LLM 幻觉抑制月度精选:2026 年 4–5 月
收录 2026 年 4–5 月 20 篇 LLM 幻觉抑制论文精选,涵盖 token 级检测、忠实度评估、解码策略、VLM 缓解与元认知框架,并归纳本月研究热点与空白方向。

研究速览
2026 年 4 月 9 日至 5 月 12 日,arXiv 上与顶级会议(ACL 2026、ICML 2026)相关的幻觉抑制工作密度明显上升。本期收录 20 篇论文,其中 7 篇已被顶会接收——ACL 2026 Main 3 篇(LaaB、Rethinking Evaluation、MPD Oral)、ACL 2026 Findings/Oral 3 篇(FaithLens Findings、CFB、HAVAE Main)、ICML 2026 Position Track 1 篇(Metacognition)。
本期三个值得关注的演进方向:
- 检测粒度下移:从「句子/步骤是否包含幻觉」转向「哪个 token 以多大概率是幻觉」,TokenHD、Sanity Checks、PCNET 均体现这一取向。
- 缓解策略多元化:单一解码约束(CAD 系列)之外,logit-shaping(CFB)、密度估计(PCNET)、正交投影参数编辑(MPD)、注意力干预(HAVAE)四路并进。
- 评估标准重构:Rethinking Evaluation 和 HalluScan 对现有 23 个基准做了系统性梳理,指出 RAG 长上下文和真实噪声标签是两个显著空白——当前检测器在有机 RAG 基准上 F1 无一超过 0.7。
一、检测方法:Token 级与推理感知
TokenHD:可扩展 Token 级幻觉检测
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Scalable Token-Level Hallucination Detection in Large Language Models |
| 场馆/状态 | arXiv 预印本(2605.12384v1) |
| 发表日期 | 2026-05-12 |
| 通讯作者 | Rui Min(香港科技大学 / Sea AI Lab) |
| 开源代码 | github.com/rmin2000/TokenHD |
| 方法类别 | 推理时检测(输出校验) |
核心问题:步骤级过程奖励模型(PRM)需预先切分推理步骤,限制了其在自由格式文本上的适用性。TokenHD 直接在连续 token 流上操作。1
方法亮点:两个核心组件——可扩展数据合成引擎(多 critic 模型交叉标注 + 自适应集成)和重要性加权训练策略,使小参数量检测器能够不依赖步骤分割直接输出 token 级幻觉概率。
实验结果
TokenHD 在数学推理基准上的表现如下:1
| 检测器 | Math-500 S_incor ↑ | Math-500 S_cor ↑ |
|---|---|---|
| GPT-4.1 | 46.60 | — |
| QwQ-32B | 55.05 | — |
| TokenHD-0.6B | 63.64 | 94.83 |
| TokenHD-8B | 68.88 | 98.71 |
S_incor 衡量检测器在错误答案上的召回率,S_cor 衡量其对正确答案的保留率。0.6B 参数的 TokenHD 在两项指标上均超越 QwQ-32B(32B 参数),验证了小型专用检测器在 token 粒度任务上的可扩展性。
Code-Elo 基准上,mix training 后 S_incor 从 49.37 提升至 73.61,说明仅用数学数据训练的检测器在代码领域也有一定的跨域迁移能力。1
与现有方法的差异:相比 PRM,TokenHD 无需定义步骤边界;相比自一致性检查,无需多次采样;检测器参数量(0.6B)远小于被检测模型。

LaaB:逻辑一致性作为桥梁(ACL 2026 Main)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Logical Consistency as a Bridge: Improving LLM Hallucination Detection via Label Constraint Modeling between Responses and Self-Judgments |
| 场馆/状态 | ACL 2026 Main Conference(2605.03971v1) |
| 发表日期 | 2026-05-05 |
| 通讯作者 | Hao Mi(中国科学院) |
| 方法类别 | 输出校验与后处理 |
核心问题:当前检测器通常只利用幻觉的单一侧面——或依赖模型内部的神经不确定性信号,或依赖符号自评(verbalized prompt 的显式判断),两类信号被当作孤立特征处理。2
方法亮点:LaaB 框架引入「meta-judgment」过程——将符号判断标签映射回模型的特征空间,再利用「响应标签 ↔ meta-judgment 标签之间必须满足逻辑约束(相同或相反)」这一先验,驱动神经视角与符号视角的对齐与互学习。2
实验结果:在 4 个公开数据集、4 个 LLM、8 个基线方法的组合评测中验证优越性(具体数值待全文 HTML 发布后补充)。
与现有方法的差异:不新增外部验证器,通过显式建模两类信号的逻辑依赖关系实现增益,思路与 FaithLens 的 RL 奖励设计正交。
Sanity Checks:CoT 检测器的「答案伪影」诊断
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Sanity Checks for Long-Form Hallucination Detection |
| 场馆/状态 | arXiv 预印本(2605.08346v1) |
| 发表日期 | 2026-05-08 |
