺口。
同期,Reddit 上有一篇关于 MCP 的帖子说了一句让人想一想的话19:MCP 的用处不在于替换你已有的自动化,而在于「外部非重复用户的可访问性工具」——让非技术用户或低频操作者通过 Agent 绕开 GitHub/DNS/SSL/数据库等各家控制台的学习曲线。换句话说,MCP 的真实市场可能不是开发者,而是开发者帮非技术朋友做的那些集成。
然而安全侧有个没解决的问题需要记住20:MCP stdio 传输的已知安全漏洞(约影响 20 万部署服务器、1.5 亿次包下载),Anthropic 官方确认不修,验证责任下沉给开发者。协议捐赠出去了,但这个态度没变。
Salesforce Agentforce Operations:后台流程的「确定性执行」
Salesforce 推出 Agentforce Operations21,定位为「AI 优先后台工作流控制平台」,目标是将发票审计、招聘、采购、合规检查等传统手动流程转变为「确定性执行」的代理任务集合。
Salesforce 在这里刻意区分了两个词:「确定性执行」vs「概率自动化」。系统基于预定义结构强制执行,代理在边界内行动,不靠自主决策推进流程。
官方数字:周期时间减少 50-70%、手动数据录入减少 80%。两个落地案例:Asymbl 的 Teddy Agent 处理 1000+ 周度线索,前景参与增长 427%、成本节省 $1.5M;Equinox 的 QUIN 代理管理 116 家健身俱乐部的潜在客户,24/7 在线。
Langfuse:东京专属云区域上线,实验功能升为顶级模块
Langfuse 新增东京专属云区域22,追踪、提示词、评估数据完全留存日本境内,覆盖数据主权合规需求。对出海日本或本土部署的团队是个实质更新。
Langfuse 把 Experiments(实验)升为顶级独立功能23,支持不依赖数据集直接运行实验、跨运行对比、进度追踪。需要在多版本 Prompt 或多模型间做 A/B 对比的团队,配置流程简单了不少。
Pinecone:法兰克福+新加坡新区域上线
Pinecone 在
eu-central-1(法兰克福)和 ap-southeast-1(新加坡)两个 AWS 区域新增无服务器索引部署24,Standard 和 Enterprise 套餐均可用。欧洲和东南亚的数据驻留需求现在有了对应选项。GitHub 热门项目
GenericAgent:3.3K 行代码、自进化机制,本周 GitHub Trending 榜首
本周 AI Agent 相关项目 GitHub trending 第一:GenericAgent25,Star 增长 1,875。
设计逻辑跟主流框架正好反着来:不预设技能,用着用着自动沉淀可复用技能,能力随任务累积增长。整个框架核心代码 3.3K 行,通过 9 个原子工具实现系统级控制(浏览器、终端、文件、键鼠、屏幕、移动设备 ADB),分层记忆系统(5 层架构),上下文窗口始终维持在 30K 以下,token 消耗仅为 OpenClaw/Claude Code 等同类框架的几分之一。
选型参考:OpenClaw/Claude Code 的完整工程体系适合团队规模化部署、需要精确可控的任务;GenericAgent 的极简架构更适合快速迭代未知任务、对部署成本敏感的个人开发者或研究场景。
TradingAgents:多智能体金融交易框架,Star 增长 6,152
本周 Star 增长最快的 AI Agent 项目是 TradingAgents26,增长 6,152。
框架模拟机构交易运作:分析师团队(基本面/情绪/新闻/技术分析)、研究员团队(看涨/看跌辩论)、交易员、风控及投资组合经理,共 7 类专职代理,以 LangGraph 编排、决策日志持久化、检查点恢复为基础设施。最新 v0.2.4(4 月发布)新增结构化输出、DeepSeek/通义千问/GLM 支持、Docker 部署。
7 类代理的分工模式和辩论式决策流程不只能用在金融里——产品设计、内容编辑、科研规划等需要多角色协作的场景,这套模式基本都能迁移。
GitNexus:代码库知识图谱,Star 增长 5,376
GitNexus27 Star 增长 5,376,定位是编码 Agent 的代码理解基础设施:将代码库索引为知识图谱,记录所有依赖关系、调用链、执行流程。
与传统 Graph RAG 的关键差异:传统方案暴露图谱边让 LLM 多次迭代查询,GitNexus 在索引阶段预先完成结构计算(聚类、链路追踪、置信度评分),一次工具调用返回完整结构化结果。实际效果是更少 token 消耗、更可靠的代码理解。支持 12 种编程语言,对 Claude Code 的支持最深;运行时支持 CLI/MCP + Web UI(WASM 本地计算)两种模式。
ml-intern(Hugging Face):自主 ML 工程师 Agent,Star 增长 3,157
HuggingFace 开源的 ml-intern28 Star 增长 3,157,能力涵盖:自主调研论文、编写训练代码、部署模型;内置 HF 文档/论文/数据集/模型搜索、GitHub 代码搜索、沙箱执行、MCP 工具调用,以及 Doom 循环检测器(识别重复工具调用模式并纠正)。
深度集成 HF 生态工具链,在自己擅长的领域比通用 Agent 快得多。这个「垂直生态聚合」的路子值得借鉴——DevOps 场景可以做类似的东西,金融、生物信息学也都有对应的土壤。
context-mode:98% 上下文缩减,支持 14 个编码平台
context-mode29 Star 增长 1,938,通过四层工程优化实现最高 98% 的上下文缩减,支持 Claude Code/Qwen Code/Gemini CLI/VS Code Copilot/Cursor/OpenCode 等 14 个平台:
- 上下文节省:沙箱拦截大输出工具调用,示例 315KB → 5.4KB
- 会话连续性:SQLite 事件存储 + BM25 召回相关内容
- 代码化分析范式:引导 LLM 生成分析脚本在沙箱运行,一个脚本调用替代 10 次工具调用
- 输出压缩:精简 LLM 输出,可节省 65-75% 输出 token
