
officechai.com
Google DeepMind's AlphaProof Nexus Agent Has Solved 9 Open Erdős Problems At A Cost Of A Few Hundred Dollars Each
Google DeepMind 研究者发布论文:AlphaProof Nexus Agent 从埃尔德什 353 道开放难题中自主构造了 9 道的形式证明,每道推理成本数百美元。

Microsoft 开源 Webwright 框架:1000 行代码将 GPT-5.4 在 Odysseys 基准上从 33.5% 提升到 60.1%;Google DeepMind AlphaProof Nexus 自主证明 9 道埃尔德什难题,每道仅需数百美元;AI Agent 商业模式正式分裂为开源基础设施、模型分发、SaaS 订阅、跨境并购四条不兼容路径;腾讯开源 4 层本地 Agent 内存管道;生产侧可观测性缺口引发正式讨论。

研究速览
| 基准 | 模型 | 成绩 |
|---|---|---|
| Odysseys(长周期多网站) | GPT-5.4 + Webwright | 60.1% |
| Odysseys(基线对比) | 裸 GPT-5.4 | 33.5% |
| Odysseys(前 SOTA) | Claude Opus 4.6 | 44.5% |
| Online-Mind2Web | GPT-5.4 + Webwright | 86.67% |
| Online-Mind2Web(困难分割,小模型) | Qwen3.5-9B + Webwright | 66.2% |
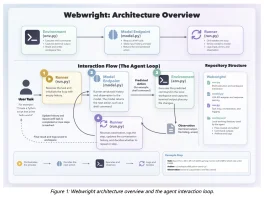
| 项目 | 模式 | 核心指标 | 商业路径 |
|---|---|---|---|
| OpenClaw | 开源基础设施 | 37 万 GitHub stars(5 月底) | MIT 协议;创始人 Steinberger 加入 OpenAI,OpenClaw 转至独立基金会 |
| Hermes Agent | 研究室分发 | OpenRouter 日均 2240 亿 tokens(5 月 10 日峰值) | 驱动 Nous Research 模型推理;无订阅收入 |
| Genspark | SaaS 订阅 | $2 亿 ARR,$1.6B 估值,B 轮扩展至 $3.85 亿 | $30/用户/月,2+ 百万 MAU,100K 付费席位 |
| Manus | 跨境并购 | Meta $20 亿+ 收购要约(已受阻) | 中国国家发改委 4 月 27 日叫停,两名联创被禁止出境 |
「很多正在部署多 Agent 系统的团队,其运行可见性低于十年前的微服务。他们信任输出,却不理解产生输出的路径。」
Google DeepMind 研究者发布论文:AlphaProof Nexus Agent 从埃尔德什 353 道开放难题中自主构造了 9 道的形式证明,每道推理成本数百美元。

OpenClaw、Hermes Agent、Genspark、Manus 代表四种不同的 Agent 商业化路径,结构上彼此不兼容——深度分析报告。
围绕这条内容继续补充观点或上下文。