| 通讯作者 | Manish Bhattarai(Los Alamos National Laboratory) |
| 方法类别 | 评估方法论 / 推理时检测 |
核心问题:基于 CoT(思维链,Chain-of-Thought)推理轨迹的幻觉检测器,其预测能力真的来自推理过程本身吗?3
方法亮点:设计两项「oracle 扰动测试」——Force(保留推理轨迹但替换末尾答案为正确答案)和 Remove(删除明确包含答案的推理步骤)——结果显示现有 CoT 检测器的分类性能主要来源于答案级别的文字伪影,而非轨迹中间的推理过程。3
作者进一步提出 TRACT(基于 hedging trends、step-length dynamics、cross-response vocabulary convergence 等词汇轨迹特征的轻量 scorer),在去除答案伪影后仍保持竞争力。
与现有方法的差异:这篇论文首先是一个诊断工具,而非更好的检测器。它指出「推理感知幻觉检测的核心挑战不是轨迹中缺乏信号,而是未能将其与端点线索隔离」。3 对于准备复现或采用 CoT 检测器的研究者,这个诊断框架值得先跑一遍。
Dynamical Systems:黑盒单次采样检测
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Low-Cost Black-Box Detection of LLM Hallucinations via Dynamical System Prediction |
| 场馆/状态 | arXiv 预印本(2605.05134v1) |
| 发表日期 | 2026-05-06 |
| 通讯作者 | Dan Wilson、Mohamed Akrout |
| 方法类别 | 推理时检测(黑盒) |
核心问题:自一致性检查需要多次采样,成本高;外部知识检索需要额外基础设施。黑盒场景下能否做到一次采样就完成检测?4
方法亮点:将 LLM 视为黑盒动力系统——通过 embedding 模型将输出响应投影到高维流形,分别为「事实状态」和「幻觉状态」拟合 Koopman 算子转移矩阵,基于两个算子的预测残差差值定义异常分数。引入 preference-aware calibration 处理模型风格偏差。4
实验结果:作者声称在三个基准上达到 SOTA 性能且资源开销更低(因全文 HTML 未抓取,具体数值当前不可得)。
与现有方法的差异:Koopman 算子理论来自非线性动力系统分析,将其引入幻觉检测的切入点较新;单次采样的成本优势在 API 密集调用场景有实用价值。
二、检测方法:忠实度与多智能体接地
FaithLens:可解释忠实度检测(ACL 2026 Findings)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | FaithLens: Detecting and Explaining Faithfulness Hallucination |
| 场馆/状态 | ACL 2026 Findings(2512.20182v4) |
| 发表日期 | 2026-04-21 |
| 通讯作者 | Shuzheng Si(清华大学)、Fanchao Qi(DeepLang AI) |
| 开源代码 | 即将发布 github.com/S1s-Z/FaithLens |
| 方法类别 | 输出校验与后处理 |
核心问题:当前忠实度检测模型要么性能强但昂贵(GPT-5.2 推理成本 $15.3/千 token),要么高效但无法提供解释,帮助用户理解为何被判定为幻觉。5
方法亮点:两阶段训练——先用高级 LLM 合成带解释的训练数据(经三重过滤:标签正确性 / 解释质量 / 数据多样性),进行 SFT 冷启动;再用基于规则的 RL 优化(prediction correctness reward + explanation quality reward 双奖励)。最终 8B 模型同时输出二元预测和自然语言解释。5
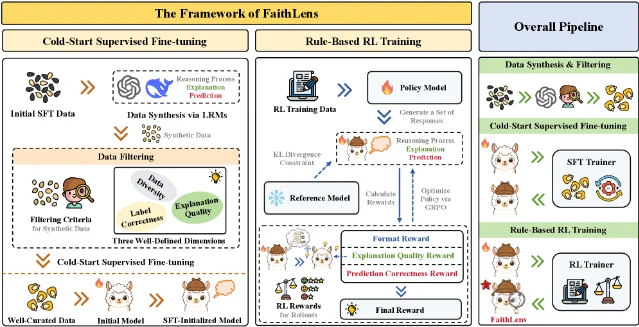
实验结果:LLM-AggreFact(11 个任务)+ HoVer(1 个任务)联合评测,整体 macro-F1 = 86.4(标准差 4.6)。5
| 模型 | macro-F1 | 推理成本($) |
|---|---|---|
| GPT-5.2 | 86.1 | 15.3/千 token |
| DeepSeek-V3.2-Think | 84.4 | — |
| o3 | 82.1 | — |
| MiniCheck(专用检测) | 80.7 | — |
| FactCG(专用检测) | 78.2 | — |
| FaithLens(8B) | 86.4 | 0.1/千 token |
与现有方法的差异:在同等或更高 F1 分数下,推理成本约为 GPT-5.2 的 1/150;同时能够输出可解释的检测理由,而非仅给出二元判断。
GSAR:证据类型化接地与多智能体恢复
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | GSAR: Typed Grounding for Hallucination Detection and Recovery in Multi-Agent LLMs |
| 场馆/状态 | arXiv 预印本(2604.23366v1) |
| 发表日期 | 2026-04-25 |
| 通讯作者 | Federico A. Kamelhar(单作者,机构未披露) |
| 方法类别 | 输出校验与后处理(多智能体场景) |
核心问题:多智能体系统中,接地评估器(groundedness evaluator)通常把所有支持证据视为可互换,只输出单一接地分数,无法对下游恢复行为(是重新生成还是重新规划)提供有区分度的控制信号。6
