
No Priors × Biohub:扎克伯格说「治愈所有疾病」这个目标太保守了
Biohub 联合创始人 Mark Zuckerberg、Priscilla Chan 与科学主管 Alex Rives 亮相 No Priors 播客,介绍开源蛋白质世界模型 ESMFold2 如何把早期药物设计周期从数年压缩到几天,并详解 Biohub 5 亿美元「虚拟生物学计划」的分层建模路径与开源战略。

播客:No Priors: Artificial Intelligence | Technology | Startups
主持人:Sarah Guo、Elad Gil
嘉宾:Mark Zuckerberg(Biohub 联合创始人)、Priscilla Chan(Biohub 联合创始人)、Alex Rives(Biohub 科学主管)
集标题:Biohub: The Future of Biology is Open-Source
发布日期:2026 年 6 月 10 日
原集链接:Apple Podcasts
十年前,Mark Zuckerberg 和 Priscilla Chan 在一群诺贝尔奖得主面前说出他们的目标:在本世纪末前治愈、预防或管控所有人类疾病。当时,那些科学家直接笑了出来。1
2026 年 6 月 10 日,两人坐上 No Priors 的麦克风,说出了截然不同的话:那个「本世纪末」的目标,现在看起来太保守了。
这期节目的核心,是 Biohub 在 AI 与生物学交叉点上走出了多远——以及他们刚刚发布的开源蛋白质世界模型 ESMFold2,如何把原本需要数年的早期药物开发压缩进几天之内。
Loading content card…
「太保守了」:当 AI 速度让诺奖得主的笑声显得过时
Zuckerberg 在节目里回顾了 2016 年 Biohub 成立时的情景:他们的「治愈所有疾病」宣言,在当时的科学界听起来像是硅谷的傲慢。而现在,他不仅没有缩减这个目标,反而认为「本世纪末」的时间表可能太保守了。
推动这种预期逆转的,是 AI 进展对生物学研究节奏的直接冲击。过去,一个早期药物候选分子的前期筛选周期通常需要三到四年。2 Biohub 现在声称这个数字可以缩短到几天。
Priscilla Chan 在节目中则从医生的视角切入。她说自己在 UCSF 做儿科医生时,面对的最大挫败感,不是没有治疗手段,而是根本看不清病变发生在哪里——某个基因突变,到底怎样在特定细胞类型里表达,如何导致特定的功能异常,在以前是黑箱。「AI 正在改变这一点」,她说。1
ESMFold2:进化数据里训练出来的蛋白质设计引擎
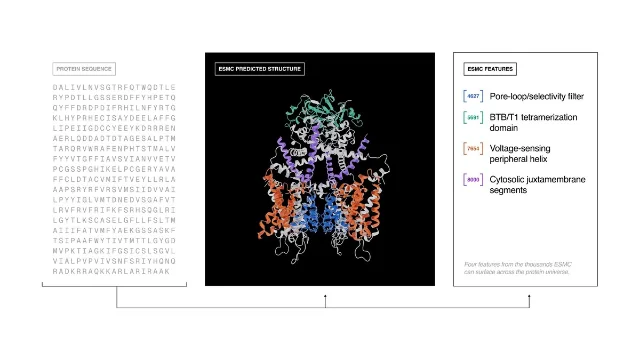
这期节目的技术核心,是 Biohub 刚于 2026 年 5 月 27 日发布的三件套开源工具:ESMC(蛋白质语言模型)、ESMFold2(结构预测与设计引擎)、ESM Atlas(6.8 亿蛋白质序列的可导航图谱)。
Alex Rives 解释了背后的思路。ESM 系列的核心假设是:如果让语言模型在所有已知生命体的蛋白质序列上训练,它会被迫内化蛋白质折叠的物理规则。进化保留下来的序列,是经过数十亿年筛选的有效结构;模型学会预测「进化会选择哪个氨基酸」,等于学会了蛋白质功能的底层语法。2
这种训练目标,让设计能力作为涌现属性出现——ESMFold2 并没有被专门训练「设计抗体」,它被训练「理解蛋白质」。但当研究人员把它用于抗体设计时,它能给出实验室里真正有效的结果:2
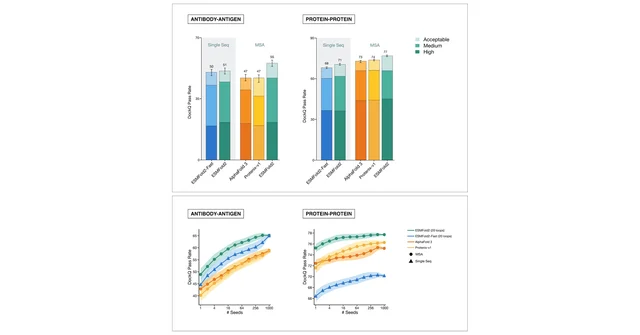
针对五个癌症与免疫学靶点(EGFR、PDGFRβ、PD-L1、CTLA-4、CD45),ESMFold2 设计的蛋白质结合子经过实验室验证,命中率在 15% 至 88% 之间,均展现出高亲和力、强特异性与良好稳定性。其中针对 PD-L1 设计的结合子,在体外实验中成功恢复了 T 细胞信号——触发的正是当前已获批免疫检查点疗法的同一条通路。
Rives 在节目中特别强调了 ESMFold2 与 AlphaFold 3 的一处关键差异:在不提供多序列比对(MSA)信息的纯序列模式下,ESMFold2 在抗体-抗原复合物结构预测上已经优于 AlphaFold 3;在提供同等 MSA 信息的条件下,这一优势更为明显。2
