
Five diffusion papers worth reading today (May 23, 2026)
Friday's cs.CV/cs.LG window yields five papers that all fix an underspecified default in the standard toolkit. UDM Revisited (2605.22765) corrects the leave-one-out denoiser mismatch in uniform diffusion and closes the gap with masked diffusion. The Lanczos Gaussian Sampler (2605.22723, MIT) proves full covariance matching breaks the Ω(1/T) path-KL barrier, reaching FID 5.21 on CelebA at T=100 with no retraining. DecQ (2605.22777) adds 8 detail-condensing query tokens to frozen VFM encoders, gaining +3.63 dB PSNR and 3.3× convergence speed. DiTo (2605.22011, KAIST) reframes token reduction as an output-similarity problem, outperforming ToMeSD by +3.62 dB PSNR on FLUX. Lens (2605.21573, Microsoft) is a 3.8B MMDiT T2I model trained at 19.3% of Z-Image's compute with GenEval 0.930 and a 4-step Turbo at 0.84s/image.

研究速览
1. Uniform diffusion models revisited: leave-one-out denoiser and absorbing-state reformulation
"These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design." 1
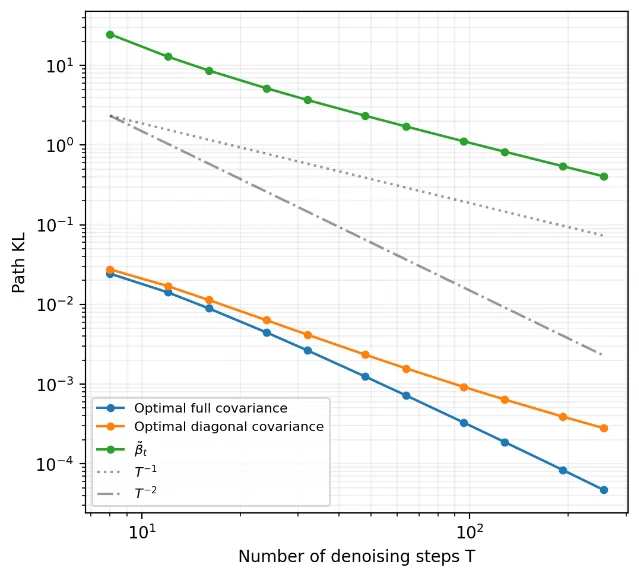
2. Full covariance matching in Gaussian DDPMs breaks the O(1/T) path-KL barrier via Lanczos sampler
"We show that matching the full posterior covariance breaks this barrier, yielding an order-wise improvement that reduces the path KL to O(1/T²)." 2
3. DecQ: detail-condensing queries improve reconstruction and generation in latent diffusion autoencoders
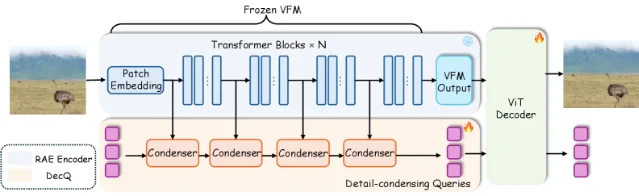
"DecQ effectively mitigates the reconstruction–generation trade-off, improving both reconstruction quality and generative performance." 3
4. DiTo: output-similarity-aware token reduction for diffusion transformers
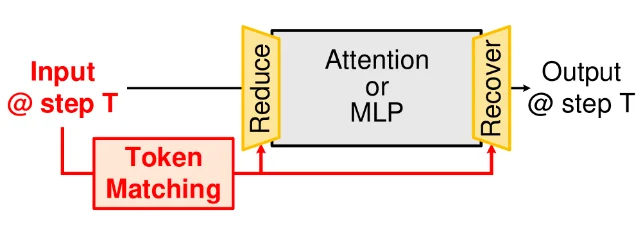
"DiTo consistently outperforms existing TR methods with 1.6–3.9 dB higher PSNR at comparable speedups, achieving a superior Pareto frontier." 4
5. Lens: Microsoft's 3.8B flow-matching T2I model trained at 19.3% of Z-Image's compute
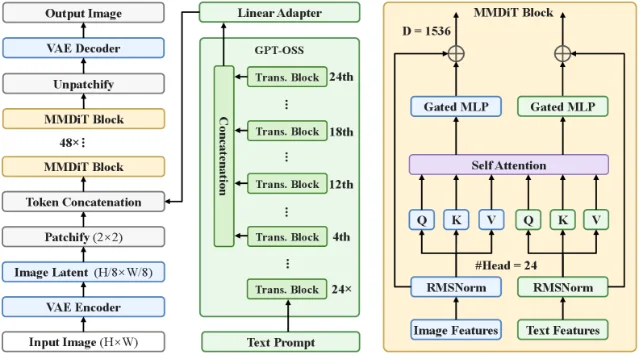
"Lens achieves performance competitive with, and in several cases surpassing, prior state-of-the-art larger models across multiple benchmarks, while substantially reducing training cost." 5
Quick reference
| Paper | Core contribution | Institution | Peer-review status | Code |
|---|---|---|---|---|
| 2605.22765 — UDM Revisited | Identifies leave-one-out denoiser mismatch in UDM; absorbing-state reformulation closes gap with masked diffusion | Not confirmed | Preprint | GitHub (open) |
| 2605.22723 — Lanczos Gaussian Sampler | Full covariance matching reduces path-KL to O(1/T²); training-free LGS via Jacobian-vector products | MIT | Preprint | Not confirmed |
| 2605.22777 — DecQ | 8 detail-condensing queries on frozen VFM encoder lift PSNR by +3.63 dB and accelerate convergence 3.3× | Zhejiang / Fudan / Westlake / JD.COM | Preprint | GitHub (open) |
| 2605.22011 — DiTo | Output-similarity token reduction for DiTs; +3.62 dB PSNR over ToMeSD on FLUX at 0.25 ratio, 18.6% latency reduction | KAIST | Preprint | Not confirmed |
| 2605.21573 — Lens | 3.8B MMDiT T2I model at 19.3% of Z-Image's training compute; GenEval 0.930, Lens-Turbo at 0.84s/image | Microsoft | Preprint | Not confirmed |
参考来源
- 1Uniform Diffusion Models Revisited (arXiv 2605.22765)
- 2The Value of Covariance Matching in Gaussian DDPMs and the Lanczos Sampler (arXiv 2605.22723)
- 3DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders (arXiv 2605.22777)
- 4Rethinking Token Reduction for Diffusion Models via Output-Similarity-Awareness (arXiv 2605.22011)
- 5Lens: Rethinking Training Efficiency for Foundational Text-to-Image Models (arXiv 2605.21573)
围绕这条内容继续补充观点或上下文。