方法亮点:提出四类证据标注体系——grounded(有明确支撑)、ungrounded(缺乏支撑)、contradicted(与证据矛盾)、complementary(证据补充而非直接支撑,赋予一等地位)——并通过非对称矛盾惩罚计算加权 groundedness 分数。耦合三层决策函数(proceed / regenerate / replan),在显式计算预算下驱动迭代恢复循环。6
实验结果:在 FEVER 数据集(Gold Wikipedia evidence)上,用 4 个独立 LLM judge(GPT-5.4、Claude-Sonnet-4-6、Claude-Opus-4-7、Gemini-2.5-Pro)评估;所有消融方向一致——去除 complementary 类型的消融版本在 Opus 4.7 上 CI 为 [-96, -68]/200,n=1000 时 3 个 judge 收敛至 ΔS(ρ=0)=+0.058。6
注意:本文为单作者提交,无机构信息,同行评审状态未知。
与现有方法的差异:据作者声称,GSAR 是首个将证据类型评分与分层恢复耦合的已发布接地框架。与 Vectara HHEM-2.1-Open 进行了直接对比。
三、评估基准:新基准与方法论反思
Rethinking Evaluation + Trivia++ 基准(ACL 2026 Main)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Rethinking Evaluation for LLM Hallucination Detection: A Desiderata, A New RAG-based Benchmark, New Insights |
| 场馆/状态 | ACL 2026 Main Conference(2605.11330v1) |
| 发表日期 | 2026-05-11 |
| 通讯作者 | Wenbo Chen、Leman Akoglu(Amazon / CMU) |
| 开源数据集 | github.com/amazon-science/hallucination-benchmark-trivialplus |
| 方法类别 | 评估基准构建 |
核心问题:现有幻觉检测基准(HDB)是否满足科学评估的基本要求?23 个现有基准系统地缺失了哪些设计维度?7
方法亮点:提出 HDB 评估的七项 Desiderata(有机幻觉 / 人工验证标签 / 长上下文 / 真实噪声训练标签 / 全面幻觉类型 / 多 LLM / 多领域),审视现有 23 个基准后识别两大缺口,构建新基准 Trivia++:3224 个样本,最长上下文 94K 字符,包含 4 套噪声标签(对应不同标注质量水平)。7
实验结果:三类检测器在 Trivia++ 上的表现:7
| 检测器类型 | Trivia++ F1 |
|---|---|
| SFT 微调模型 | 0.663 |
| SelfCheckGPT(Claude 后端) | 0.675 |
| LLM-as-a-Judge | 0.694 |
对比:同类检测器在注入式幻觉基准 HaluEval 上 SFT F1 = 0.996——注入幻觉的检测难度极低,有机幻觉才是真正的挑战。长上下文(>5K 字符)下 F1 下降 0.09–0.23。7
与现有方法的差异:LLM-as-a-Judge 简单基线在有机 RAG 基准上的竞争力超出过去文献的预期,挑战了「专用检测模型必然优于 Judge」的先验假设。
HalluScan:系统性 72 配置评测框架
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | HalluScan: A Systematic Benchmark for Detecting and Mitigating Hallucinations in Instruction-Following LLMs |
| 场馆/状态 | arXiv 预印本(2605.02443v1,提交至 Neural Computing and Applications) |
| 发表日期 | 2026-05-04 |
| 通讯作者 | Ahmed Cherif(Orange Innovation, Tunisia) |
| 方法类别 | 评估基准构建 |
核心问题:6 种主流幻觉检测方法(自一致性、自评估、语义熵等)在不同模型和领域组合下的真实表现如何?现有独立评测缺乏可控的比较条件。8
方法亮点:笛卡尔积设计——6 种检测方法 × 4 个模型家族 × 3 个领域 = 72 种配置,确保受控比较。三项贡献:HalluScore(与人类判断 Pearson r = 0.41 的综合指标)、ADR(自适应路由算法,2.0x 成本降低,AUROC 仅下降 0.1%)、系统误差级联分解。8
实验结果:8
| 检测方法 | 整体 AUROC(TruthfulQA) |
|---|---|
| NLI Verification | 0.88(最优) |
| RAV(Retrieval-Augmented Verification) | 0.66 |
| Self-Consistency | — |
| LLM-as-Judge | — |
TruthfulQA 平均 0.67,Natural Questions 0.66,ARC-Challenge 0.51——NLI Verification 跨领域泛化能力最强,在困难推理数据集上领先幅度最大。
与现有方法的差异:ADR 路由算法是一个实用的工程贡献——通过置信度路由在检测精度与成本之间取得 Pareto 最优,便于生产环境部署。
