OpenAI Agents SDK #7:Tracing——让 Agent 的每一步都「可见」
从「Agent 出了 bug 不知道哪一步出问题」这个开发者最真实的痛点切入,系统讲解 OpenAI Agents SDK 内置 Tracing 模块的两层核心架构(Trace/Span)、Agent Loop 全链路 Span 类型(AgentSpanData/LLMSpanData/ToolSpanData/HandoffSpanData/CustomSpanData)、trace() 与 custom_span 手动追踪 API、内置 BatchTraceProcessor 与 20+ 第三方平台接入、自定义 Processor 接口实现,以及三个实用控制开关(禁用追踪/敏感数据过滤/group_id 会话关联)。结尾附 4 条可落地实践建议,并预告下一篇 Guardrails。
研究速览
Agent 出了 bug,你打算怎么查?
打印几行日志?加几个
print()?然后盯着终端输出,猜哪一步出了问题——是 LLM 理解错了指令,还是工具调用返回了奇怪的值,还是 Handoff 把任务交给了错误的子 Agent?这是多 Agent 开发里最经典的噩梦:系统跑起来了,但当它出错的时候,你根本不知道哪一步出的问题1。
OpenAI Agents SDK 的 Tracing 模块,就是为了解决这个问题而生的。
为什么 Agent 调试这么难?
普通函数出了 bug,堆栈追踪直接指向错误行。但 Agent 不一样。
一次 Agent Run 可能包含:多轮 LLM 调用、若干工具调用、一次或多次 Handoff,每个步骤都有输入和输出,每个环节都可能是问题根源。没有可观测性,这就是一个黑盒2。
更头疼的是:当你有多个 Agent 协作,每个 Agent 又会调用工具、触发 Handoff,整个调用链条呈树状展开,靠
print() 根本追不住。LangChain 团队做 Agent 调试时得出过一个结论:在模型是黑盒的前提下,Tracing 是观测 Agent 行为的唯一途径,而 Traces 数据也是后续优化的原材料3。
Tracing 的本质:两层结构
OpenAI Agents SDK 内置了一套追踪系统,架构上只有两个概念,但层级分明4:
Trace——代表一次端到端的工作流。你运行一次
Runner.run(),就产生一个 Trace。它是最顶层的容器,记录这次 Agent 执行的全貌。Span——代表 Trace 内部某个具体操作,有明确的开始和结束时间。每次 LLM 调用、每次工具执行、每次 Handoff,都是一个 Span。Span 可以嵌套,形成树状层级。
可以这样理解:Trace 是一场手术的完整记录,Span 是手术里每一个操作步骤——主刀切开、麻醉给药、止血缝合,每一步有开始时间、结束时间、成功与否。这个比喻在「边界」处不成立的地方是:手术步骤通常串行,而 Agent 的 Span 可以并发执行。
SDK 默认自动追踪所有内容,包括 LLM 生成、工具调用、Handoffs、Guardrails 和自定义事件,什么都不用配,运行就有4。
Agent Loop 的全链路 Span
一次完整的 Agent Run,SDK 会记录哪些 Span?
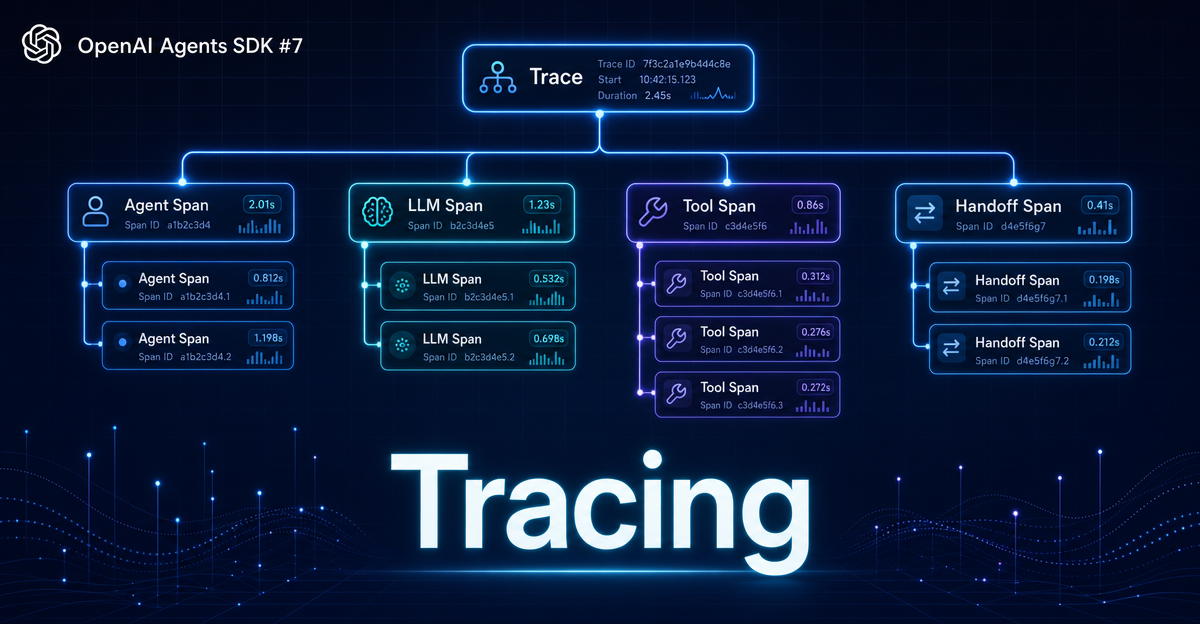
以一个简单的客服 Agent 为例,当它收到用户提问、查询知识库、回答问题、转接人工客服,整个过程的 Span 树大致如下:
Trace: customer-service-run
├── AgentSpan: CustomerServiceAgent
│ ├── LLMSpan: gpt-4o (理解用户问题)
│ ├── ToolSpan: search_knowledge_base (查询知识库)
│ ├── LLMSpan: gpt-4o (生成回答)
│ └── HandoffSpan: → HumanAgentHandoff (转人工)每个 Span 类型对应 SDK 中的一个数据类5:
- AgentSpanData:记录 Agent 名称、工具列表、输出类型
- LLMSpanData:记录模型名称、请求 token、响应内容(可选过滤敏感数据)
- ToolSpanData:记录工具名、输入参数、输出结果
- HandoffSpanData:记录源 Agent、目标 Agent、触发原因
- GuardrailSpanData:记录护栏名称、触发与否、过滤结果
- CustomSpanData:你自定义事件的任意数据
有了这些数据,每次工具调用传了什么参数、LLM 拿到了什么上下文、Handoff 是在第几轮触发的——查 Dashboard 就行,不用猜。
create_trace 和 create_span:手动控制追踪
大多数情况下你不需要手动调用 Tracing API,SDK 会自动处理。但有两种场景需要手动介入:
- 多次
Runner.run()属于同一个逻辑工作流,想把它们归在一个 Trace 下 - 需要追踪 Agent Loop 以外的自定义操作,比如数据预处理步骤
from agents import Runner, trace, custom_span
