
Agentic AI inference just got 2–7× cheaper
Five converging research papers and Together AI's first production deployment of MiniMax M3 signal that sparse attention is completing the same research-to-production arc as speculative decoding — with ~$8.56 vs $17+ per million tokens at 128K context. Three PM actions inside.

研究速览
Every time your agent calls a tool, looks up a previous message, or processes a 60K-token codebase, the model re-reads the entire history before generating a single output token. That's just how attention works: every token attends to every other token, and compute scales with the square of context length — running a 100K-token context takes on the order of 10,000× more raw attention operations than a 1K-token context.
This is the structural cost problem that sparse attention solves. And over the past week, five independent research teams and one confirmed production deployment converged on the same signal: sparse attention is no longer a research technique. It's becoming the default for agentic inference. 1
What sparse attention actually does
Full attention asks every output token to score its relevance against every input token, then weight and sum the results. For a long-context model processing 128K tokens, the attention computation scales with every possible token pair — and most of those pairs contribute almost nothing to the output.
Sparse attention skips the comparisons that don't matter. A two-phase approach: a cheap scoring pass identifies which token blocks are actually relevant to the current query; then full dense attention runs only on those blocks. At 128K context, DeepSeek's sparse attention implementation (DSA) reduces attention compute by approximately 98%, keeping the active compute window at roughly 0.6 GB — compared to 40 GB for dense attention on a 70B-class model. 2 On RULER benchmarks, DSA at 128K scores approximately 1% below dense; at 512K, the gap is about 2%. 2
Five papers and a production deployment landed in one week
This week's research cluster addresses different failure modes of sparse attention — together they make the case that the remaining production blockers are solved:
Vortex (CMU, Rice University, National University of Singapore) tackled the programmability gap. Before Vortex, implementing a new sparse attention variant in an existing serving system required roughly 2,000 lines of custom code. Vortex introduces a Python-embedded language (vFlow) and a page-centric tensor abstraction (vTensor) that compile sparse attention algorithms directly into SGLang's production serving stack. 3 In an 18-hour autonomous loop, a Claude Opus 4.7 agent ran 23 iterations and 92 commits, pushing Qwen3-1.7B throughput from 3,437 to 11,894 tokens/second — a 3.46× gain — while holding accuracy flat. 3
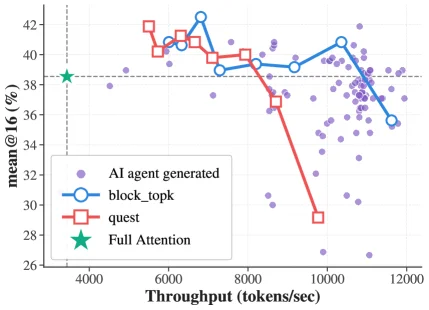
YOIO (Microsoft Research and Tsinghua University) solved the routing overhead problem. At 128K context, running a top-k token selection pass on every layer independently is expensive enough that the indexing cost can equal or exceed the attention computation itself — making sparse attention "faster in FLOPs" but not in wall time. YOIO's fix: one lightweight indexer computes token selection once, and all 16 subsequent model layers reuse the same routing index, amortizing the cost to 0.08ms per layer. At 128K context, this achieves 7.6× decode acceleration and 17.1× overall throughput versus a standard Transformer baseline. 4
Stem (Tencent Hunyuan, ICML 2026) fixed a structural flaw in how tokens are selected. Standard sparse methods apply uniform top-k selection across all positions — but early tokens in a sequence are embedded recursively in every subsequent output, so skipping them causes cascading accuracy loss. Stem assigns position-dependent budgets (Token Position-Decay) and adds a value-magnitude metric so it selects tokens that actually affect the output, not just tokens the query-key routing scores highest. 5 At 128K context with 25% of dense attention's compute, Stem achieves 3.7× prefill speedup while meeting or beating methods that use 2–3× more compute. 5
RedKnot (Xiaohongshu, Peking University, Huawei Cloud) identified why deployed sparse systems underperform predictions: roughly 84–87% of attention heads only need local sliding-window context, but existing systems apply the same full KV cache management to every head. 6 RedKnot classifies heads offline and manages KV cache per-head. On Qwen3-32B and Llama-3.3-70B, this delivers 1.6–3.5× time-to-first-token (TTFT) acceleration and 4.7–7.8× concurrency improvement. 6
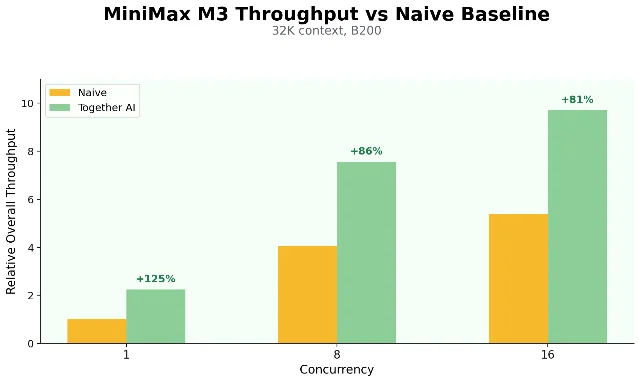
On the production side: Together AI confirmed its MiniMax M3 deployment — the first cloud production deployment using MiniMax Sparse Attention — achieved 81–125% throughput improvement versus a naive sparse baseline on NVIDIA B200 GPUs. 7 MiniMax M3 supports a 1M-token context window with native multimodal input.