Do Benchmarks Underestimate LLM Performance?(ECIR 2026 Workshop)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Do Benchmarks Underestimate LLM Performance? Evaluating Hallucination Detection With LLM-First Human-Adjudicated Assessment |
| 场馆/状态 | ROMCIR Workshop at ECIR 2026(2605.08462v1) |
| 发表日期 | 2026-05-08 |
| 通讯作者 | İsmail Furkan Atasoy |
| 方法类别 | 评估基准构建 |
核心问题:QAGS-C 和 SummEval 两个上下文幻觉检测基准的原始人类标注是否足够可靠?9
方法亮点:由 Gemini 2.5 Flash 和 GPT-5 Mini 先生成 reasoning + span 预测,2 名跨文化 adjudicator 对有争议的样本进行人工仲裁,形成「LLM-First 人工仲裁」流程。9
实验结果:仲裁后三方一致性(triple agreement)提升 6.38%(QAGS-C)和 7.62%(SummEval);GPT 准确率提升 4.25% / 2.34%;Gemini 提升 8.51% / 3.80%;adjudicator 间一致性 83–87%。9
结论:对于歧义性强的任务(如幻觉检测),单次人工标注可能低估模型真实表现;模型辅助重新评估可产生更可靠的基准分数。
MultiWikiQHalluA:306 种语言的多语言幻觉基准(RESOURCEFUL 2026)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | A multilingual hallucination benchmark: MultiWikiQHalluA |
| 场馆/状态 | RESOURCEFUL 2026 Workshop(2605.02504v1) |
| 发表日期 | 2026-05-04 |
| 通讯作者 | Freja Thoresen |
| 方法类别 | 评估基准构建 |
核心问题:幻觉评估长期以英语为中心,低资源语言的情况如何?10
方法亮点:利用 MultiWikiQA 数据集和 LettuceDetect 框架,为 306 种语言创建合成幻觉数据集,训练 30 种欧洲语言的 token 级幻觉分类器,在英语、丹麦语、德语和冰岛语上评估 5 个模型。10
实验结果:Qwen3-0.6B 在冰岛语(低资源语言)上幻觉率高达 60%(至少含一个幻觉的回答比例);cogito-v1-preview-qwen-32B 和 cogito-v1-preview-llama-70B 表现最佳;低资源语言幻觉率在所有模型上一致更高。10
代码库幻觉的静态分析:能力边界的定量刻画
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | An Empirical Analysis of Static Analysis Methods for Detection and Mitigation of Code Library Hallucinations |
| 场馆/状态 | arXiv 预印本(2604.07755v2) |
| 发表日期 | 2026-04-09 |
| 通讯作者 | Clarissa Miranda-Pena(CSIRO, Australia) |
| 方法类别 | 输出校验与后处理(代码领域) |
核心问题:LLM 在需要使用第三方库的代码生成任务上,使用了多少不存在的库函数/类?静态分析工具能检测到多少?11
主要发现:11
- LLM 在 NL-to-code 基准上有 8.1–40% 的响应使用了不存在的库特性(因模型和数据集不同差异较大)
- 静态分析可检测所有类型错误的 16–70%,其中库幻觉的检测比例为 14–85%
- 即使针对理论上可检测的错误类型,静态分析的上限也仅为 48.5–77%,永远无法解决全部问题
结论:静态分析是一种低成本的部分解决方案,对代码质量工具链有实用价值,但对 LLM 幻觉不能形成完整防线。
Principled Detection via Multiple Testing(信息量有限)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Principled Detection of Hallucinations in Large Language Models via Multiple Testing |
| 场馆/状态 | arXiv 预印本(2508.18473v3) |
| 发表日期 | 2026-04-28 |
| 通讯作者 | Jiawei Li(University of Illinois Urbana-Champaign) |
| 方法类别 | 输出校验与后处理 |
核心方法:将幻觉检测形式化为多重假设检验(multiple testing)问题,通过 conformal p-values(保形预测框架下对每个样本给出的统计置信分数,理论上可控制误报率)系统聚合多个评估分数,实现可控误报率(FAR)下的校准检测。与分布外样本检测(OOD detection)建立平行类比。12
实验结果:在多个模型和数据集上进行广泛实验(具体指标因全文 HTML 未抓取而当前不可得)。
方向价值:conformal prediction 框架对于需要统计保证(而非仅追求最优 AUROC)的生产部署场景有独特吸引力;「可控误报率」这一设计目标与 HalluScan 的 ADR 路由思路互补。
四、缓解方法:解码干预
