TTSModelSettings 7 个字段总览
SDK v0.16.1 · TTSModel 配置参数
从「复制 quickstart 就以为会了」的真实踩坑切入,系统拆解 VoicePipeline 内部实现。覆盖三步流水线全景(AudioInput vs StreamedAudioInput 分发逻辑)、STT/TTS 模型替换两条路径(直接传实例 vs VoiceModelProvider 依赖注入)、TTSModelSettings 7 个字段深度拆解(含 instructions 默认值设计哲学与 text_splitter 中文场景调优)、VoiceWorkflowBase 与 SingleAgentVoiceWorkflow 适用场景对比、StreamedAudioResult 三种 VoiceStreamEvent 消费完整代码与两大生产坑、VoicePipelineConfig 10 个字段三组分类记法,以及 StreamedTranscriptionSession 与 StreamedAudioResult 的类名澄清(SDK 中不存在 VoiceStreamingSession)。附生产环境最佳实践代码与 3 条落地建议。
研究速览
VoicePipeline 的官方定位是「An opinionated voice agent pipeline」1。所谓 opinionated,意思是 SDK 已经替你做了很多决定——你只需要关注业务逻辑。AudioInput ──→ [1] STT(转录) ──→ [2] Workflow(你的代码) ──→ [3] TTS ──→ StreamedAudioResultpipeline = VoicePipeline(
workflow=my_workflow, # 必选:你的业务逻辑
stt_model=None, # 可选:默认用 OpenAI
tts_model=None, # 可选:默认用 OpenAI
config=None, # 可选:默认 VoicePipelineConfig()
)run() 方法签名只有一行:result: StreamedAudioResult = await pipeline.run(audio_input)audio_input 的类型决定走哪条内部路径2。| 输入类型 | 内部方法 | 交互模式 |
|---|---|---|
AudioInput | _run_single_turn() | 录音 → 处理 → 结束 |
StreamedAudioInput | _run_multi_turn() | 持续对话,直到流关闭 |
workflow.on_start() 播放欢迎语,然后创建 StreamedTranscriptionSession,循环 transcribe_turns() 逐轮处理。class MySTTModel(STTModel):
@property
def model_name(self) -> str:
return "deepgram-nova-2"
async def transcribe(
self, input: AudioInput, settings: STTModelSettings,
trace_include_sensitive_data: bool,
trace_include_sensitive_audio_data: bool,
) -> str:
# 调用你的 STT API,返回转录文本
...
async def create_session(
self, input: StreamedAudioInput, settings: STTModelSettings,
trace_include_sensitive_data: bool,
trace_include_sensitive_audio_data: bool,
) -> StreamedTranscriptionSession:
# 返回支持 transcribe_turns() 的会话对象
...trace_include_* 参数控制追踪时是否包含敏感内容——生产环境传 False,避免音频数据写入追踪日志。pipeline = VoicePipeline(
workflow=workflow,
stt_model=MySTTModel(), # 直接传实例,绕过 provider
)class MyProvider(VoiceModelProvider):
def get_stt_model(self, name: str | None) -> STTModel:
if name == "deepgram":
return DeepgramSTTModel()
return OpenAISTTModel(name)
def get_tts_model(self, name: str | None) -> TTSModel:
...
