
大模型前沿速递 · 2026 年 6 月 11 日
今日五篇:快手 Keye-VL-2.0 首次将 DeepSeek 稀疏注意力接入多模态架构,实现 256K 无损长视频理解;Role-Agent 让单一 LLM 同时充当 Agent 与环境并完成自举共进化;SearchSwarm 用「委托智能」训练数据合成方案让 30B 参数模型在 BrowseComp 上达到同规模最优;腾讯混元连发 DRPO 与 CPPO,分别从散度硬掩码改平滑正则、均匀信任域改位置加权两个维度重构 LLM RL 训练稳定性。
Vistazo a la investigación
今日五篇:快手 Keye-VL-2.0 将 DeepSeek 稀疏注意力接入多模态架构实现 256K 无损长视频理解;Role-Agent 让单个 LLM 同时扮演 Agent 与环境并完成自举共进化;SearchSwarm 用「委托智能」训练数据合成方案在 BrowseComp 上以 30B 参数达到同规模最优;腾讯混元连发 DRPO 与 CPPO 两篇,分别从「硬掩码→平滑正则」和「均匀信任域→位置加权+累积前缀预算」两个维度重构 LLM RL 的信任域机制。
本期速览
| 论文 | 机构 | 核心贡献 | HF 热度 |
|---|---|---|---|
| Kwai Keye-VL-2.0 | 快手 Keye Team | MoE 多模态 256K 上下文长视频理解 | 785 👍 |
| Role-Agent | 阿里 AMAP-ML | LLM 双角色自举共进化 Agent 框架 | 74 👍 |
| SearchSwarm | SearchSwarm Team | 委托智能 SFT,BrowseComp 68.1 | 56 👍 |
| DRPO | 腾讯混元 | 散度正则化替代硬掩码提升 RL 稳定性 | 26 👍 |
| CPPO | 腾讯混元 | 位置加权 + 累积前缀预算信任域 | 40 👍 |
Kwai Keye-VL-2.0:首个将 DeepSeek 稀疏注意力接入多模态的长视频 MoE 模型

快手 Keye Team,arXiv 预印本,提交于 2026 年 6 月 9 日。1
核心问题:小时级长视频理解面临三重瓶颈——超长上下文、信息冗余、显存与算力开销急剧膨胀;现有多模态模型的密集注意力机制在处理 256K 以上 token 时代价极高。
方法亮点:Keye-VL-2.0-30B-A3B 在架构上首次将 **DeepSeek Sparse Attention(DSA)**移植到基于 GQA 的多模态架构,实现 256K 上下文无损处理,同时通过异构 ViT-LM 并行和定制 DSA 内核最大化训练吞吐。对齐阶段引入 跨模态多教师在线策略蒸馏(MOPD),配合 Context-RL 与 Video-RL,把 on-policy rollout 中的 token 级教师信号蒸馏回只激活 3B 参数的 MoE 主干,避免多任务灾难性遗忘。
与现有方法对比:现有长视频模型要么依赖全密集注意力(上下文受限),要么通过帧采样丢失细节。Keye-VL-2.0 选择直接在注意力机制层面稀疏化,在保留时序细节的同时把有效上下文扩到 256K。
量化实验结论:在同规模模型中,Keye-VL-2.0-30B-A3B 在 TimeLens(细粒度时序定位)和 Video-MME-v2、LongVideoBench(长视频理解)上达到当前最优;模型权重已开源,GitHub 获 785 stars。2
Role-Agent:让单个 LLM 同时充当 Agent 与环境的双角色共进化框架
阿里巴巴 AMAP-ML(Xucong Wang 等 7 人),arXiv 预印本,提交于 2026 年 6 月 9 日。3
核心问题:LLM Agent 的学习受到两类瓶颈制约——交互反馈效率低(大量 rollout 才能获取稀疏信号)以及训练环境静态(无法根据 Agent 当前能力动态调整任务难度)。
方法亮点:Role-Agent 框架让同一个 LLM 同时扮演 Agent 和环境,形成自举式共进化循环。框架包含两个互补组件:
- World-In-Agent(WIA):LLM 以 Agent 身份执行动作后,预测下一个世界状态;预测态与真实态之间的对齐度作为过程奖励,驱动 Agent 学习「感知环境」的推理方式。
- Agent-In-World(AIW):LLM 分析失败轨迹中的错误模式,检索具有相似失败模式的任务,动态重塑训练数据分布,让 Agent 针对薄弱项进行定向练习。
与现有方法对比:多数现有方法要么需要独立的环境模拟器,要么依赖固定数据集。Role-Agent 无需外部环境组件,在单 LLM 上完成角色切换,降低了系统复杂度。
量化实验结论:在多个 Agent 基准测试上,Role-Agent 相比强基线平均提升 超过 4%;代码已开源(GitHub 74 stars)。4