CFB:水印启发的上下文忠实解码(ACL 2026)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Context-Fidelity Boosting: Enhancing Faithful Generation through Watermark-Inspired Decoding |
| 场馆/状态 | ACL 2026(arXiv 2604.22335v1) |
| 发表日期 | 2026-04-24 |
| 通讯作者 | Jian Li(Tencent Hunyuan AI Digital Human) |
| 开源代码 | github.com/weixuzhang/CFB |
| 方法类别 | 推理时解码策略 |
核心问题:摘要和 RAG 场景中,模型生成内容偏向参数记忆而非输入上下文(「参数漂移」),现有对比解码方法(CAD/ADACAD)需要构造对比分布,计算开销高。13
方法亮点:CFB 从文本水印技术的 logit-shaping 原理获取灵感——在解码时对出现在输入上下文中的 token 施加加法 logit 偏置,偏向「上下文支持的 token」而非「参数记忆中的 token」。三种递进策略:13
- Static Boosting:固定偏置强度
- Context-Aware Boosting:基于 Jensen–Shannon 散度自适应缩放偏置
- Token-Aware Boosting:结合注意力位置和语义相似度的 token 级精细重分配
无需重新训练或修改模型架构,直接接入推理管道。
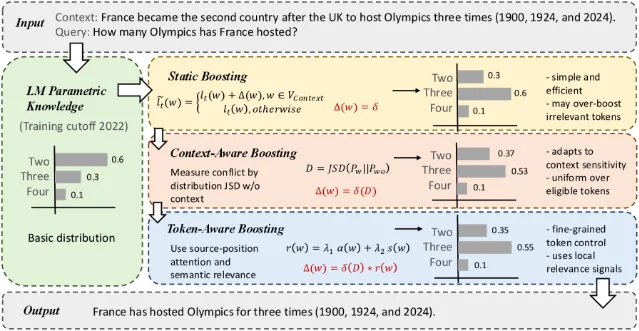
实验结果:13
| 模型 | 基准 | ROUGE-L | FactKB |
|---|---|---|---|
| Mistral-7B | CNN/DM 摘要 | 34.52 | 96.87 |
| Llama2-13B | CNN/DM 摘要 | 37.52 | 98.85 |
| Llama3-8B | CNN/DM 摘要 | 36.79 | 97.23 |
| Llama3-8B | XSum 摘要 | — | 66.85(Context-Aware CFB) |
NQ-Synth QA 上 Token-Aware CFB 准确率:Mistral-7B 60.10、Llama2-13B 64.00、Llama3-8B 73.40。人类评估忠实性得分 4.31(对比:CAD 3.82、ADACAD 4.03)。13
与现有方法的差异:CAD/ADACAD 通过构造「去除上下文」的对比分布来引导生成,CFB 直接操作原分布的 logit 偏置,避免了反向分布构造中引入的噪声。
PCNET:概率电路密度估计 + 动态对比解码
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Hallucination as an Anomaly: Dynamic Intervention via Probabilistic Circuits |
| 场馆/状态 | arXiv 预印本(2605.05953) |
| 发表日期 | 2026-05-07 |
| 通讯作者 | Erik Nielsen 等(University of Trento) |
| 方法类别 | 推理时解码策略(检测 + 动态修正) |
核心问题:现有幻觉修正方法(包括对比解码)对每个 token 不加区分地应用修正,把原本正确的生成也「腐败」掉。14
方法亮点:在 LLM 残差流(residual stream)上训练概率电路(Probabilistic Circuit,PC)作为可处理密度估计器,通过精确负对数似然检测偏离「事实流形」的 token——将幻觉视为几何异常而非分类问题。PC-LDCD(概率电路潜在密度对比解码)仅在检测到异常 token 时触发对比解码修正。14
实验结果:14
- CoQA / SQuAD v2.0 / TriviaQA 上幻觉检测 AUROC 最高达 99%
- TruthfulQA 上 4 个测试模型中 3 个取得最高 True+Info / MC2 / MC3 分数
- 平均「腐败率」(正确 token 被错误修正的比例)降至 53.7%,正确生成保留率 79.3%
因全文 HTML 未抓取,具体 baseline 对比数值当前不完整。
与现有方法的差异:密度估计视角使 PCNET 能够区分「正常事实分布范围内的生成」和「偏离流形的幻觉生成」,条件触发机制避免了全量对比解码对生成流畅性的破坏。
五、缓解方法:视觉语言模型(VLM 方向)
本节三篇论文的研究对象是大型视觉语言模型(LVLM,Large Vision-Language Model),幻觉根因涉及视觉注意力机制,与文本 LLM 幻觉的形成机制有所不同。正交投影(MPD)和注意力干预(HAVAE)等技术原理可部分迁移至文本 LLM 场景。
HAVAE:词汇劫持现象与注意力干预(ACL 2026 Main)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Vocabulary Hijacking in LVLMs: Unveiling Critical Attention Heads by Excluding Inert Tokens to Mitigate Hallucination |
| 场馆/状态 | ACL 2026 Main Conference(arXiv 2605.10622) |
| 发表日期 | 2026-05-11 |
| 通讯作者 | Jing Li(哈尔滨工业大学深圳) |
| 开源代码 | github.com/lab-klc/HAVAE |
| 方法类别 | 推理时(训练无关)注意力干预 |
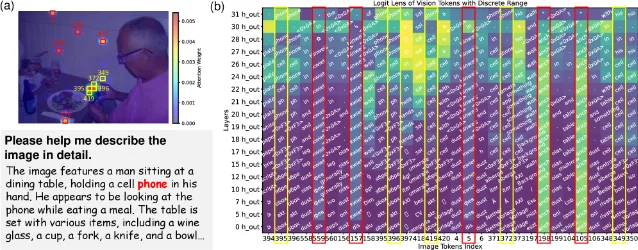
核心问题:LVLM 为何在视觉问答任务中产生幻觉?幻觉根因能否用具体的注意力机制来解释?15
