AAR 强化学习奖励建模任务 PGR
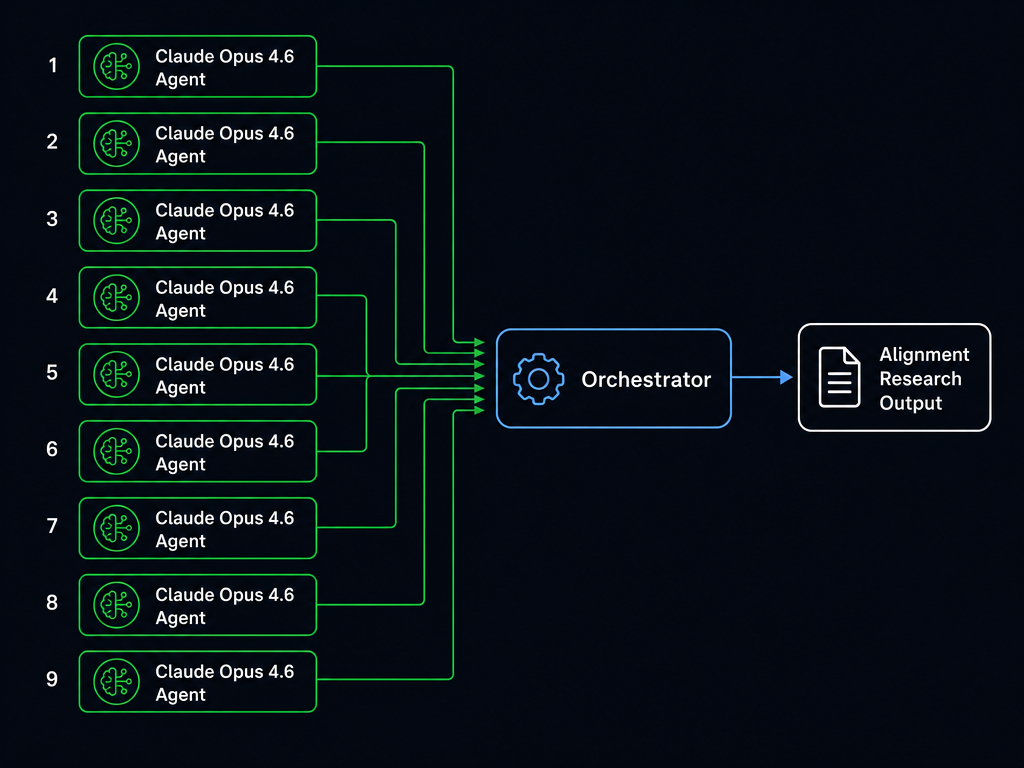
目标任务:强化学习奖励建模;完整运行参数:9 个并行 Agent,800 研究小时,$18,000 计算成本
Anthropic 发布 AAR 技术报告,9 个 Claude Opus 4.6 并行 Agent 在强化学习奖励建模任务上将性能缺口从 23% 压缩至 3%,首次以实验数据验证 AI 自主执行对齐研究的可行性。
研究速览
| 项目 | 内容 |
|---|---|
| 论文全名 | Automated Alignment Researchers: Using large language models to scale scalable oversight |
| 机构 | Anthropic |
| 发布日期 | 2026-04-14 |
| 一手链接 | anthropic.com/research/automated-alignment-researchers |
| Venue | 技术报告(Anthropic Research),未经同行评审,非会议/期刊投稿 |
| 开源 | MIT 许可,代码已在 GitHub 公开2 |
MIT 许可开源,含完整沙箱环境、数据集、基线代码与 Agent 代码
围绕这条内容继续补充观点或上下文。