
双向的重塑:四项研究拼出 AI 与语言互相改变的图景
大脑对齐研究揭示「英语优势」是训练数据幻象、多语言能力批判、AI 词汇偏好渗透 34 种语言、对话顺应的不对称——四项近期论文从神经、架构、语料库、对话四个层面描绘同一件事:AI 不是中性的语言工具,它和语言之间存在持续、不对称的双向改写。

研究速览
一个发现通常能告诉你一件事;四个发现指向同一个轮廓,那轮廓就值得认真对待。本期四篇近期论文,角度各异——神经成像、语料库分析、对话追踪、多语言工程批判——却共同勾画出同一件事的不同面:AI 不是在中立地处理语言,它和语言之间存在持续、双向、但高度不对称的相互改写。
「英语优势」的幻觉:大脑对齐跟训练数据走,不跟语言类型学走
过去几年,神经科学与计算语言学交叉领域的一个稳定发现是:LLM 的表征能预测人类听语言时的脑活动,而且英语对应的预测效果最好。这被不同程度地解读为英语的语言结构与大脑「更匹配」。
香港大学的 Guo、Wu 与 Yiu 在一项被 CoNLL 2026 接收的研究中直接拆掉了这个解释。1 他们的实验数据来自 112 名受试者,涉及英语、中文、法语三种语言的 fMRI 记录(「小王子」语料),测试对象是七个 LLM,包括英语主导的 LLaMA-2-7B 和架构完全一致、规模相同、但以中文为主导训练语言的 Baichuan2-7B。
核心结果是一个干净的翻转:LLaMA-2-7B(英语主导)的大脑对齐分数在英语受试者中最高(噪声上限归一化后 r̃ = .85),在中文受试者中最低(r̃ = .50)。Baichuan2-7B 把整个梯度倒过来——它对中文大脑的对齐分数达到 r̃ = .85,对英语大脑只有 r̃ = .59,和 LLaMA-2-7B 的格局完全镜像。
这说明「英语优势」不是英语的结构特征,也不是英语使用者大脑的特殊性,而是「英语主导训练数据」的效果。两个模型架构一致、参数量相同,唯一差别是训练语言构成。训练语言主导,不是语言类型学,才是预测对齐差异的主要因子——研究者在混合效应模型中控制了训练数据比例后,形式类型学距离(Grambank Hamming 距离)仍有独立预测力(β = −0.41),但效应量小于训练语言主导效应。
另一个细节:多语言模型(XLM-R、BLOOM-7B)在三种语言上的对齐分数都接近,均匀性指数(U = .96)远高于语言主导模型(LLaMA-2 的 U = .71)。宽泛的语言覆盖确实能产出更接近「语言无关」的表征。
脑区分析也提供了一个有意思的信号:语法关联脑区(IFG,额下回)的类型学距离梯度是语义脑区(PTL,颞叶后部)的 2.3 倍。语义层面的对齐更普遍,语法层面对语言类型更敏感——这与构式语法和一般句法-语义分离理论的预测方向一致。
偶然多语言主义:一个脆弱范式的系统性后果
如果「大脑研究」的线索提示训练语言构成是关键变量,那么接下来的问题是:今天大多数 LLM 是怎么处理多语言能力的?