方法亮点:通过 Logit Lens 分析发现「词汇劫持」(Vocabulary Hijacking)现象——特定视觉 token(称为「惰性 token」,inert tokens)不成比例地吸引注意力权重,且其中间隐藏状态投影到词汇空间时始终解码为固定的无关词(「劫持锚点」,如「kwiet」等无意义词,占据注意力但对图像理解无贡献)。基于此提出三个组件:15
- HABI(Hijacking-Anchor-Based Inert-token Identification):可靠定位各类 LVLM 中的惰性 token
- NHAR(Non-Hijacking visual Attention Ratio):衡量关键注意力头对显著视觉内容的关注比例
- HAVAE(Hijacking-Aware Visual Attention Enhancement):选择性增强关键注意力头对显著视觉内容的关注,零额外计算开销,无需训练
实验结果:15
| 模型 | CHAIRs(幻觉率 ↓) | CHAIRi(幻觉率 ↓) | vs 最强基线 CHAIRi |
|---|---|---|---|
| LLaVA-1.5-7B 基线 | 48.2 | 14.2 | — |
| LLaVA-1.5-7B + HAVAE | 18.2 (-62%) | 3.8 (-73%) | ↓38.7% |
| Shikra-7B 基线 | 56.8 | 14.8 | — |
| Shikra-7B + HAVAE | 15.8 (-72%) | 5.0 (-66%) | ↓46.2% |
CHAIR(Caption Hallucination Assessment with Image Relevance)是 LVLM 幻觉评测的主流基准,CHAIRs 衡量含幻觉的句子比例,CHAIRi 衡量含幻觉的对象实例比例,两者均越低越好。通用能力(MME 基准)保持不变或略有提升。
与现有方法的差异:相比 PAI、Devils、VISTA 等基线,HAVAE 不引入额外推理开销;惰性 token 识别机制(HABI)具有跨模型泛化性,理论上可迁移至文本 LLM 的注意力分析。
MPD:正交投影解耦与选择性参数编辑(ACL 2026 Oral)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Mitigating Hallucinations in Large Vision-Language Models without Performance Degradation |
| 场馆/状态 | ACL 2026 Oral(arXiv 2604.20366) |
| 发表日期 | 2026-04-22 |
| 通讯作者 | Junfeng Fang(新加坡国立大学)、Xiangnan He(中国科学技术大学) |
| 方法类别 | 训练时(模型编辑) |
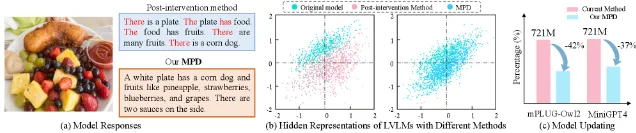
核心问题:现有表示干预方法通常从对比表示中直接差分计算幻觉成分,但幻觉成分与通用语义成分高度耦合——差分法会无意间破坏模型的通用表达能力。16
方法亮点:MPD 双阶段框架——16
- 语义感知成分解耦:通过对比查询对(幻觉诱导问题 vs 语义等价非幻觉问题),用正交投影从隐藏表示中提取纯净幻觉成分,避免幻觉与通用语义的污染
- 选择性参数更新:通过余弦相似度识别与幻觉成分相关性最高的参数(top-K 权重向量),只更新这些参数,大幅减少对原始参数分布的扰动
实验结果:16
| 模型 | CHAIRs 基线 | CHAIRs + MPD | 降幅 |
|---|---|---|---|
| MiniGPT-4 | 32.40 | 19.40 | -40.1% |
| mPLUG-Owl2 | 22.90 | 14.00 | -38.9% |
| LLaVA-1.5-7B | 20.40 | 12.80 | -37.3% |
综合指标:减少幻觉 23.4% 的同时保持 97.4% 通用生成能力(LLaVA-Bench 和 MME 评估),无额外推理成本;参数扰动量比 Nullu(全局权重编辑基线)减少 37–42%。
Video-ToC:树引导视觉线索定位与视频幻觉
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Video-ToC: Video Tree-of-Cue Reasoning |
| 场馆/状态 | arXiv 预印本(2604.20473) |
| 发表日期 | 2026-04-22 |
| 通讯作者 | Wenjie Pei(哈尔滨工业大学深圳) |
| 开源代码 | github.com/qizhongtan/Video-ToC |
| 方法类别 | 训练时(SFT + RL) |
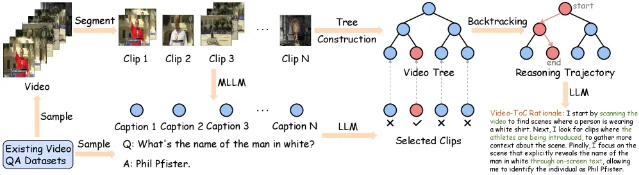
核心问题:Video-R1 等视频推理方法依赖大型模型自由生成的推理模板,较小模型学习时反而产生更多幻觉——为何更强的推理模板会加剧小模型幻觉?17
方法亮点:三项创新——17
- 树引导视觉线索定位:通过树状视频片段结构,从粗到细逐步定位回答问题所需的关键视觉线索(叶节点),强制模型检查视频细节而非依赖语言先验
- 推理需求奖励机制:RL 奖励值与问题的推理复杂度成正比(公式:e^{-α/M}),让 RL 阶段有选择地重点优化高难度问题的推理
- 自动标注流水线:构建 Video-ToC-SFT-1k 和 Video-ToC-RL-2k 两个数据集,训练成本约 6.5 GPU hours(SFT)+ 20 GPU hours(RL,A6000 GPU)
实验结果:64 帧设置下:17
| 方法 | VideoMME | MMVU | VideoHallucer ↑ |
|---|---|---|---|
