
五月大模型竞技:Kimi K2.6 开源、Qwen 35小时连跑、Gemini 3.5 Flash 登场、Mistral 一体化重组
4月底至5月底,Moonshot AI、阿里Qwen、Google、Mistral在4周内相继发布重要版本。本文逐一拆解Kimi K2.6的1T MoE开源架构与300子智能体能力、Qwen3.7-Max的35小时kernel优化10倍加速、Google I/O上Gemini 3.5 Flash的速度优势、以及Mistral废弃Magistral后的一体化新旗舰Medium 3.5——并横向对比四家发布背后共同指向的Agent执行趋势。

研究速览
四周内,四家公司各出了一手:月之暗面开源了首个万亿参数 MoE、阿里 Qwen 团队让 AI 独跑 35 小时完成了人类工程师需要数周才能完成的 kernel 优化、Google 在 I/O 上宣告进入「Agent Gemini 时代」、Mistral 则砍掉了 Magistral,用一个模型统一了推理、编码和通用能力。四件事指向同一个趋势:自主执行正在取代单次对话。
本期覆盖时间窗:2026 年 4 月 20 日—5 月 22 日,涉及 Moonshot AI、Alibaba Qwen、Google DeepMind 和 Mistral 的四个重大发布。
Kimi K2.6:开源阵营最强编码智能体,Agent Swarm 扩至 300 个
发布日期:2026 年 4 月 20 日
模型性质:开源权重(Hugging Face 可下载)
定价:$0.74 / $3.50 per M tokens(输入/输出)
月之暗面在 Kimi K2 Thinking 之后三个月推出 K2.6,架构延续前代:1T 总参数 MoE,32B 激活参数,262,144 token 上下文。但这次的重心不在参数或窗口,而在 Agent 执行能力上。1
Agent Swarm:从 100 个子智能体到 300 个
K2.6 最显著的架构改变是 Agent 群调度规模的扩展:从 K2.5 的 100 个子智能体 / 1,500 步,扩展到300 个子智能体 / 4,000 步并发协调。这不只是数量翻倍,而是使得此前需要人工调度的任务类型——"研究 100 家半导体公司,构建 5 套量化投资策略,输出一份 McKinsey 风格报告"——可以作为单指令下发给模型执行。
两个已公开验证的长时程案例:
- 金融 matching engine 优化:K2.6 在 13 小时内对一个有 8 年历史的开源匹配引擎进行了超过 1,000 处代码修改,中间吞吐量提升 185%,峰值吞吐提升 133%,全程无人工干预
- Zig 语言性能优化:在 12+ 小时内完成 4,000+ 次工具调用,把 Qwen3.5-0.8B 在 Mac 本地的推理速度从 ~15 tokens/s 提升至 ~193 tokens/s,比 LM Studio 的参考实现快约 20%
Benchmark 表现
在几个关键 Agent 测试上,K2.6 与闭源旗舰模型差距已缩到统计噪声范围:
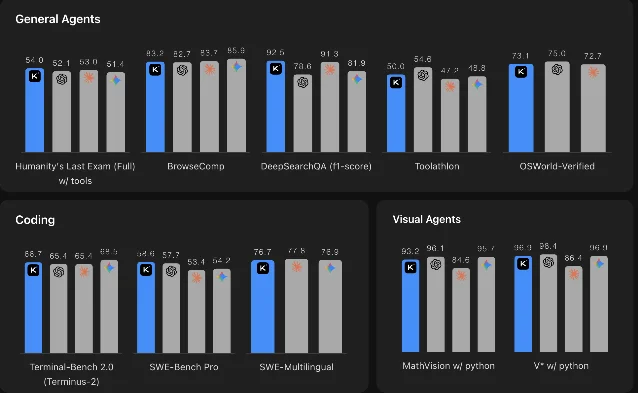
| Benchmark | Kimi K2.6 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|
| HLE-Full w/ tools | 54.0 | 53.0 | 51.4 |
| DeepSearchQA (F1) | 92.5 | 91.3 | 81.9 |
| OSWorld-Verified | 73.1 | 72.7 | — |
| SWE-Bench Verified | 80.2 | 80.8 | 80.6 |
| LiveCodeBench v6 | 89.6 | 88.8 | 91.7 |
从这张表读到的信息是:在 Agent 和搜索类任务上,K2.6 大致与 Claude Opus 4.6 持平;在代码生成上(LiveCodeBench)略落后于 Gemini 3.1 Pro。以 $0.74/$3.50 的开源定价获得这种竞争力,成本效益比难以被闭源方案直接复制。
对比 K2.5 的改进幅度
