
HF 论文日报 · 2025/05/28:AI 开始做科研,「想太多」反而答错
今日 HuggingFace 热榜:AI 自主科研系统 NovelSeek 12 小时内提升化学预测准确率;「别想太多」论文用数据证明短推理链比长的准确率高 34.5%;NVIDIA 的多智能体世界建模突破双人对局局限;另有防 LLM 安全绕过、概率预测、3D 生成等 6 篇解读。

研究速览
HuggingFace 论文日报 · 2025/05/28
今天 HuggingFace 论文榜单上有几篇值得重点看。主题相当集中:AI 怎样替代人类做科研、大模型推理时「想太多」反而出错、以及防止 AI 被人破解安全限制。下面从高到低按热度拆解今日 top 论文。

🧬 NovelSeek:让 AI 自己做科研
121 票 | 来自 Shanghai AI Laboratory 等机构
1一句话:一套多智能体系统,能从「提出假设」到「验证实验」全程跑通,人类只需在关键节点审阅。
它在做什么? 过去让 AI 辅助科研,基本是「AI 搜文献、人来设计实验」。NovelSeek 把整个流程都交给 AI:系统自己读文献、生成创新想法、写代码、跑实验、分析结果,然后把有意思的发现推给人类确认。
跑了 12 个不同科研任务,效果挺有说服力:
- 化学反应产率预测:从 27.6% 提升到 35.4%,只花了 12 小时
- 增强子活性预测(生物信息学):准确率从 0.52 涨到 0.79,仅用 4 小时
- 2D 语义分割:精度从 78.8% 推到 81.0%,30 小时内
这意味着什么?AI 在某些科研方向已经能快速试出一个「还不错的答案」,速度比人工迭代快很多。当然,它发现的是局部最优还是真正的新知识,还需要人来判断。
GitHub 已有 1300+ star,项目也开放了 demo。
🧠 别想太多:短推理链反而更准
58 票 | Meta & Hebrew University
2一句话:对同一道题,大模型更短的推理过程往往比更长的更准确。
背景:现在很多推理模型(比如 o1 系列、DeepSeek-R1)靠「写很长的思考过程」来解题,业界默认「想得越多 = 答得越好」。这篇论文正面挑战了这个假设。
研究发现:拿同一个问题让模型生成多条推理链,最短的那条答对的概率比最长的高出 34.5%。换句话说,模型在「想清楚了」的时候往往言简意赅,在「说了很多废话」的时候反而容易绕进去出不来。
他们提出了
short-m@k 方法:同时跑 k 条推理链,哪条先推完就用哪条,最后多数投票选答案。short-1@k:速度快,推理 token 少 40%,准确率和原来基本持平甚至更好short-3@k:快 33%,准确率全面超过标准多数投票
还有一个有趣的发现:用短推理链微调的模型,性能比用长链子微调的更好——意味着未来训练策略可能要翻案。
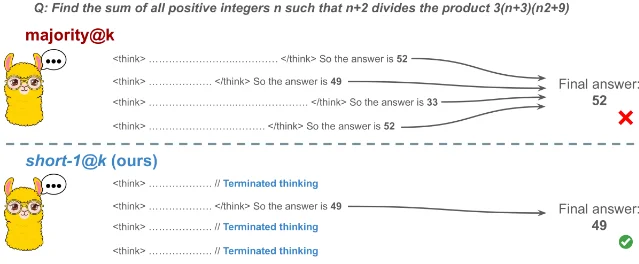
这对实际工程有直接价值:推理更快、token 消耗更少,同样的硬件能处理更多请求。
🌍 Gamma-World:让多智能体协作构建游戏世界
109 票 | NVIDIA
3一句话:打破「两个 AI 对打」的框架,构建多个智能体共同生成动态游戏世界的系统。
它解决什么问题? 以往的多智能体世界建模研究大多只涉及两个玩家(比如围棋、StarCraft 1v1)。现实场景更复杂——想象多人在一个开放世界里互动,每个智能体都有不同的目标和行为逻辑。
Gamma-World 的核心是让多个 AI 智能体协同生成一个开放的游戏世界,而不是预先设计好规则、让 AI 在里面玩。这更接近「世界模型」的终极形态:AI 不只是玩家,也是世界本身的构建者。
NVIDIA 做这个,背后的潜在应用方向包括游戏 NPC、自动驾驶仿真、机器人训练环境等。
📊 ProRL:推荐系统主动学习怎么推
73 票 | 复旦大学
4一句话:用强化学习让推荐系统从「被动等用户点击」变成「主动猜用户下一步想要什么」。
区别在哪里? 传统推荐系统是「反应式」的——用户点了什么,系统根据历史推相关内容。这篇论文想做「预测式」推荐:系统学会主动预判用户需求,在用户明确表达之前就推出用户接下来会想看的东西。
难点是这种预判的奖励信号非常稀疏——大多数时候推了也不知道对不对,用标准强化学习收敛很慢。他们提出 **Rectified Policy Gradient Estimation(修正策略梯度估计)**来解决这个训练稳定性问题。
🤔 用强化学习预测未来真实事件
3 票 | Lightning Rod Labs
5一句话:训了一个 14B 小模型,专门预测真实事件的概率,在预测市场模拟中收益超 10%。
背景:RLVR(用可验证奖励做强化学习)在数学、代码领域已经效果显著。这篇论文把它用在一个完全不同的地方:预测真实世界未来发生什么。
他们用预测市场(Polymarket)的历史题目做训练数据,每道题都是「XX 事件会在 XX 时间前发生吗」这类问题,答案最终可以验证。训出来的 14B 模型在概率预测的准确率上追上甚至超过 o1,校准性(预测的置信度与实际频率的匹配程度)大幅改善。
实测在 Polymarket 模拟交易中,这个模型的投注方式能产生 10%+ 的回报率。
对 AI 从业者的意义:这个方向可能开启「让 AI 做量化预测工具」的新赛道,不局限于数学证明或代码生成。
🛡️ 防止 LLM 被「去拒绝化」攻击
6 票 | KAUST
6一句话:用「附带解释的拒绝回答」来训练模型,让它对 abliteration 攻击免疫。
什么是 abliteration 攻击? 这是一种针对大模型安全对齐的攻击方式:找到模型内部控制「拒绝行为」的单一神经方向,把它压制掉,这样模型就不会再拒绝有害请求了。用这种方法,普通模型的拒绝率会从接近 100% 跌到 20-30%。
防御思路:与其让「拒绝」压缩在一个神经方向上,不如把它分散开。做法是构建一个特殊训练集——有害问题不只是冷冰冰地被拒绝,而是先解释「为什么这个请求有问题」,再拒绝。这样拒绝信号分布在更多 token 位置上,单方向压制就没那么有效了。
效果:对 Llama-2-7B-Chat 和 Qwen2.5-Instruct,攻击后拒绝率只下降 10% 以内,而未防御的基线下降 70-80%。
标题里「Embarrassingly Simple」是学术幽默——说这个防御方案简单得出奇,却很管用。