| Baseline | 59.6 | — | 50.5% |
| Video-R1 | 61.4 | 63.8 | 45.4%(比基线更差) |
| Video-ToC | 62.6 | 66.5 | 51.9% |
Video-R1 在 VideoHallucer 幻觉基准上的分数低于无结构化推理的基线,验证了「自由生成推理模板不适合小模型」的假设。MMVU 是多学科视频理解基准,VideoHallucer 专门评测视频幻觉,得分越高说明幻觉越少。
六、视角与应用:元认知、实时修正与医疗部署
元认知作为第三条路径(ICML 2026 Position Track)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Hallucinations Undermine Trust; Metacognition is a Way Forward |
| 场馆/状态 | ICML 2026 Position Track(arXiv 2605.01428) |
| 发表日期 | 2026-05-02 |
| 通讯作者 | Gal Yona(Google)、Mor Geva(Tel Aviv University)、Yossi Matias(Google) |
| 方法类别 | 立场论文 / 理论框架 |
这篇 ICML Position Track 论文的核心论点需要完整说明,因为它对整个领域的方法选择有框架性意义。18
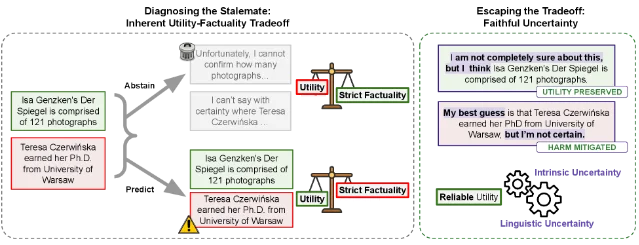
核心论点:完全消除幻觉面临根本性的「歧视差距」(discrimination gap)——模型可能在内部状态上就无法完美区分已知与未知。Yona 等人将幻觉重新定义为「自信的错误」(confident errors)而非任何错误,并据此提出第三条路径:忠实不确定性(faithful uncertainty)——即语言层面的不确定性表达与模型内部状态的对齐。
"If we understand hallucinations not as any error, but as confident errors—incorrect information delivered without appropriate qualification—a third path emerges: expressing uncertainty."「如果我们把幻觉理解的不是任何错误,而是自信的错误——在没有适当限定语的情况下传递错误信息——那么第三条路径就浮现了:表达不确定性。」18
关键数据:当前 LLM 在知识密集型任务上的 AUROC 仅 0.70–0.85。18
| AUROC 水平 | 将错误率降至 5% 需丢弃的有效回答比例 |
|---|---|
| 0.71 | 52% |
| 0.85 | 28% |
| ≥0.95 | <5%(效用损失可接受) |
即在 AUROC = 0.71 的水平下,把幻觉率压低到 5%,需要拒绝回答超过一半的有效问题——效用代价极高。
对研究方向的意义:当前大多数事实性改进来自扩展模型的知识覆盖(编码更多事实),而非改进模型对自身知识边界的感知(区分已知与未知)。元认知在智能体系统中还充当工具调用的控制层——模型需要知道何时检索、何时信任检索结果。
实时语音幻觉修正:竞速架构(工业实践)
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Real-Time Hallucination Correction at Zero Latency Cost |
| 发表方 | Giga AI(工程博客,非同行评审) |
| 发表日期 | 2026-05-07 |
| 作者 | Esha Dinne、Rishi Alluri、Arnab Maiti(Giga AI) |
| 方法类别 | 输出校验与后处理(实时检测 + 修正) |
系统设计核心:利用 LLM 文本生成速度(约 1 秒完成 30 词响应)远快于 TTS 语音播放速度(10–12 秒)的时间差,在语音流式播放的同时并行运行推理模型检测器。19
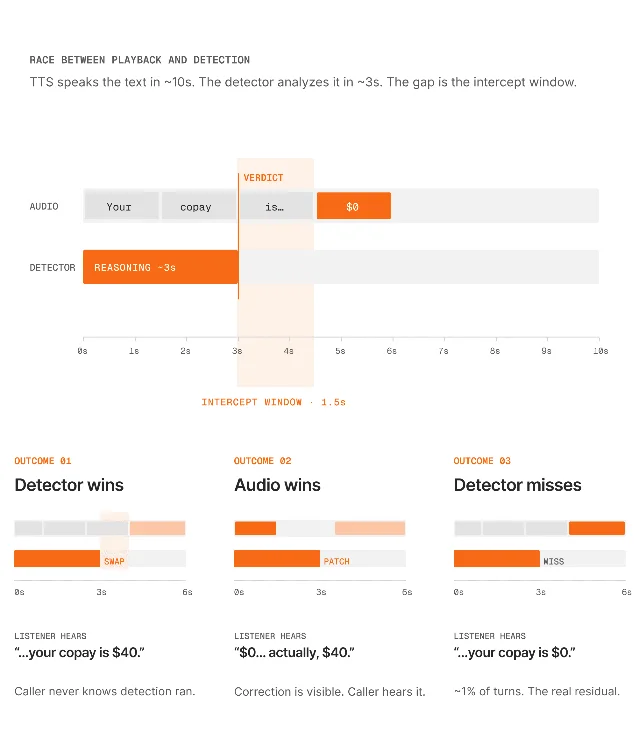
生产数据:120 万轮对话统计——19
- 幻觉率从 4–5% 降至 <1%,零延迟增加
- 误报率 <0.3%
- 96% 轮次:无幻觉,检测系统不触发
- 3–4% 轮次:检测到并修正(其中「拦截成功」vs「显式修正」的比例未披露)
- 约 1% 轮次:被检测器漏过
关键工程发现:修正提示必须为临时性(用完即删),否则模型会出现持续模糊化(hedging)——模糊化率翻倍至基线的 2 倍。检测器使用推理模型而非分类器,因为「指令矛盾」类幻觉(模型说可以处理退款,但指令说不能)需要语义推理能力,分类器无法捕获。19
说明:本条为工业博客,未经同行评审,生产数据口径和评估方法由 Giga AI 内部定义,请读者结合应用场景判断参考价值。
ClinIQLink:医学教科书接地幻觉基准
论文信息
核心设计:ClinIQLink 流水线从公共领域医学教科书提取段落,生成 7 种 QA 格式(含「反向提示」inverse 变体作为压力测试),经医学专家验证,最终产出 5,543 个 QA 对。20
实验结果:20
- LLaMA-70B-Instruct 在提供原段落的情况下,仍有 19.7%(95% CI 18.6–20.7)的回答属于幻觉
- 98.8% 的幻觉回答获得最高流畅性评分(5 分制),说明「流畅 ≠ 准确」
- 幻觉率与临床有用性负相关(ρ = -0.71,p = 0.058)
- 幻觉率随模型规模单调下降:1B 模型 27.1% → 70B 模型 9.3%,但所有规模模型均产生幻觉
- 反向提示比正向多引发 6–9% 幻觉
