7B matches last year's 70B on math at 1/40th the serving cost
DeepSeek's R1 distilled 7B model scores 55.5% on AIME 2024 -- versus GPT-4o's 9.3% -- at roughly 1/40th the serving cost of the full 671B model. This issue traces the exact technique behind that compression, compares it to a newer non-parametric approach that achieves similar accuracy recovery with zero weight changes, and examines why person distillation -- capturing how a specific human reasons -- remains at a much earlier rung.

A 7B-parameter model now matches last year's best closed-source reasoning on high-school math at roughly 1/40th the serving cost -- and the technique behind it is pure distillation: no new architecture, no extra training compute for the small model. That ratchet clicked forward again in early 2025 with DeepSeek-R1's distilled family, and it has not stopped since. This issue traces exactly how far the compression curve has moved, and what it means for the slower-moving question of distilling a person rather than a benchmark score.
The advance: distillation by imitation, not by training
The standard story of knowledge distillation goes back to Hinton et al. (2015): train a large teacher model, then have a small student model mimic the teacher's output distribution rather than hard labels. DeepSeek's R1 paper published in January 2025 pushed this further in a concrete direction.1
The recipe has two stages. First, a 671B mixture-of-experts model (37B parameters active per token) is trained with reinforcement learning until it develops structured chain-of-thought reasoning. Second, that model generates 800,000 reasoning traces. A much smaller student model is then fine-tuned on those traces alone -- no RL, no expensive GPU-hours for the student. The student learns to imitate the thinking pattern, not just the answer.
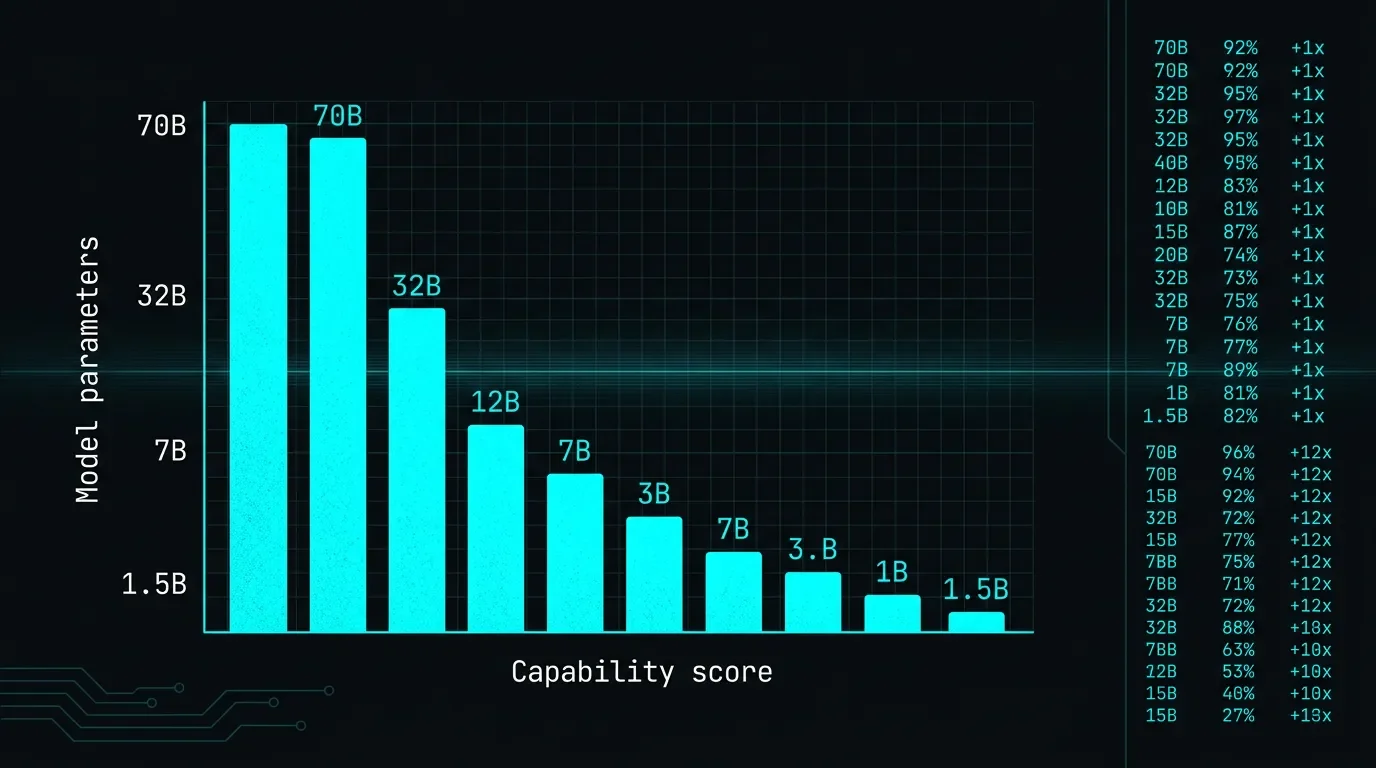
The benchmark outcomes are the kind of numbers that tend to get marketing treatment, so here are the raw figures from the paper itself:
Loading chart…
The 7B distilled model scores 55.5% on AIME 2024, versus GPT-4o at 9.3% on the same benchmark.1 The 1.5B model hits 28.9%, also beating GPT-4o on this single math benchmark.2
What was actually measured, and what wasn't
Before reading these numbers as a verdict, the comparison is almost deliberately narrow. AIME is a specific math competition format -- structured, well-defined, with verifiable answers. It rewards the kind of systematic deduction that chain-of-thought training explicitly targets. The R1-distill models were fine-tuned on reasoning traces produced by a model trained to maximize exactly this kind of score. The gap closes here faster than it would on open-ended writing, multi-turn dialogue, or tasks requiring broad world knowledge.