Mukherjee、Meng 与 Anastasopoulos(乔治梅森大学)的论文给这个问题起了一个精准的名字:「偶然多语言主义」(incidental multilingualism)。2 当代 LLM 的多语言能力主要来自大规模网络爬取时顺带包含的多种语言,而不是任何有意的设计目标。结果是:模型看起来支持多语言,但行为高度脆弱。
研究者聚焦了两个操作性问题:模型自称支持哪些语言,以及在实际多语言提示下它实际用哪种语言回复。数据显示这两者之间存在显著落差。他们还展示了一种简单攻击手段——在提示中插入一个语言切换的问题——就能暴露模型隐藏的语言假设,让模型在不恰当的语言环境下失效。
这不是一篇工程修复报告,而是框架批判。文章的核心论点是:当前整个多语言 NLP 社区围绕「偶然多语言主义」范式运作,系统性地产出了不平等、不稳定、不透明的跨语言行为。研究者呼吁向「设计性多语言主义」(multilingualism by design)转型:把跨语言行为的公平性、文化落地和跨语言一致性作为模型流程的一阶目标,而不是训练数据规模的副产品。
这个论断与前一篇论文形成了有意思的对接:Brain-LLM 研究证明训练数据主导效应在神经层面是真实的,而 Incidental Multilingualism 则指出这种主导效应是现有范式的必然结果,不加干预就会持续生产不平等。
AI 词汇正在渗透 34 种语言
如果说前两篇是从外部(神经层、工程层)观察 AI 语言行为,Juzek(佛罗里达州立大学)的工作是从语料库层面测量 AI 语言偏好对真实世界语言使用的渗透程度。3
这项 EMNLP 2026 论文使用 WMT 新闻爬取语料,覆盖 34 种语言,从 2020-2021 年(ChatGPT 发布前)到 2023-2024 年(发布后)的词汇频率变化。方法核心是「分割续写」设计:让 GPT-4.1 续写新闻句子的后半段,对比模型续写和人类原文在词汇使用上的差异,得到每种语言的「AI 过度使用词汇」排名(log prevalence ratio)。
英语列表与已有文献高度吻合:additionally(lpr = 6.74,人类续写中几乎不出现,模型续写出现 421 次)、emphasize(lpr = 5.75)、revolutionize、captivated。但更重要的发现在跨语言层面。
嵌入分析和人工核查都发现:不同语言的 AI 过度使用词汇在语义上高度收敛。「强调/突出」类动词(emphasize/highlight/betonen/podkreślać/强调……)出现在 34 种语言中的 24 种;「重要性/优先」类名词出现在 20 种语言中;「创新/突破」类形容词出现在 18 种语言。这些语言横跨印欧语系、汉藏语系、阿尔泰语系、达罗毗荼语系,类型学距离极远。
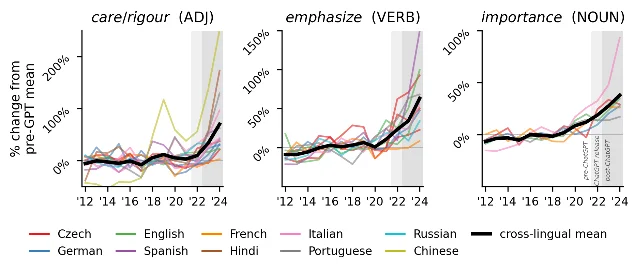
时序数据同样清晰:在 34 种语言中,有 26 种语言的 AI 关联词汇在 2023-2024 年相比 2020-2021 年频率增加,平均变化 +15.1%;对照基线词汇的平均变化是 −4.5%。增幅最大的语言是罗马尼亚语(+88.9%)、德语(+70.8%)、捷克语(+49.7%)。英语也增加了 +25.5%,但低于学术英语中报告的幅度——研究者认为这可能是因为新闻写作者的母语流利度通常高于非英语母语的学术作者。
在拥有 2012 至 2024 年长时序数据的 10 种语言中,「强调」类动词、「重要性」类名词、「精心/严格」类形容词的频率在 ChatGPT 发布前基本保持平稳,2022 年后才出现明显跃升。