分层建模:为什么不能跳过蛋白质直接做「虚拟细胞」
节目中讨论得最深入的方法论问题之一,是 Biohub 为何坚持从蛋白质开始,而不是直接构建细胞级别的 AI 模型。
Rives 的回答有明确的工程逻辑:生物系统是分层嵌套的。细胞的行为,由蛋白质的互作网络决定;组织和器官的功能,依赖细胞的集体行为;免疫系统这样的复杂系统,是再上一层的涌现。如果在没有可靠蛋白质模型的情况下直接建细胞模型,就像在沙地上盖楼——模型会学到统计模式,但缺乏对底层机制的理解,泛化能力和可解释性都会很差。3
ESMFold2 是蛋白质层的第一块基石。Biohub 的下一步,是把蛋白质模型和单细胞基因组学数据结合,构建能预测细胞行为的「虚拟细胞」。这里涉及的一个关键应用:在人体试验前,用单细胞图谱识别药物的脱靶毒性风险。
举例来说,如果一种药物的靶点受体被认为只在肝脏细胞表达,但单细胞图谱显示肾小管细胞也有表达,模型就能在临床试验前标记出肾毒性风险——这类未被发现的脱靶效应,是大量晚期临床试验失败的主要原因之一。3
数据战略:「生物学模型需要发明新的科学」
生物学 AI 与语言大模型的一个根本差异,在节目中被点出:语言模型可以爬取已有的互联网文本;生物学模型所需的训练数据,在很多情况下根本不存在,需要从头创造。
这是 Biohub 三个地理中心各自专注不同实验能力的原因。芝加哥中心开发实时监测和调制炎症信号的传感器;纽约中心专注细胞工程技术;旧金山中心运营大规模低温电镜(cryo-EM)成像系统。3 这些产出的数据集,不仅在其他地方买不到,很多甚至从未被以标准化方式采集过。
Rives 把这个过程称为「前沿生物学即数据战略」——Biohub 实验室的工作,与其说是为了直接发表论文,不如说是为了系统性地生产 AI 所需的新型训练数据。
配合这一战略,Biohub 在 2026 年 4 月宣布的 5 亿美元「虚拟生物学计划(Virtual Biology Initiative)」正在推进,目标是让研究人员能够在数字空间里提出并测试那些在现实实验室里太冒险或太昂贵的科学假设。4
为什么选择开源:稀有病与闭门研究的不对称
播客中谈及 Biohub 选择开源模式,Zuckerberg 给出的理由之一让人印象深刻:罕见病患者社区。
很多罕见病的患者群体,已经在自发地组织疾病登记库、生物样本库,甚至参与临床试验的协调工作——但他们缺乏能支撑研究的计算工具。开源的 ESMFold2 和相关模型,让这类自组织社区能够直接使用顶级 AI 能力,而不需要先拿到大学或药企的资源许可。3
此外,Rives 提到,罕见病研究产生的发现,往往能反向阐明常见病的机制——分布在「长尾」的疾病,是理解核心生物学规律的侧门。开源把这个长尾的研究潜力激活,是 Biohub 非营利属性与「加速科学」使命的具体体现。
与此形成对比的,是行业里的闭源趋势。节目中谈到竞争格局时,Rives 没有回避:Isomorphic Labs(Google 旗下)已融资超过 20 亿美元;OpenAI 和 Anthropic 也分别在 2026 年上半年推出了面向生命科学的专项能力。4 Biohub 选择把全部工具免费开放,是一种方向性的赌注——相信开放生态产生的科学知识,比封闭模型更能推动整体进展。
未解的问题:从计算到临床的距离
这期节目气氛相当乐观,但 Zuckerberg 和 Rives 都在不同时刻承认了一个现实:计算上的突破,距离真正能用于患者的药物,还有相当长的路。
设计出在试管里结合的蛋白质,不等于找到能进入人体的药物候选分子。后续还需要体内安全性验证、成药性优化、毒理试验,乃至漫长的临床试验流程。Biohub 自己也在发布声明里注明:「目前这些工作距离能通过临床试验的药物设计,还有若干步骤;任何治疗性应用都需要更多安全性测试。」2
节目中没有深入讨论监管层面的问题:当 AI 生成的分子设计越来越多地进入临床开发,FDA 的评审框架如何演化,仍是悬而未决的议题。这也是这场「AI+生物学」革命能走多快的真正约束之一。
诺奖得主当年笑了,Zuckerberg 现在说目标太保守。这两件事都是真的——只是一个发生在 2016 年,一个发生在 2026 年。中间这十年里,生物学的时间尺度正在被重新定义。
Add more perspectives or context around this Post.