Disaggregation: production signals (May 2026)
Recent data points confirming PD disaggregation as production standard

Production LLM teams are paying for GPU capacity running at 16% memory bandwidth utilization while dashboards report 90% GPU utilization — the wrong metric entirely. This brief explains disaggregated inference (splitting prefill and decode onto separate GPU pools), documents the 2026 shift to production standard (llm-d/CNCF, Baseten, Databricks), covers the emerging Attention-FFN Disaggregation layer for MoE models, and closes with three concrete PM actions.

| Level | What gets separated | Primary win | Representative tooling |
|---|---|---|---|
| Prefill-Decode (PD) | Prefill and decode onto separate GPU pools | 2–4× throughput, lower TTFT P99 | vLLM PDD, SGLang EPD, NVIDIA Dynamo |
| Dynamic PD (DOPD) | P/D ratio adjusts in real time with ARIMA load prediction | SLO attainment 80.8% → 99.4%, P90 TTFT −67.5% | DOPD (arXiv:2511.20982) 3 |
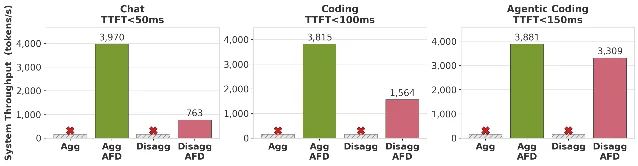
| Attention-FFN (AFD) | Attention operators and MoE-FFN operators onto different GPU groups | Required for sub-150ms TTFT SLOs on large MoE models | AIC++ / vLLM AFD prototype (arXiv:2605.28302) 4 |
围绕这条内容继续补充观点或上下文。