from agents.tracing import create_trace, create_span
async def run_research_workflow(query: str):
# 用 trace() 创建顶层 Trace,覆盖整个工作流
# workflow_name 会显示在 Dashboard 的 Trace 列表里
with trace("research-workflow", metadata={"query": query}):
# 第一阶段:数据采集(自定义 Span,追踪非 Agent 操作)
with custom_span("data-collection"):
raw_data = fetch_external_data(query) # 你自己的函数
# 第二阶段:Agent 分析(自动产生子 Span)
result = await Runner.run(
research_agent,
input=f"分析以下数据:{raw_data}"
)
# 第三阶段:结果存储(另一个自定义 Span)
with custom_span("result-storage"):
save_to_db(result.final_output)
return result内置 Processor vs 自定义 Processor
Tracing 数据收集了,发到哪里?SDK 通过 TracingProcessor 抽象接口控制这件事5。
默认行为:
BatchTraceProcessor 批量上传到 OpenAI 后端,打开 OpenAI Platform Traces Dashboard 就能看到 Span 树、每步耗时和 LLM 输入输出。接入第三方平台:SDK 已集成 20+ 可观测性平台4,包括:
| 平台 | 特点 |
|---|---|
| Weights & Biases | 适合 ML 实验追踪 |
| Arize Phoenix | 开源,本地部署友好 |
| MLflow | 企业级 MLOps |
| Braintrust | 专为 LLM 评估设计 |
| Langfuse | 开源,社区活跃 |
| LangSmith | LangChain 生态 |
| AgentOps | Agent 专用监控 |
| Pydantic Logfire | Pydantic 团队出品 |
接入方式很简单,以 Langfuse 为例:
from agents import set_trace_processors
from langfuse.openai_agents import LangfuseTraceProcessor
# 替换默认 Processor,追踪数据发往 Langfuse
set_trace_processors([LangfuseTraceProcessor()])
# 或者追加(同时发往多个平台)
# from agents.tracing import add_trace_processor
# add_trace_processor(LangfuseTraceProcessor())如果你用的不是 OpenAI 模型(比如 Claude、Gemini),追踪依然可以工作,只需要:
from agents.tracing import set_tracing_export_api_key
set_tracing_export_api_key("your-openai-api-key") # 仅用于追踪导出,不影响模型调用Tracing 和你用什么模型没有关系——这两件事在 SDK 里是分开的。
自定义 Processor:完全接管追踪流程
如果现有集成不够用,实现
TracingProcessor 接口自己写也不复杂5:from agents.tracing import TracingProcessor, Trace, Span
from agents import add_trace_processor
class MyCustomProcessor(TracingProcessor):
"""把 Trace 数据写入自己的数据库"""
def on_trace_start(self, trace: Trace) -> None:
# Trace 开始时触发:初始化记录
db.insert_trace(trace.trace_id, trace.name, started_at=now())
def on_trace_end(self, trace: Trace) -> None:
# Trace 结束时触发:更新状态
db.update_trace(trace.trace_id, ended_at=now())
def on_span_start(self, span: Span) -> None:
# 每个 Span 开始时触发
db.insert_span(span.span_id, span.trace_id, span.started_at)
def on_span_end(self, span: Span) -> None:
# Span 结束时触发:这里能拿到完整的 span.span_data
# span.span_data 是 AgentSpanData / LLMSpanData / ToolSpanData 等
db.update_span(span.span_id, span.span_data, ended_at=now())