config = VoicePipelineConfig(model_provider=MyProvider())
pipeline = VoicePipeline(workflow=workflow, config=config)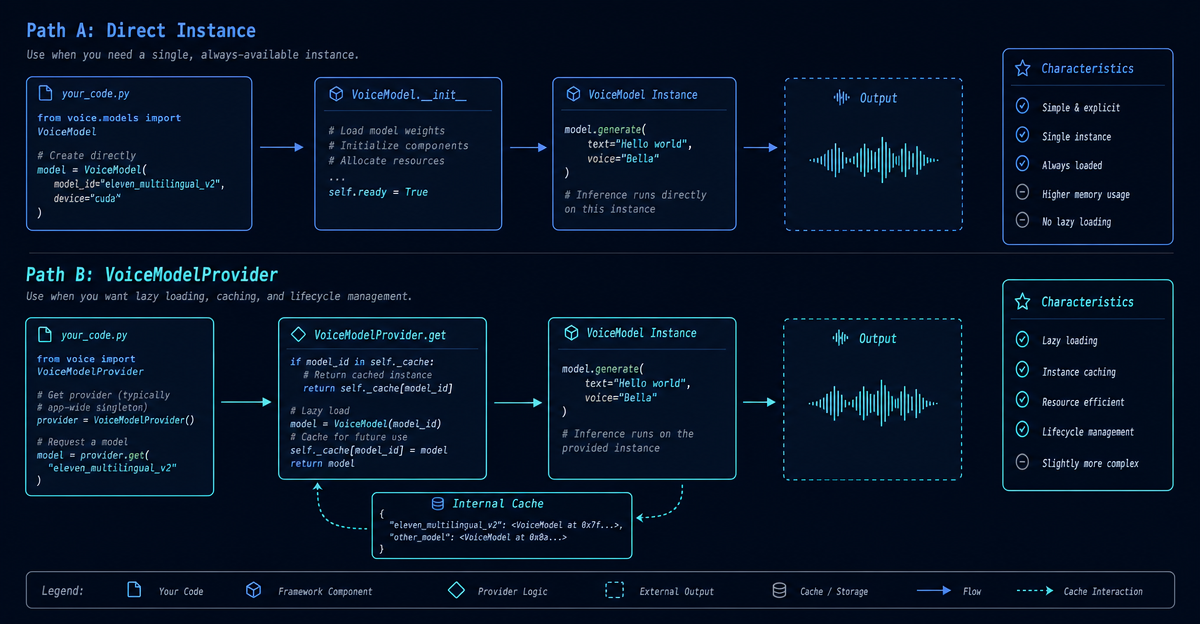
TTSModelSettings 是 Voice Pipeline 里最复杂的配置对象,同时控制语音质量、音频格式和流式策略3。voice:可选 alloy、ash、coral、echo、fable、onyx、nova、sage、shimmer,传 None 使用模型默认。instructions:默认值是 "You will receive partial sentences. Do not complete the sentence just read out the text."——设计意图很精妙。因为 Workflow 的文本输出是流式增量,TTS 随时可能收到半句话。这条指令告诉模型:不要脑补,照读就行。如果你换成自定义 instructions,要注意不要覆盖这个约束,否则 TTS 会补全句子导致语义重叠。text_splitter:签名是 (buffer: str) -> tuple[str, str],返回 (要发送给 TTS 的文本块, 剩余缓冲区)。默认实现是基于句子边界分割,触发条件是文本块长度 ≥ 20 字符。如果你的 workflow 输出的是中文短句,可以调低这个阈值,否则会等很久才开始朗读。buffer_size:默认 120。TTS 模型返回的 PCM 字节片段会先累积,直到片段数量 ≥ 120 时合并转换 dtype 后一次性发出 VoiceStreamEventAudio。降低这个值可以减少首帧延迟,但会增加事件频率。speed:范围 0.25~4.0,None 表示模型默认。VoiceWorkflowBase 只要求实现一个抽象方法4:class MyWorkflow(VoiceWorkflowBase):
async def run(self, transcription: str) -> AsyncIterator[str]:
# 接收转录文本,产出待朗读的文本流
result = await Runner.run_streamed(my_agent, transcription)
async for chunk in VoiceWorkflowHelper.stream_text_from(result):
yield chunk
async def on_start(self) -> AsyncIterator[str]:
# 可选:多轮模式的欢迎语,通过 TTS 播放
yield "你好,有什么可以帮你的?"VoiceWorkflowHelper.stream_text_from() 专门监听 response.output_text.delta 事件,把 LLM 的流式文本 delta 转成 run() 需要的 AsyncIterator[str]——这个 helper 省掉了不少样板代码。SingleAgentVoiceWorkflow 就够了4:from agents.voice import SingleAgentVoiceWorkflow
pipeline = VoicePipeline(
workflow=SingleAgentVoiceWorkflow(my_agent),
)SingleAgentVoiceWorkflow 内部做了三件事:每轮把转录追加到 _input_history({"role": "user", "content": transcription});调用 Runner.run_streamed(self._current_agent, self._input_history);更新 _input_history = result.to_input_list() 和 _current_agent = result.last_agent。_current_agent 会随着 handoff 动态切换。如果你的 Agent 有 handoff 逻辑,SingleAgentVoiceWorkflow 已经替你处理了。my_workflow.py 中的 secret_word 分支5)StreamedAudioResult.stream() 产出的不是单一的音频事件,而是三种类型6:# VoiceStreamEvent 是 TypeAlias:
# VoiceStreamEventAudio | VoiceStreamEventLifecycle | VoiceStreamEventError
async for event in result.stream():
if event.type == "voice_stream_event_audio":
# event.data: NDArray[np.int16 | np.float32] | None
audio_player.write(event.data)
elif event.type == "voice_stream_event_lifecycle":
