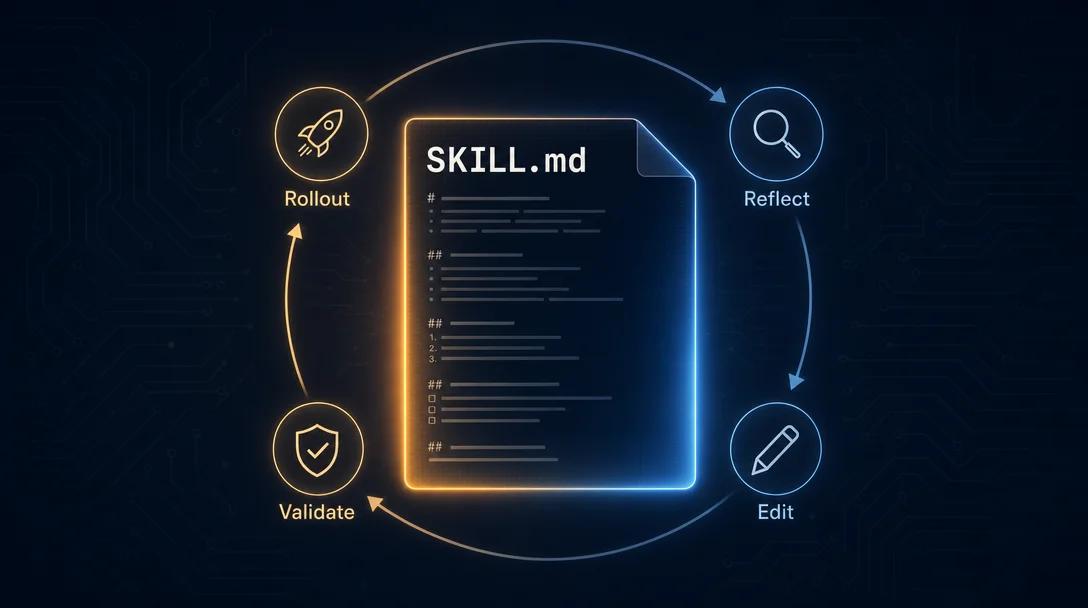
Your SKILL.md is a trainable parameter
Microsoft Research's SkillOpt (arXiv:2605.23904) treats the SKILL.md instruction file as a trainable external state for a frozen model — running a validation-gated rollout → reflect → edit → validate loop that lifted GPT-5.5 average accuracy by +23.5 points across six benchmarks with zero model weight changes. Gains transfer cross-model and cross-harness, so a skill optimized today survives your next model upgrade. Three PM actions: version skill files in git, build a verifiable benchmark from production logs, and run an optimization pass before the next model migration.

You've tuned the system prompt. You've swapped models. You've added more tools. The agent still stalls on the same class of tasks it stalled on three months ago.
The problem is where you're looking. Model weights are frozen. System prompts stay flat. But the thing that actually governs how an agent executes — the skill file, the
SKILL.md or AGENTS.md that tells the agent how to do its job — has been treated as a manual artifact: someone writes it once, edits it occasionally, and hopes it holds up.Microsoft Research published a paper on May 22 that treats this as an engineering failure. 1 The paper is called SkillOpt. The argument is simple: if a skill file is what governs agent behavior, it should be optimized the same way neural networks are trained — with data, gradients, validation gates, and checkpoints. The gains aren't marginal. On GPT-5.5 running across six benchmarks, SkillOpt lifted average accuracy from 58.8 to 82.3 — a +23.5-point jump — without touching a single model weight. 1
The training loop, translated
SkillOpt's core loop has five steps that map directly to neural network training — the authors call the analogy "operational rather than decorative." 2
- Rollout (forward pass): A frozen target model runs a batch of tasks using the current skill file. Pass/fail outcomes are recorded.
- Reflect (backward pass): A separate optimizer model — GPT-5.5 by default, only used during training — analyzes a minibatch of successes and failures to propose edits.