def shutdown(self) -> None:
# 进程退出时调用,做清理工作
db.flush()
def force_flush(self) -> None:
# 长运行应用中立即导出缓冲区
db.flush()
# 注册自定义 Processor
add_trace_processor(MyCustomProcessor())接口就这四个回调,Trace 级别两个、Span 级别两个,数据在参数里直接拿。比自己从头写一套追踪系统省事多了6。
三个实用控制开关
禁用追踪:线上环境有时候不想追踪(成本或隐私原因),在
RunConfig 里关掉:from agents import RunConfig, Runner
result = await Runner.run(
agent,
input="...",
run_config=RunConfig(tracing_disabled=True)
)也可以全局禁用7:
from agents.tracing import set_tracing_disabled
set_tracing_disabled(disabled=True)过滤敏感数据:如果 LLM 的输入输出包含用户隐私,不想上传到第三方,在
RunConfig 关掉:run_config=RunConfig(trace_include_sensitive_data=False)自定义 Trace 元数据:给 Trace 打标签,方便在 Dashboard 里按业务维度过滤8:
run_config=RunConfig(
workflow_name="customer-service", # Dashboard 里显示的工作流名
trace_id="my-custom-id-001", # 自定义 Trace ID,便于关联外部系统
group_id="session-user-123", # 关联同一用户/会话的多次 Run
trace_metadata={"env": "production", "version": "v2.1"}
)group_id 特别有用:同一用户一次对话可能触发多次 Runner.run(),用 group_id 串联起来,在 Dashboard 里就能看到完整对话的全部追踪记录。实际调试场景:快速定位 Agent 异常
拿一个真实的调试场景举例。你的 Agent 偶尔会「卡住」,迟迟不返回结果。
没有 Tracing:只能加 timeout、看有没有抛异常,然后靠经验猜。
有 Tracing:打开 Dashboard,找到那次异常的 Trace,展开 Span 树:
Trace: research-agent-run (耗时 45s ⚠️)
├── AgentSpan: ResearchAgent (45s)
│ ├── LLMSpan: gpt-4o (2s) ✓
│ ├── ToolSpan: web_search (40s ⚠️) ← 就是这里
│ └── LLMSpan: gpt-4o (3s) ✓web_search 耗时 40 秒,显然是外部 API 超时问题,不是 Agent 逻辑问题。五秒钟定位,不需要猜。「可观测性先于多加 Agent」6——系统没复杂到失控之前,先把「看得见」这件事做好。
4 条可立即落地的实践建议
① 先让 Dashboard 跑起来再加功能
新项目第一步不是加工具、不是调提示词——是先跑一次 Agent,打开 platform.openai.com/traces 确认 Trace 数据正常入库。有了基线,后续每次改动都能通过对比 Trace 判断效果。
② 用
group_id 关联用户会话多轮对话场景里,每次
Runner.run() 是独立的 Trace。把同一个 session 的所有 Run 用同一个 group_id 串联,调试时能看到完整的对话流,而不是一堆碎片化的 Trace8。③ 关键业务步骤加
custom_spanAgent Loop 之外的操作——数据预处理、结果后处理、外部系统调用——都加上
custom_span。Tracing 数据才能反映完整的业务链路,而不只是 Agent 内部的执行情况。④ 生产环境选择合适的 Processor
OpenAI Platform Dashboard 适合开发调试,生产环境建议接入 Langfuse 或 Arize Phoenix(都支持自托管),数据不出域,同时有报警和异常检测功能4。
写在最后
Agent 开发的早期,系统对开发者来说就是个黑盒,掌控感极弱2。Tracing 的价值不只是调试工具,它是你对系统建立信任的方式——你能看见它在做什么,才能放心地让它去做。
从 Swarm 实验项目到正式 SDK,「缺追踪」曾经是无法上生产的根本障碍之一9。现在 SDK 把这件事做成了默认行为,一行代码都不需要写,Trace 数据就在 Dashboard 等着你。
下一篇我们聊 Guardrails(防护栏)——如何在 Agent 的输入和输出两端设置自动检查,让系统在失控之前就能踩刹车。
封面图由 AI 生成,主题元素来自 OpenAI Agents SDK Tracing 架构。
围绕这条内容继续补充观点或上下文。