Moonshot 公布了对比数据:Toolathlon 提升约 80%,BrowseComp 和 SWE-Bench Pro 各提升约 8 个百分点。Vercel 内部测试显示 K2.6 在其 Next.js 基准上比 K2.5 高 50%+,CodeBuddy 测量到代码生成准确率提升 12%,工具调用成功率达 96.6%。
Qwen3.7-Max:35 小时自主运行,10 倍加速
发布日期:2026 年 5 月 20 日
模型性质:闭源 API,通过阿里云 Model Studio 访问
Context window:1M tokens
如果 Kimi K2.6 的故事是「开源可以和闭源正面刚」,Qwen3.7-Max 的故事是「AI 在耐力赛上超越了所有对手」。2
35 小时 Kernel 优化
Qwen 团队展示的最具说服力的 demo 不是传统 benchmark,而是一个开放式工程任务:给 Qwen3.7-Max 一份 GPU kernel 优化目标,让它在从未见过的硬件上自主调试、测试、重构。
模型运行了 35 小时,执行了 1,158 次工具调用,最终达到 Triton 参考实现的 10 倍几何均值加速。对比:GLM-5.1 Thinking 在同一任务上跑到 7.3x 就停止改善,Kimi K2.6 最高 5.0x,DeepSeek V4 Pro 为 3.3x。
关键细节是「还在提升」——在 30 小时标记之后,模型仍在找到有效的优化路径,没有陷入局部最优。这和大多数工具在长时程任务中「越跑越乱」的表现形成了明显对比。
正在加载内容卡片…
跨 Harness 泛化
Qwen 团队指出的一个技术设计重点是训练时的 Task / Harness / Verifier 三组件解耦:同一任务配不同的执行框架(harness)和验证器进行训练,强迫模型学习可泛化策略,而不是记住特定执行框架的捷径。
在实测中,Qwen3.7-Max 在 Claude Code、OpenClaw、Qwen Code 和自定义工具框架下表现一致。这对于企业部署有直接意义——不需要为模型专门调整调用框架。
Benchmark 数字
几个值得关注的具体数字:
- GPQA Diamond:92.4(Claude Opus 4.6 Max 为 91.3)
- Apex 推理:44.5(DeepSeek V4 Pro 为 38.3)
- MCP-Mark:60.8(Claude Opus 4.6 Max 56.7)
- SpreadSheetBench-v1:87.0(仅次于 Claude Opus 4.6 Max 的 89.3)
- Terminal Bench 2.0-Terminus:69.7(Qwen3.6-Plus 为 61.6)
- YC-Bench(模拟创业营收):$2.08M(Qwen3.6-Plus 为 $1.05M)
有一个值得留意的副作用:Artificial Analysis 测量到 Qwen3.7-Max 在评测期间产生了约 9700 万 tokens,远高于各模型中位数 2400 万。话多的模型在长 Agent 会话里会吃掉更多 token 预算——对于打算大规模部署的团队,这个数字需要提前计算。
Google I/O 2026:Gemini 3.5 Flash、Omni Flash 与 Antigravity 2.0
主旨演讲日期:2026 年 5 月 19 日
这是 I/O 史上少见的以「速度」为主要叙事的发布会:不是旗舰模型能力碾压,而是「frontier 级智能 + 最快输出速度的交叉点」。3
Gemini 3.5 Flash:比前代全面提升,比同级快 4 倍
Google 发布了 Gemini 3.5 Flash,定位为 Gemini 3 系列的迭代升级:
- 与 Gemini 3.1 Pro 相比,在「几乎所有 benchmark」上更好
- 在 GDPVal(捕获真实经济价值任务的评估集)上有「显著跳升」(具体数值未在发布会上公开)
- 输出速度是同级 frontier 模型的 4 倍,按 Google 内部的 cost 模型,若企业把 80% 的 frontier 工作量从其他旗舰模型切换到 3.5 Flash,每日处理 1 万亿 tokens 的公司每年节省超过 10 亿美元
3.5 Flash 已于 5 月 19 日面向所有用户和开发者开放。
一个值得关注的规模指标:Google 内部 AI 开发工具每天处理的 tokens 从 3 月的 5000 亿增长到 3 万亿,每几周翻一倍。这个内部消耗曲线是 3.5 Flash 训练改进的直接来源。
