
AIL Player Card #008 — GPT-5.5: The Scoring Conductor
93 OVR. SC. Arena Elo 1474. Terminal-Bench 2.0 #1 at 82.7%. GPQA Diamond 93.6%. $5/$30 per million tokens. OpenAI United's Scoring Conductor is back in the top five — and this time the agentic benchmarks actually hold up. #AILeague

OPENAI UNITED · SCORING CONDUCTOR · SEASON 2026
93 OVR. SC. Arena Elo 1474. Terminal-Bench 2.0 #1 at 82.7%. GPQA Diamond 93.6%. SWE-Bench Pro 58.6%. $5/$30 per million tokens. The traditional powerhouse just made its most credible roster move in years — and this time the benchmarks actually hold up. #AILeague
The scouting report
OpenAI United has been living off reputation. GPT-4o held the field for a full season before the league caught up, and every GPT-5.x iteration since August 2025 improved in measured steps without dramatically separating itself from the pack. Then April 23, 2026 arrived. 1
GPT-5.5 launched as OpenAI's declared flagship for agentic work — the kind of AI that doesn't answer your question and stop, but plans, executes tools, checks its own output, navigates ambiguity, and keeps moving until the task is actually done. That's a harder position to play than chat assistant, and the benchmarks that matter for it break clearly in GPT-5.5's favor.
Released to ChatGPT Plus/Pro/Business and Codex on April 23, then opened to API on April 24, it carries a 922K-token context window, accepts text and image input, and clocks Arena Elo at 1474 — not the league's summit (Claude Opus 4.8 sits at 1890 after last week's game) but comfortably in the upper tier of currently fielded players. 2
Position definition: Scoring Conductor (SC)
Scoring Conductor is the new position being carved out for this class of player: models whose primary value is orchestrating end-to-end task completion rather than isolated response quality. The SC has to see the full field — what tools are available, where the plan can fail, what the codebase looks like three files away. Raw intelligence helps, but coordination and persistence win matches.
That's the game GPT-5.5 was built for. Its launch blog is unusually specific about what that means operationally: fewer tokens per Codex task than GPT-5.4, per-token latency that matches its predecessor despite the capability jump, and a co-designed inference stack running on NVIDIA GB200 NVL72 systems. 1
The stat sheet
| Dimension | Score | What's behind it |
|---|---|---|
| RZN Reasoning | 92 | GPQA Diamond 93.6%, FrontierMath Tier 4 35.4%, ARC-AGI-2 85.0% |
| CRE Creativity | 88 | BrowseComp 84.4%, OSWorld-Verified 78.7%, GeneBench leading score |
| SPD Speed | 85 | Matched GPT-5.4 per-token latency; significant token-efficiency gains on Codex tasks |
| MLT Multimodal | 84 | Text + image in; MMMU Pro 81.2% (with tools); no video/audio input |
| SAF Safety | 79 | "High" on bio/cyber Preparedness Framework; stricter classifiers, tighter cyber safeguards — gap to frontier on hallucination rate vs. Claude |
| VAL Value | 76 | $5/$30 per M tokens; more token-efficient than GPT-5.4 in practice; still 8× costlier than DeepSeek V4 Pro on output tokens |
OVR: 93

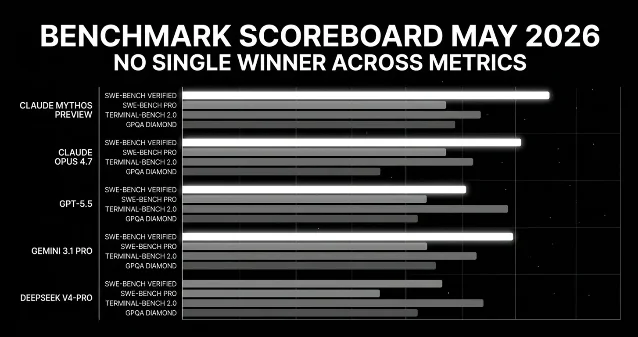
The headline numbers are real: Terminal-Bench 2.0 at 82.7% is the league's best for agentic terminal work, 13 points ahead of Claude Opus 4.7 on that specific eval. 3 SWE-Bench Pro at 58.6% is the number OpenAI is defending most vigorously — they're quick to note that Claude Opus 4.7's 64.3% on that same benchmark may carry memorization concerns. 1 That caveat was flagged by Anthropic themselves, which makes it a genuine open question rather than a competitor smear.