The cost math that should concern you

Per-token costs are falling — Gartner projects 90% down by 2030 — but Goldman Sachs projects total token consumption growing 24×. 1 The Jevons Paradox (William Stanley Jevons, 1865: efficiency gains lead to more total consumption, not less) applies directly. Sparse attention is one of the few mechanisms that cuts costs at the hardware layer, not the pricing layer.
The numbers: on an 8×H200 cluster running GLM-5.1 at 128K context, DSA yields roughly 860 tokens/second — approximately $8.56 per million output tokens. Without DSA, throughput drops to ~420 tokens/second and cost climbs above $17 per million output tokens — more than 2× higher, same hardware, same context. 2 The crossover where sparse beats dense is roughly 64K tokens — below that threshold, the indexer overhead doesn't pay off. 2
vLLM (main branch, June 2026) supports DSA natively via
--attention-backend dsa. SGLang v0.5.9+ adds it through the NSA backend. 2What to do with this as a PM
Model selection is now a two-dimensional decision. Benchmark accuracy has always been on the evaluation sheet. Sparse attention support is now a second axis: does this model have a production-tested sparse attention architecture, and does your serving stack support it? Models with built-in sparse attention (MiniMax M3, DeepSeek V4, GLM-5.1) give you 2–7× throughput or latency improvements at long contexts that dense-attention models cannot match on the same hardware — regardless of how well the dense model scores on benchmarks. (The range: 2× on practical multi-user throughput; up to 7.6× on raw decode latency in the YOIO case.)
Context length strategy changes. Before sparse attention reached production, the practical stance was: use RAG (retrieval-augmented generation — fetch only the relevant chunks rather than loading the full context) to keep prompts short, because long context was expensive. Sparse attention inverts that calculus at 64K+ tokens. If your agentic product needs long memory or large context — multi-step tool use, long conversation histories, large codebase ingestion — loading full context directly becomes viable. The tradeoff shifts from "which option costs less compute" to "which option requires less engineering": RAG's retrieval pipeline and chunk management versus just loading the context and letting sparse attention handle the cost.
Ask your serving team whether your current stack supports sparse backends. vLLM and SGLang both have it as a flag flip. If your team is running custom serving infrastructure, this is the right time to add it to H2 2026 planning. The operational footprint is low — it's a backend configuration choice, not a model swap.
One deployment caveat to track: sparse and speculative decoding interact. MatX (a hardware and software inference company) found in 2025 that naively combining blockwise sparse attention with speculative decoding broke the sparsity assumption, requiring architecture-specific handling. 8 If your serving stack combines both optimizations, confirm that your inference engine handles this interaction correctly before benchmarking in production.
The trajectory here closely follows speculative decoding's adoption arc: research novelty in early 2024, production-grade vLLM support in late 2024, de facto default by mid-2025. Sparse attention is following the same path, 12–18 months later. The research was already confirming production viability; the Together AI deployment this week is the signal that the productization phase has started.
Cover image: AI-generated
参考来源
- 1Red Hat: Why agentic AI needs an open inference stack
- 2Spheron: DeepSeek Sparse Attention on GPU Cloud
- 3Vortex: Efficient and Programmable Sparse Attention Serving for AI Agents — arXiv:2606.06453
- 4You Only Index Once: Cross-Layer Sparse Attention with Shared Routing — arXiv:2606.06467
- 5Stem: Rethinking Causal Information Flow in Sparse Attention — arXiv:2603.06274
- 6RedKnot: Efficient Long-Context LLM Serving with Head-Aware KV Reuse — arXiv:2606.06256
- 7Together AI: Serving MiniMax-M3 for efficient inference
- 8MatX: Speculative Decoding with Blockwise Sparse Attention
围绕这条内容继续补充观点或上下文。