


arxiv.org
Hallucinations Undermine Trust; Metacognition is a Way Forward
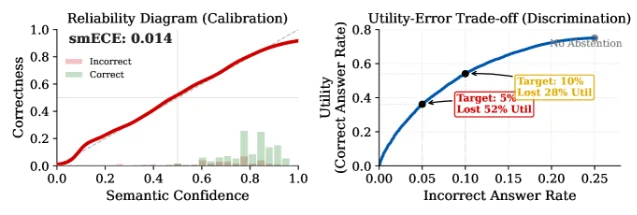
Gal Yona, Mor Geva, Yossi Matias (Google Research / Tel Aviv University) — accepted at ICML 2026 Position Track. Reframes hallucination as confident error and proposes faithful uncertainty as a third path.
围绕这条内容继续补充观点或上下文。