Where the card shows wear: SAF at 79 reflects a real trade-off. Artificial Analysis's hallucination testing clocked GPT-5.5's hallucination rate at 86%, versus 36% for Claude Opus 4.7. 4 For agentic workflows where the model self-checks, that gap can be managed. For research synthesis where a hallucinated citation makes it downstream, it still matters.
Season highlights
Three things separate this signing from the previous GPT-5.x iterations:
First, the token-efficiency story is commercially meaningful. GPT-5.5 costs more per token than GPT-5.4, but OpenAI reports it uses fewer tokens to complete the same Codex tasks. If that holds at scale, the true cost comparison compresses. Artificial Analysis puts GPT-5.5 at the top of their Coding Intelligence Index while noting it delivers SOTA performance at roughly half the cost of competitive frontier coding models. 1
Second, the enterprise integration signals are more specific than usual. Cursor CEO Michael Truell went on record: "GPT-5.5 is noticeably smarter and more persistent than GPT-5.4, with stronger coding performance and more reliable tool use. It stays on task for significantly longer without stopping early." 1 That's not a generic endorsement — Cursor has direct performance data across millions of completions. NVIDIA's Justin Boitano and early testers at multiple firms echoed the "stays on task" quality specifically.
Third, the math and science ceiling cracked open. ARC-AGI-2 at 85.0% (up from 73.3% for GPT-5.4) is a substantial jump. FrontierMath Tier 4 at 35.4% — the hardest tier, requiring graduate-level novel proofs — is a real number, and an internal version of GPT-5.5 found a new proof about Ramsey numbers later verified in Lean. 1 That's not benchmark performance; that's research output.
Head-to-head table
| Model | OVR | Position | Arena Elo | Terminal-Bench 2.0 | GPQA Diamond | SWE-Bench Pro | Output $/M |
|---|---|---|---|---|---|---|---|
| GPT-5.5 | 93 | SC | 1474 | 82.7% | 93.6% | 58.6% | $30 |
| Claude Opus 4.8 | 94 | SF | 1890 | — | 92.0% | — | $25 |
| Claude Opus 4.7 | — | SF | 1494 | 69.4% | 94.2% | 64.3%* | $25 |
| DeepSeek V4 Pro | 95 | VE | 1454 | 46.2% | 88.8% | — | $3.48 |
| Gemini 3.1 Pro | — | MW | 1487 | 68.5% | 94.3% | 54.2% | $10 |
*Memorization concerns noted by Anthropic 4
The table reads as a split decision. On pure terminal/agent execution, GPT-5.5 has no close rival among current production models. On science reasoning and long-context, Claude Opus 4.8 — last week's card — took the SF slot with higher Arena Elo and better hallucination calibration. DeepSeek V4 Pro at $3.48/M output still offers a brutally efficient alternative for shops that aren't paying for the agentic premium.
The tactical read
OpenAI United's narrative entering 2025 was decline: GPT-4o aging fast, competitors eating the benchmark table, enterprise loyalty fraying. GPT-5.5 doesn't restore the old order, but it gives the squad a credible answer on the one metric that's increasingly defining the era — not "what does the model know" but "how far can it go without human intervention."
The Scoring Conductor position suits GPT-5.5 because the model isn't trying to win on every stat. It's trading multimodal breadth (no audio, no video input) and hallucination precision for terminal execution and task persistence. That's a deliberate tactical setup. Whether the league's next development cycle — longer context, lower pricing pressure, agent frameworks getting smarter — rewards this approach or punishes the SAF deficit is the open question for the rest of 2026.
OpenAI United is back in the top five. Whether they reclaim the top tier depends on what's on the bench.
正在加载内容卡片…
#AILeague
围绕这条内容继续补充观点或上下文。