# event.event: "turn_started" | "turn_ended" | "session_ended"
if event.event == "turn_started":
print("[新一轮 TTS 开始]")
elif event.event == "turn_ended":
print("[当前轮播放完毕]")
elif event.event == "session_ended":
print("[整个会话结束]")
break
elif event.type == "voice_stream_event_error":
# event.error: Exception
print(f"[错误] {event.error}")turn_started:StreamedAudioResult._start_turn() 调用时,每轮 TTS 开始前触发turn_ended:当前轮 TTS 完成(finish_turn=True)后触发session_ended:_dispatch_audio() 完成所有分派,整个会话结束时触发voice_stream_event_audio 的 data 字段可以是 None——处理前要判空session_ended 才能知道什么时候关闭播放器;只监听音频事件会漏掉会话结束信号| 字段 | 默认值 | 说明 |
|---|---|---|
model_provider | OpenAIVoiceModelProvider() | 语音模型提供器,自定义时传子类实例 |
stt_settings | STTModelSettings() | STT 行为配置(prompt / language / temperature / turn_detection) |
tts_settings | TTSModelSettings() | TTS 行为配置(voice / speed / buffer_size 等 7 项) |
| 字段 | 默认值 | 说明 |
|---|---|---|
tracing_disabled | False | 设为 True 完全关闭追踪 |
tracing | None | 自定义 TracingConfig |
trace_include_sensitive_data | True | 是否在追踪中包含文本内容 |
trace_include_sensitive_audio_data | True | 是否在追踪中包含音频数据 |
trace_metadata | None | 附加到追踪的自定义元数据字典 |
| 字段 | 默认值 | 说明 |
|---|---|---|
workflow_name | "Voice Agent" | 追踪中 workflow 名称,多个 pipeline 时用于区分 |
group_id | gen_group_id() | 追踪分组 ID,同一会话的多轮可以共享同一 group_id |
config = VoicePipelineConfig(
trace_include_sensitive_audio_data=False, # 别把用户声音存进追踪
trace_include_sensitive_data=False, # 别把转录文本存进追踪
workflow_name="客服语音 v2",
tts_settings=TTSModelSettings(
voice="nova",
speed=1.1,
buffer_size=80, # 降低首帧延迟
),
stt_settings=STTModelSettings(
language="zh", # 指定中文,提升转录准确率
),
)StreamedTranscriptionSession:STT 层的流式会话,由 STTModel.create_session() 返回,暴露 transcribe_turns() 和 close() 方法——这是多轮对话持续接收音频并逐轮输出转录文本的对象3StreamedAudioResult:Pipeline 输出层的事件流,由 pipeline.run() 返回,暴露 stream() 方法产出三种 VoiceStreamEvent7VoiceStreamingSession 这个类——如果你在别处看到这个名字,那是文档错误或混淆写法。SingleAgentVoiceWorkflow,有定制需求再自定义 Workflowon_start()、run()、历史管理三件事,别提前给自己加负担。StreamedAudioInput,一定要处理 session_endedvoice_stream_event_audio,等音频停了再用定时器判断"应该结束了"。正确做法是监听 session_ended——StreamedAudioResult._done() 里明确会发这个信号,不要绕过它。trace_include_sensitive_audio_data=True 是默认值,意味着用户录音会出现在 Traces 里。如果你的服务涉及个人隐私,上线前第一件事是把这两个追踪开关改成 False。下期预告 #19:进入语音子系统的另一半——Realtime Agents 内部的RealtimeAgent、RealtimeSession、事件处理器完整解析,以及与 Voice Pipeline 在实际项目中如何做最终选型。
围绕这条内容继续补充观点或上下文。