🎮 Sparc3D:高分辨率 3D 形状生成
11 票
7一句话:用稀疏表示解决 3D 生成中的细节丢失问题,分辨率提到 1024³。
背景:生成 3D 物体比生成 2D 图片难得多——网格数据没有规则结构,体素网格的复杂度是立方增长的。当前主流方法先用 VAE 压缩,再用扩散模型生成,问题是 VAE 压缩时容易丢失细节。
Sparc3D 的解法是两步走:
- Sparcubes:把网格转换为高分辨率(1024³)的稀疏表示,只在物体表面的位置存数据,空间大幅节省
- Sparconv-VAE:基于稀疏卷积的 VAE,压缩和重建都在稀疏域进行,和 3D 数据的模态完全对应,细节损失小
结果是在复杂形状(开放曲面、断开部件、精细几何)上的重建质量明显提升。
今日总览
| 论文 | 核心方向 | 上票数 |
|---|---|---|
| NovelSeek | AI 自主科研 | 121 |
| Gamma-World | 多智能体世界建模 | 109 |
| ProRL | 主动式推荐系统 | 73 |
| Don't Overthink it | 推理效率 | 58 |
| ResearchMath-14K | 数学推理数据集 | 35 |
| MemTrace | LLM 内存错误归因 | 33 |
| RLVR for Future Prediction | 概率预测 | 3 |
| Sparc3D | 3D 生成 | 11 |
| LLM Abliteration Defense | 安全攻防 | 6 |
今日论文集中在两个方向:AI 做科研(NovelSeek、Gamma-World、ResearchMath-14K 都在往这走)和推理效率(「别想太多」那篇直接挑战了主流训练范式)。如果你对 AI Agent 做研究感兴趣,NovelSeek 和它的 GitHub 值得深看;如果你在做推理模型或部署优化,「短推理链」那篇有直接可用的工程结论。
参考来源
- 1NovelSeek: When Agent Becomes the Scientist
- 2Don't Overthink it: Preferring Shorter Thinking Chains for Improved LLM Reasoning
- 3Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
- 4ProRL: Effective Reinforcement Learning for Proactive Recommendation
- 5Outcome-based Reinforcement Learning to Predict the Future
- 6An Embarrassingly Simple Defense Against LLM Abliteration Attacks
- 7Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
围绕这条内容继续补充观点或上下文。