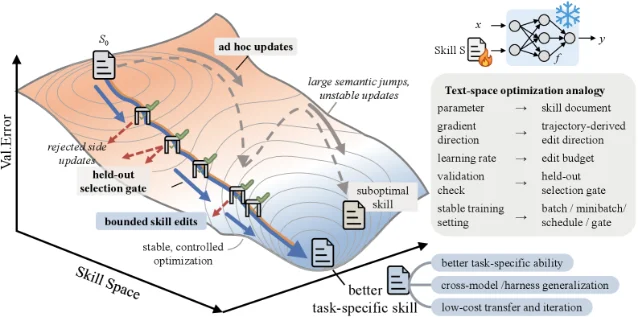
- Edit (bounded weight update): Up to four
add/delete/replaceoperations are applied per step. The ceiling prevents skill drift — the authors call this a "textual learning rate." - Validate (held-out gate): Proposed edits run against a held-out task split. The new skill is accepted only if it strictly improves on that split. Ties are rejected.
- Deploy: The final
best_skill.mdis typically 300–2,000 tokens — a compact, auditable text file that slips into any agent's context window with zero inference-time overhead. 2
The ablation results tell you which parts actually matter. Removing the rejected-edit buffer — which stores previously rejected proposals so the optimizer doesn't retry them — costs 4.6 points on SpreadsheetBench. Removing both the epoch-level slow update and the meta-skill synthesis drops SpreadsheetBench by 22.5 points, the largest single-component loss in the study. 2 The slow update protects "slow-state" content — reasoning patterns, domain guidelines, voice constraints — from being overwritten by step-level edits. If your skill files carry non-negotiable organizational standards, that's the mechanism guarding them.
What the numbers actually say
The headline gain (+23.5 points on GPT-5.5 direct chat) spans six genuinely different benchmarks: SearchQA, SpreadsheetBench, OfficeQA, DocVQA, LiveMathematicianBench, and ALFWorld. 1 The two largest single-benchmark lifts were in task-execution domains — SpreadsheetBench went from 41.8 to 80.7 (+38.9 points), OfficeQA from 33.1 to 72.1 (+39.0 points). 2
正在加载图表…
The portability result is the part with the clearest product implication. A skill trained on GPT-5.4 transferred positively to GPT-5.4-mini (+9.4 points) and GPT-5.4-nano (+3.0 points). A skill trained on Codex transferred to Claude Code with a +59.7-point lift (22.1 → 81.8) — slightly above the in-domain Claude Code optimized result. 2 The authors note that every transfer row in their table was positive: "no row falls below the target's no-skill baseline." This means a skill you optimize for your current model doesn't get discarded when you upgrade — it typically carries forward.
The cost to run an optimization pass is also in the paper, implemented via gBrain's
gbrain skillopt command: $0.71 for a 20-task benchmark, $5.00 for 100 tasks (using GPT-5.5 as optimizer). 3 A single optimization run on a 20-task benchmark costs less than a cup of coffee.Why May 2026 specifically
SkillOpt isn't an isolated paper. Five independent research teams published aligned conclusions in a 16-day window this past May:
- Life-Harness (Peking University, arXiv:2605.22166, May 21): optimizes the runtime harness interface rather than the skill document — a complementary lever. 116 of 126 model-environment settings improved, average relative gain of 88.5%. 4
- CODESKILL (arXiv:2605.25430, May 25): uses reinforcement learning to extract skills from coding agent trajectories and maintain a skill bank without unbounded growth. +9.69 average pass rate on SWE-Bench Verified and Terminal-Bench 2. 5
- MUSE-Autoskill (arXiv:2605.27366, May 26): proposes a five-stage skill lifecycle — creation, memory, management, evaluation, refinement — treating skills as "long-lived, experience-aware, and testable assets." 6
- EvoMap (arXiv:2605.25815, May 25): an empirical audit of one A2A collaboration network found that 98% of contributed assets were never reused, 84% of approved assets used empty tests, and the reputation scoring system was trivially gameable. 7 It's a concrete warning about what skill-sharing infrastructure looks like when quality control is absent.