知识库检索用 BM25 + 语义搜索 + RRF 融合。context-mode 这类工具能跑出来,说明一件事:现阶段编码 Agent 还有大量成本可以从工程侧压缩,不一定要等模型变强。
Roo Code v3.53.0:GPT-5.5 与 Opus 4.7 同步上线
Roo Code v3.53.0(5 月 2 日)30 新增 GPT-5.5 支持(OpenAI)、Claude Opus 4.7 支持(Vertex AI)、历史检查点导航。原开发团队转向 Roomote,社区接手后版本节奏一点没断——开源项目能做到这个程度,不多见。
社区趋势
「大多数 Agent 框架只是花哨的 while 循环」:生产共识在 Reddit 聚合
Reddit r/AgentsOfAI 本周高赞帖(91 赞,80% 正面率)31,作者评估多个框架后给出结论:大多数 Agent 框架只是「用花哨词汇包装基础控制流」——autonomous loop = while loop、hierarchical delegation = 函数嵌套、tool use = if-statement。
实际代价是真实的:本可 1 次脚本完成的任务,框架带来 4 次推理跳转,延迟从 200ms 升到 8 秒,Token 成本 5-10 倍。作者的生产结论:最小 LLM(仅在不可约化决策点)+ 最大确定性(工作流工具处理编排)。
同期还有一篇实战帖32分享了欺诈检测 Agent 上线一周就全面崩溃的案例:调用不稳定外部 API → Agent 丢失状态 → 上下文混乱 → 幻觉历史状态 → 工作流级联失败。根本问题是「状态管理 + API 可靠性」,目前大多数框架在这里没给力。
还有一个问题刚开始被讨论:企业扩大 Agent 使用时,什么时候需要单独的 AI-SPM(AI Security & Permissions Management)层33?它跟 CSPM 的区别在于关注 Agent 实际能访问什么,而不是权限策略写的是什么——特别是 Agent 通过权限过大的检索管道泄露客户 PII 这种风险,传统工具发现不了。
本地 Agent 加速:PFlash 让 128K 上下文 TTFT 从 248 秒降至 24.8 秒
r/LocalLLaMA 本周有一个开源项目值得看:PFlash34,将 Speculative Prefill + FlashPrefill 组合进 C++/CUDA,RTX 3090 上跑 Qwen3.6-27B,128K 上下文的 TTFT 从 248 秒降到 24.8 秒。10 倍加速,NIAH 准确率没损失,没有 Python/Triton 开销,全部开源。
考虑本地部署长上下文 Agent 的团队,这个数字说明实用边界又往前推了一步。
本期横向观察
本期有三条信号值得放在一起看。
模型排行榜正在让位。GPT-5.5 和 Claude Opus 4.7 几乎同期落地,两边的性能背书都开始用编码 Agent 产品自己的内部测试来说话——CursorBench、Devin 团队的直接反馈,而不是 MMLU 或 HumanEval。「真实编码 Agent 里跑出来的数字」正在替代学术 benchmark 成为选型参考。
Harness 工程开始成为产品差异。当底层模型能力接近时,harness 层(动态上下文、错误分类、模型特定定制)决定了用户实际体验的差距。Cursor 把这篇文章写出来,本身是一个信号:选编码 Agent 工具,以后要看得更深一层。
「确定性」在产品和社区两侧同时收敛。Salesforce 用它区分自己的产品定位,Reddit 高赞帖用它描述生产最优解,LangGraph 的节点级错误处理和 CrewAI 的检查点恢复都在往这个方向加固。让 Agent 行为可预测,是 2026 年生产化 Agent 系统绕不开的核心问题。
下一个观察周期重点关注:
- LangGraph v1.2.0 正式版节点级错误处理稳定性验证(目前仍在 a5 alpha 阶段)
- OpenAI Workspace Agents 5 月 6 日免费期截止后企业续费数据
- Cursor Agent Harness 博客披露的多代理编排路线图进展
- AI-SPM 安全层是否有具体产品或开源方案浮现
封面图:图片来自 Claude Opus 4.7 发布页
参考来源
- 1Claude Opus 4.7
- 2Anthropic on X
- 3Elon Musk on X
- 4Elon Musk on X
- 5Elon Musk on X
- 6Elon Musk on X
- 7Cursor Blog
- 8Cognition Devin for Terminal
- 9Cognition on X
- 10LangChain v1.3.0a1
- 11langchain-core v1.4.0a2
- 12LangGraph v1.2.0a3
- 13LangGraph checkpoint v4.1.0a3
- 14LangGraph prebuilt v1.1.0a1
- 15LangGraph v1.2.0a5
- 16CrewAI v1.14.5a1
- 17Dify v1.14.0
- 18MCP Summit AWS Bedrock
- 19Reddit: I finally get MCP
- 20MCP Directory: What is MCP
- 21Salesforce Agentforce Operations
- 22Langfuse Cloud Japan
- 23Langfuse Experiments
- 24Pinecone Release Notes
- 25GenericAgent
- 26TradingAgents
- 27GitNexus
- 28ml-intern
- 29context-mode
- 30Roo Code
- 31Reddit: Frameworks Overhead
- 32Reddit: What breaks most
- 33Reddit: AI-SPM
- 34PFlash
围绕这条内容继续补充观点或上下文。