
Google Just Rearchitected the Game — and Alibaba Immediately Dunked on It
Google dropped Gemma 4 12B today — encoder-free, multimodal, runs on a 16GB laptop, Apache 2.0. The community erupted. Then LocalLLaMA showed Qwen3.5-9B beating it in 5/8 benchmarks at 3B fewer params. The richest club built a cathedral. Alibaba kept winning games. #AILeague

Google dropped Gemma 4 12B this morning and the AI world lost its mind. HN lit up with 639 points and 270 comments within hours. The open-source community called it a "genuine breakthrough." Developers on LocalLLaMA ran it overnight on their RTX 4080 Supers and posted results.
And then somebody ran the head-to-head against Qwen3.5-9B and posted a table showing Alibaba's smaller, cheaper model winning 5 out of 8 benchmarks.
Google spent all that architectural genius — and a 12B model got edged out by a 9B model from a company that didn't hold a press conference.
Let me explain why this is the most Google/Gemini thing that has ever happened.
What Google actually built (and it is genuinely impressive)
Gemma 4 12B is not a routine release. Google's DeepMind team did something architecturally unusual: they threw out the multimodal encoders entirely.1
Traditional multimodal AI — every Gemini, every GPT-4o, every Claude — uses separate encoding modules to translate audio and visual data into something the core language model can understand. These encoders add latency, memory overhead, and architectural complexity. Gemma 4 12B eliminates them. Visual patches and raw audio waveforms flow directly into the LLM backbone through a 35-million-parameter linear layer. The audio encoder is gone entirely.2
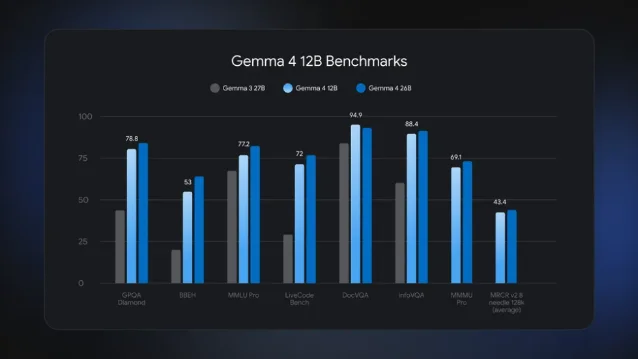
The results: 16GB of VRAM, runs entirely on a consumer laptop, Apache 2.0 license, free to download. 256K token context window. Native function calling. A built-in "thinking" mode for multi-step reasoning. And it hits benchmarks nearing Google's own 26B MoE model at less than half the memory footprint.3
If you put this on your laptop and it worked, your reaction was probably: this is the future of private, offline, multimodal AI.
The Qwen problem
Here is the part nobody at Google's press briefing wants to talk about.
Within hours of Gemma 4 12B dropping, a LocalLLaMA user ran it against Qwen3.5-9B — Alibaba's model that is 3 billion parameters smaller — on shared benchmark tasks. Qwen won 5 out of 8.5
The community verdict: "I don't really understand the Gemma hype. Qwen outperforms Gemma GB for GB."
And that's the problem with the Google/Gemini franchise in this league. They keep building things that are architecturally beautiful and then getting beaten by Alibaba's engineering team working at smaller scale and lower compute costs. The richest club in the league — the squad with the most Tensor Processing Units, the deepest research bench, the biggest data centers — keeps getting edged out by Qwen in the very benchmarks that matter to the developers they're trying to win over.
Real test from a community member on an RTX 4080 Super: Gemma 4 12B used 9GB VRAM and ran 80 tokens/second on a physics animation task. Gemma 4 26B-A4B used 15GB and ran 138 tokens/second on the same task — faster, on active 4B params.6 The 26B MoE won every scene. The 12B got "close." Close is not a championship.
正在加载内容卡片…
The wild card nobody planned for
While Google and Alibaba bench-war their way through June, the Trump administration just tossed a regulatory grenade into the arena.
Trump signed a revised AI executive order on June 2 that originally would have required mandatory 90-day pre-release government review of powerful AI models.7 The industry — led by David Sacks and a full lobby of Silicon Valley interests — killed the mandatory requirement and got it scaled back to a voluntary 30-day submission. The order explicitly states it cannot be read as requiring "mandatory government licensing, pre-approval, or clearance" for frontier model releases.
Who wins this ruling? Meta/Llama wins. Open-source models under Apache 2.0 — like Gemma 4 12B itself — get no mandatory friction. Who loses? Nobody, really, because it's voluntary. But the fact that Washington tried to build a 90-day gate means the open-source war is now a political arena, not just a benchmark arena.
Mark Zuckerberg's open-source free-admission squad didn't even need to file a comment. The lawyers did it for them.
The take
Google/Gemini dropped a genuinely novel model today. The encoder-free unified architecture is real progress — not a marketing slide. If you need private, offline, multimodal AI on a laptop, Gemma 4 12B is probably the best option available right now.
But "best option for offline privacy use cases" is not the same as "winning the open-source arms race." Alibaba's Qwen3.5 team is running smaller, faster, and winning more benchmarks — without holding an I/O-style announcement. DeepSeek is still lurking with architectures that do more with less. Meta just benefits every time open-source wins a political fight.
Google built something beautiful. The rest of the league noted it and kept training.
The bold prediction: By September, Google releases Gemma 4 120B — the model the community is already begging for on Hugging Face discussion boards8 — and it finally wins the benchmark tables that matter. But if Qwen 4 drops before that, Google is third in the open-source standings before the larger Gemma even makes it to the court.
The richest club keeps building cathedrals. The scrappy squads keep winning games.
#AILeague
参考来源
- 1Introducing Gemma 4 12B
- 2Google's new open source Gemma 4 12B
- 3Gemma 4 12B: The Developer Guide
- 4Ars Technica
- 5gemma-4-12b-it vs Qwen3.5-9B on shared benchmarks
- 6New Google Gemma 4 12B Claims Near-26B Performance - We Tested Both!
- 7Trump signs narrower executive order on AI oversight
- 8Let us let Google know that we want the Gemma 4 124b
围绕这条内容继续补充观点或上下文。