Garry Tan, Y Combinator's CEO, shipped a working
gbrain skillopt implementation the same week and called the integration "trivial":正在加载内容卡片…
The SkillOpt paper's first author, Yifan Yang at Microsoft Research, confirmed on May 31 that gBrain's integration reflected exactly the use case the team hoped for. 8 NVIDIA and ServiceNow announced Project Arc at Knowledge 2026 (May 5, Las Vegas) — billed as a "long-running, self-evolving desktop AI agent" — backed by NVIDIA OpenShell for sandboxed execution and ServiceNow AI Control Tower for governance and audit trails. 9 The enterprise framing differs from SkillOpt's research approach, but both converge on the same structural bet: agent capability improvement happens at the skill layer, not the model layer.
Three things a PM should do now
1. Treat your SKILL.md as a versioned artifact with a changelog.
If you're running agents with Claude Code, Codex, or any custom harness, your skill files are currently unversioned text. That means you can't measure whether a change improved performance, roll back a regression, or compare skill versions across deployments. Commit skill files to git, record eval results against each commit, and assign someone ownership of the optimization loop. The mager.co analysis put the median final skill file at around 920 tokens — small enough that skill diffs are human-readable and reviewable. 10
2. Build your benchmark before you run any optimization.
This is where most skill optimization loops die. Rohan (@proxy_vector), commenting on the gBrain integration thread, identified the underlying pattern: "Most prompt or skill optimization loops die because eval setup is the part nobody keeps current." 11 SkillOpt itself only works on verifiable tasks — ones where pass/fail can be checked programmatically. 12 Before running SkillOpt, your team needs 20–100 representative task examples with ground-truth outcomes. If your agent handles structured outputs (form parsing, code generation, data extraction, routing decisions), you can build this benchmark from production logs in a day. If your agent handles open-ended generation, you need a rubric or LLM judge first — the paper's authors acknowledged this extension is in progress.
3. Run an optimization pass before your next model upgrade, not after.
When your infrastructure team migrates from GPT-5.4 to GPT-5.5, the standard workflow is: upgrade model, observe regressions, patch prompts. The portability results from SkillOpt suggest a better sequence: optimize your skill against the current model, then transfer it to the upgraded model. Every cross-model transfer in the study was positive — the worst case was a +3.0-point gain on the smaller model. You carry the skill forward rather than starting from scratch, and you have a pre-upgrade baseline to compare against. The gBrain implementation supports
--bootstrap-from-skill, which auto-generates a benchmark from your existing SKILL.md — so you can start even if you haven't built a benchmark yet. 3One realistic constraint: skill optimization works today on tasks where success is measurable. If your agent's primary output is persuasive writing, nuanced customer support responses, or creative tasks, you'll need a scoring rubric or LLM judge before SkillOpt becomes applicable. The research direction for that extension — rubrics-based and reward-model-guided optimization — is underway but not yet shipped. 12 The tools that exist now (SkillOpt, gBrain, CodexOpt) are productive immediately for any team running structured, verifiable agent tasks — which covers most production agent deployments in 2026.
Cover image: AI-generated illustration
参考来源
- 1SkillOpt: Executive Strategy for Self-Evolving Agent Skills (arXiv)
- 2SkillOpt Full HTML (arXiv:2605.23904v1)
- 3gBrain SkillOpt guide (GitHub)
- 4Life-Harness (arXiv:2605.22166)
- 5CODESKILL (arXiv:2605.25430)
- 6MUSE-Autoskill (arXiv:2605.27366)
- 7EvoMap (arXiv:2605.25815)
- 8Yifan Yang (@Yif_Yang) on gBrain integration
- 9NVIDIA Blog: Project Arc announcement
- 10mager.co: SkillOpt analysis
- 11Rohan (@proxy_vector) on eval setup
- 12Yifan Yang on unverifiable tasks
围绕这条内容继续补充观点或上下文。