关键结论:跨 8 个模型的评估(Phi-4、LLaMA 3.3 70B、Qwen 3 32B 等)确认所有测试模型均不适合无监督临床部署。验证(而非生成)是实际成本的主导因素——每位标注者每条判断平均耗时 2.05 分钟。20
七、本月研究趋势与空白方向
三条活跃趋势
趋势一:token 级检测方向在向更小、更专用的检测器演进
TokenHD 展示了 0.6B 专用检测器超越 32B 通用推理模型的可能性;PCNET 通过密度估计在 token 粒度上实现了 99% AUROC。「小而专用」的检测器在延迟和成本方面比「大而通用」有系统性优势,预计这一方向在量化 / 端侧部署场景会有更多跟进工作。
趋势二:VLM 幻觉的注意力机制解释 + 训练无关干预
HAVAE(ACL 2026 Main)和 MPD(ACL 2026 Oral)均以可解释的机制分析作为出发点——「词汇劫持」和「幻觉成分与通用语义耦合」——再设计有针对性的干预。与早期「有效但不知道为何有效」的调参式方法相比,这类基于机制分析的方法在推广到新模型时有更清晰的迁移路径。
趋势三:评估框架从注入幻觉转向有机幻觉
Rethinking Evaluation(ACL 2026 Main)和 HalluScan 共同指出:注入式幻觉基准(如 HaluEval)的检测难度极低(SFT F1 可达 0.996),与实际场景严重脱节;有机 RAG 场景下当前没有检测器能超过 F1 = 0.7。Trivia++ 的 94K 最长上下文设计和 4 套噪声标签,是目前最接近生产环境的评估基准。
三处研究空白
空白一:30 种欧洲语言以外的多语言幻觉检测
MultiWikiQHalluA 覆盖了 306 种语言的数据构建,但训练的 token 级分类器只到 30 种欧洲语言。亚洲语言(中文、日文、阿拉伯语、泰语等)和非洲语言的幻觉特征与评估方法几乎是空白——低资源语言的幻觉率一致更高,说明该方向既有科学意义也有现实紧迫性。
空白二:代码幻觉的语义级检测
静态分析工具的检测上限是 48.5–77%,剩余的幻觉属于语义层面的错误(存在的 API,但使用方式不正确;函数签名正确,但参数含义错误)。这类错误静态分析天然无法捕获,需要运行时语义分析或专用的代码幻觉检测模型——目前该细分方向几乎无顶会论文。
空白三:元认知能力的可训练性
Metacognition(ICML 2026)这篇立场论文的核心主张——LLM 应能可靠地表达忠实不确定性——目前缺乏系统性的训练方法论支撑。「如何在 SFT / RLHF 过程中让模型学会对不确定的内容降低置信度表达」是一个相对开放的研究问题,现有 calibration 方法(temperature scaling 等)大多是推理时后处理,不涉及训练层面的元认知能力习得。
封面图由 AI 生成
参考来源
- 1Scalable Token-Level Hallucination Detection in Large Language Models
- 2Logical Consistency as a Bridge
- 3Sanity Checks for Long-Form Hallucination Detection
- 4Low-Cost Black-Box Detection of LLM Hallucinations via Dynamical System Prediction
- 5FaithLens: Detecting and Explaining Faithfulness Hallucination
- 6GSAR: Typed Grounding for Hallucination Detection and Recovery in Multi-Agent LLMs
- 7Rethinking Evaluation for LLM Hallucination Detection
- 8HalluScan: A Systematic Benchmark
- 9Do Benchmarks Underestimate LLM Performance?
- 10A multilingual hallucination benchmark: MultiWikiQHalluA
- 11An Empirical Analysis of Static Analysis Methods for Detection and Mitigation of Code Library Hallucinations
- 12Principled Detection of Hallucinations in Large Language Models via Multiple Testing
- 13Context-Fidelity Boosting: Enhancing Faithful Generation through Watermark-Inspired Decoding
- 14Hallucination as an Anomaly: Dynamic Intervention via Probabilistic Circuits
- 15Vocabulary Hijacking in LVLMs
- 16Mitigating Hallucinations in Large Vision-Language Models without Performance Degradation
- 17Video-ToC: Video Tree-of-Cue Reasoning
- 18Hallucinations Undermine Trust; Metacognition is a Way Forward
- 19Real-Time Hallucination Correction at Zero Latency Cost
- 20Quantifying Hallucinations in Large Language Models on Medical Textbooks
围绕这条内容继续补充观点或上下文。