The original R1 paper notes that the distilled small models show "poor performance on general benchmarks like AlpacaEval 2.0."1 They score well on math and coding because those domains match the training data distribution of the reasoning traces. They are not broadly capable models at their size.
The cost reduction is real, however. The base R1 model has 671B parameters total, with 37B active per token during inference. An open-source 7B model running on a single consumer GPU costs roughly 40x less to serve per token than the full model running on a multi-GPU server.3 That ratio holds regardless of benchmark comparisons.
A non-parametric route: prompt-level distillation
A different approach published in June 2026 skips parameter updates entirely.4 The technique, called Prompt-Level Distillation (PLD), extracts reasoning patterns from a large teacher model and compresses them into a system prompt for a smaller student model -- no weights are changed.
The process: the teacher model generates explanations for labeled training examples, those explanations are clustered by semantic similarity using DBSCAN, outliers are pruned, and the result is a short set of generalizable instructions. When the student model is wrong on training examples, the teacher revises the instructions in a feedback loop until validation error converges.
On the StereoSet benchmark (Macro-F1), a Gemma-3 4B model jumped from 0.57 baseline to 0.90 with PLD applied, matching Gemini 3 Flash (0.92) -- the teacher used to extract the instructions.4 On Mistral Small 3.1, the same technique brought StereoSet from 0.65 to 0.97, surpassing the teacher. On Contract-NLI (Macro-F1), Gemma-3 4B went from 0.67 to 0.83.
The latency and cost comparison is straightforward: Gemma-3 4B runs 80x faster and costs 25x less per inference than Gemini 3 Flash.4 PLD adds zero inference overhead because the instructions are in the prompt, not in an added computation layer.
The important caveat: these results are on classification and constrained-output benchmarks where the "right answer" is well-defined. The authors do not test open-ended generation, and the clustering step means the extracted instructions are averaged across the training set -- they capture general reasoning patterns, not fine-grained behavioral details.
The person-distillation frontier: fidelity without a clear metric
The compression of model capability is measurable because capability has agreed proxies (benchmark scores, perplexity, preference ratings). The compression of a specific person's reasoning and voice is harder to measure, and the field is still settling on what "fidelity" means.
A June 2025 paper from ACL Findings proposed an atomic-level evaluation framework for persona fidelity in language models.5 The core observation is that existing methods score persona adherence at the response level -- one number per output -- which misses subtle out-of-character (OOC) behavior in long generations. The atomic framework breaks a response into individual claims, each scored for consistency with the specified persona.
The paper finds that task structure and "persona desirability" both influence fidelity. Structured tasks (where the model has a clear constrained role) show higher fidelity than open-ended ones. More importantly, models tend to drift toward safe, agreeable responses when a persona conflicts with social norms -- the model is hedging against its own training, not faithfully representing the specified character.
This is the gap between a persona spec and a person. A behavioral persona can be specified in a prompt: "Reply in the style of person X, who tends toward blunt disagreement and rarely asks follow-up questions." The model will approximate that style up to the point where its alignment training pushes back. What is not yet captured: the specific weighted combination of world knowledge, implicit assumptions, and decision heuristics that characterize a real individual's outputs in novel situations.
Where the ladder stands
The compression frontier for capability is moving faster than most projections from two years ago. The DeepSeek distillation results, now cited in dozens of subsequent papers, established a concrete data point: reasoning patterns learned by a very large model under reinforcement learning transfer to small models through imitation, preserving most of the math and coding capability at a fraction of the serving cost.
Person distillation is at an earlier stage. The field has evaluation frameworks, behavioral cloning methods for constrained domains (email reply style, code generation habits, writing voice), and growing interest in agentic skill capture. What is missing: a general method that transfers the implicit prior -- the background distribution of how a particular mind weights evidence, shifts registers, and navigates uncertainty -- not just the surface behavioral signature.
Loading stats card…
The gap is not philosophical. It is an engineering and measurement problem: we do not yet have a training objective that targets "faithfully reproduce how this specific person would reason about a novel situation they have never encountered." Behavioral cloning captures the distribution of past outputs. It does not yet capture the generative process behind them.
Each issue of this radar will advance one rung -- tracking where the numbers move, and being precise about what they do and do not show.
References
- 1DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 2Small Language Models (SLMs) Can Still Pack a Punch: A Survey
- 3DeepSeek-R1 distilled benchmarks analysis
- 4Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning
- 5Spotting Out-of-Character Behavior: Atomic-Level Evaluation of Persona Fidelity in Open-Ended Generation
Related content
- Sign in to comment.