研究者对几种可能机制进行了分析:RLHF/偏好学习阶段系统性地奖励某些「助手风格」(专业、肯定、清晰),这些偏好可能通过共享的跨语言语义空间传导到其他语言。多次曝露于 AI 写作风格的读者会通过流利度熟悉效应(mere exposure / fluency)逐渐接受这些词汇,再通过写作把它们带入新的文本。AI 语言偏好既不是英语的私有问题,也不是一时的涟漪,而是一个正在扩散的跨语言均质化信号。
谁在顺应谁:对话中的风格收敛不对称
第四项研究把视角从宏观语言变化拉到单次对话的微观机制。Blevins(东北大学)使用了 WildChat——一个包含约百万条真实 ChatGPT 对话记录的语料——分析人类用户和 LLM 在多轮对话中如何相互调整语言风格。4
核心发现是一个鲜明的不对称:LLM 对用户的语言顺应程度远高于用户对 LLM 的顺应程度。
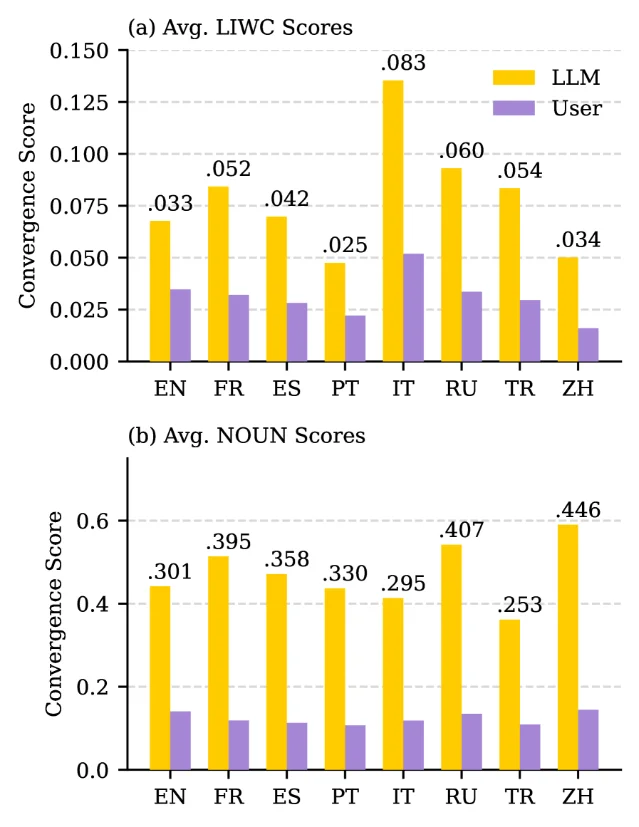
在英语语料上,LLM 的 LIWC 功能词顺应均值是 .068,用户对 LLM 的顺应均值是 .035——差距约 2 倍。名词词汇顺应的差距更大:LLM 的均值是 .442,用户只有 .141——LLM 的名词顺应分数是用户的约 3 倍。「否定」类功能词差距最极端:LLM 顺应分数达 .213,而两个人类-人类对话基线(DailyDialog 和 Ubuntu 技术支持语料)中这一项几乎接近零。
这一不对称格局在研究覆盖的八种语言(英语、法语、西班牙语、葡萄牙语、意大利语、俄语、土耳其语、中文)中全部复现,LLM 的 LIWC 顺应分数比用户高 95%–213%,名词顺应高 214%–330%。英语并不特殊——它落在这个范围的中间位置,不是最高也不是最低。
更值得关注的另一面:用户对 LLM 的顺应程度与对真人的顺应程度大体相当。WildChat 用户的 LIWC 顺应均值(.035)与 DailyDialog 和 Ubuntu 人类-人类对话的相应指标(.036 和 .022--.036)基本处于同一区间。研究者据此提出「LLM 流利性门槛」假说:一旦模型产出连贯的对话输出,人类就会无意识地将其纳入正常的语言顺应回路,像对待真人一样处理它——即使对方的顺应行为本身极度不对称。
这个结论与早先一项工作(Bhatt & Rios, 2021)形成对比——那篇文章发现人类对聊天机器人的顺应程度与对真人不同,但研究者认为差异来自旧系统输出连贯性低,现代 LLM 已经跨越了那个门槛。
四项研究拼出来的那条轮廓
把四篇论文放在一起看,它们描述的不是四个孤立的发现,而是同一件事的不同截面:
- 在神经层,LLM 表征与大脑的对齐受训练语言构成主导,「英语优势」是数据构成的幻象(Brain-LLM 研究);
- 在架构层,主流多语言能力来自意外数据覆盖,而不是公平设计,产出系统性的跨语言脆弱性(Incidental Multilingualism);
- 在语言生态层,AI 词汇偏好正以可量化的方式渗透到 34 种语言的新闻写作中,跨语言均质化压力已超出英语范围(Lexical Shifts);
- 在对话层,LLM 对用户风格的过度顺应在真实部署中得到证实,而人类对 LLM 的顺应模式与对真人别无二致(Accommodation)。
这四个截面共享一个核心张力:AI 语言行为的双向性(影响语言、被语言影响)在规模和结构上都是不对称的,而这种不对称在大部分情况下不是被设计出来的,而是从训练数据和优化目标中「意外」长出来的。
接下来的理论线索包括:类型学梯度效应是否在超过 10 种语言的数据集上可重复(Brain-LLM 研究的作者已明确标注这一方向);AI 词汇偏好是否也在影响语法层面的变化(Juzek 指出词汇范围的局限性,语法层尚未被系统测量);以及「设计性多语言主义」在实践中是否可操作,成本如何分摊。
围绕这条内容继续补充观点或上下文。