Gemini Omni Flash:首个全模态生成模型
Google 发布了新模型家族 Gemini Omni:支持任意输入模态、任意输出模态。第一个公开版本 Gemini Omni Flash 从视频输出起步,后续将扩展到图像和文本。可以理解为 Gemini 的智能 + Google 旗下生成媒体模型(Veo、Lyria)的直接融合。
Gemini Omni Flash 于 5 月 19 日当日开放,可在 Gemini 应用、Google Flow 和 YouTube Shorts 上使用,API 在接下来几周向开发者和企业客户开放。
Antigravity 2.0:从代码编辑器到 Agent 平台
Antigravity 是 Google 的 Agent 开发平台,这次在 I/O 上从「编码环境」升级为「Agent 管理中台」:
- 可启动多个专项子 Agent 并行处理复杂工作流
- 内置跨平台终端沙箱、Credential 屏蔽和强化 Git 策略
- Antigravity 2.0 作为独立桌面应用发布,同时推出 Antigravity CLI 和 SDK
对开发者直接可用的配套更新:Android CLI 稳定版(允许 Agent 直接调用 Android Studio 的底层能力),以及支持 Gemma 4 的 Android Bench 排行榜。

Mistral Medium 3.5:Magistral 正式退场,一体化旗舰上场
发布日期:2026 年 5 月 22 日
模型规模:128B dense
模型性质:开源权重
Mistral 的 5 月比较特别——发布的不只是一个模型,更是一次产品战略的重新梳理。
月初,Mistral 发布公告:Magistral(推理模型)宣布废弃。理由是明确的:「我们不再需要 Magistral,因为所有模型将原生支持推理能力。」紧接着 5 月 22 日推出 Mistral Medium 3.5,把之前分散在 Magistral(推理)、Pixtral(视觉)、Devstral(编码)三个专项模型中的能力,整合进一个 128B dense 模型。4
Medium 3.5 同时以开源权重发布,这是一个相对少见的选择——在 128B 参数量级,多数竞争对手选择闭源。
在具体能力上,Medium 3.5 的设计目标是:Instruction following、推理和编码三者不再是分开训练的模块,而是在同一模型中都有调节空间(通过「可调节推理力度」实现)。
这一策略重组背后是 Mistral 更大的转型动作:5 月底发布 Vibe(Le Chat 品牌的完整重命名),定位「工作 AI 智能体平台」;同期发布的 Vibe Work Mode 和 Vibe Remote Agents 把 Medium 3.5 作为调度核心。
Medium 3.5 在 NVIDIA NeMo 文档里标注为 128B dense,推理和编码能力均在 Mistral 内部评测中超过 Magistral Medium,视觉能力继承自 Pixtral 路线。独立第三方 benchmark 对比数据截至本文发布时尚未出现,此处暂不列表。
横向观察:四个发布背后的同一条趋势
四周,四家公司,四次发布。放在一起看有几个共同点:
Agent 执行已成为评测主战场。 HLE-Full w/ tools、OSWorld、Toolathlon、Terminal Bench——这些名字在一两年前还不存在。现在它们出现在每一个旗舰模型的发布材料里,比 MMLU、HumanEval 更靠前。这不是评测趋势变化,而是实际使用场景已经移动了。
「比竞品更快且不贵」是 2026 年的新竞争轴。 Google 3.5 Flash 用「4 倍于同级 frontier 的速度」定义了一个新坐标;Kimi K2.6 用低于闭源竞品 1/5 的 token 价格提供相近性能;Mistral 把推理、视觉、编码塞进一个模型是另一种「单位成本最大化」逻辑。
Mistral 的 Magistral 废弃是一个值得单独记录的信号:专项推理模型正在被通用模型的原生推理替代。如果这个逻辑成立,类似的产品线收缩在其他公司也会陆续出现。
涵盖时间窗:2026 年 4 月 20 日 — 5 月 22 日。各模型 benchmark 数字来自官方发布材料和第三方测试,部分独立复现数据截至发文时仍在更新中。
围绕这条内容继续补充观点或上下文。