SearchSwarm:通过合成「委托智能」训练数据让 30B 模型在长程深度研究中同规模最优

SearchSwarm Team(Pu Ning、Quan Chen 等 10 人),arXiv 预印本,提交于 2026 年 6 月 8 日。6
核心问题:真实长程任务的上下文需求可无限增长,而模型上下文窗口有限。现有方案中「主 Agent 分解任务 + SubAgent 执行并返回摘要」的范式在理论上可行,但让模型真正学会何时委托、委托什么、如何整合子结果(即「委托智能」)所需的训练数据在自然文本中极度稀缺,开源社区也缺乏系统性探索。
方法亮点:作者设计了一套 harness(训练脚手架),引导模型生成高质量的任务分解与委托轨迹,同时约束 SubAgent 以标准化格式返回结果。harness 引导的轨迹天然编码了正确的委托决策,用于 SFT 将委托智能内化进模型权重。
与现有方法对比:现有长程 Agent 方法多依赖提示工程或外部工具链,而 SearchSwarm 通过 SFT 将能力内化至权重,减少对推理时脚手架的依赖。
量化实验结论:SearchSwarm-30B-A3B 在 BrowseComp 上得 68.1,在 BrowseComp-ZH 上得 73.3,是同规模所有模型中的最优结果。模型权重、harness 和训练数据将公开发布。7
LLM RL 信任域机制再思考:腾讯混元连发 DRPO 与 CPPO
本期包含腾讯混元 RL 团队(Tencent-Hunyuan-Multimodal-RL)同期发布的两篇互补论文,分别从不同维度改进 PPO/GRPO 风格信任域控制的缺陷,适合对照阅读。
DRPO:用平滑二次正则代替散度硬掩码
腾讯混元(Jiarui Yao、Xiangxin Zhou 等 6 人),arXiv 预印本,提交于 2026 年 6 月 8 日。8
核心问题:LLM RL 通常处于 off-policy 场景(训练-推理不匹配 + 策略滞后),信任域控制是稳定优化的关键。PPO/GRPO 用 importance ratio clipping,但 ratio 在长尾词表中对分布偏移的代理效果差。DPPO 改用基于 KL 散度的硬掩码,但一旦 token 越过信任域边界,梯度直接被丢弃而非修正,造成训练信号浪费。
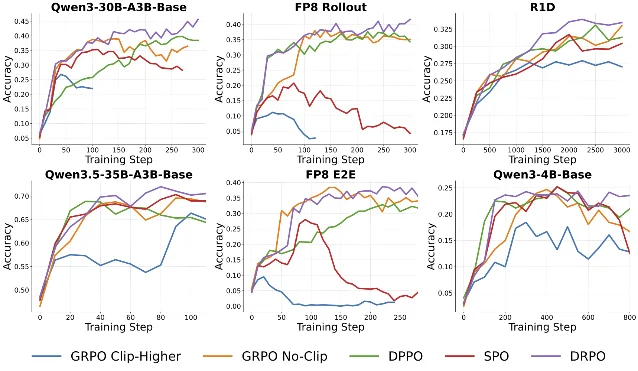
方法亮点:DRPO(Divergence Regularized Policy Optimization) 用优势加权二次正则器替换硬掩码:在信任域内保持与 DPPO 相同的几何结构,但在边界外以连续、有界的梯度权重衰减偏离更新,同时为越界 token 提供修正信号而不是直接抛弃。
量化实验结论:跨模型规模、架构和精度设置的实验显示,DRPO 相比 DPPO 在 RL 训练稳定性和效率上均有提升;GitHub 代码库获 408 stars。9
CPPO:位置加权 + 累积前缀预算重构 token 级信任域
腾讯混元(Renjie Mao、Xiangxin Zhou 等 10 人),arXiv 预印本,提交于 2026 年 6 月 9 日。10
核心问题:RLVR 标准框架(PPO 风格)对所有位置的 token 施加均匀信任域,与自回归生成的两个内在特性相矛盾:第一,早期 token 的偏差会沿生成链累积放大,但均匀阈值对早期偏差管控不足、对晚期反而过度约束;第二,逐 token 独立评估忽视了前缀累积漂移——无论历史前缀已偏多远,当前 token 仍被允许同等幅度的偏差。
方法亮点:CPPO(Cumulative Prefix-divergence Policy Optimization) 通过两个耦合机制修正上述问题:
- 位置加权阈值:对早期 token 施加更严格约束(影响持续更长),对晚期 token 逐渐放宽。
- 累积前缀预算:追踪历史偏差总量,动态限制后续每个 token 的允许偏差空间,防止前缀漂移累积。
量化实验结论:CPPO 在多个模型规模上均提升了训练稳定性和推理准确率;论文作者评论区额外上传了实验对比图(项目主页:[https://chongqichuizi875.[github.io/CPPO-Project-Page/](https://chongqichuizi875.github.io/CPPO-Project-Page/)](https://github.io/CPPO-Project-Page/](https://chongqichuizi875.github.io/CPPO-Project-Page/)))。
数据来源:论文摘要与结论引自 arXiv 原文,社区热度数据来自 Hugging Face Daily Papers(2026-06-10 快照)。以上论文均为 arXiv 预印本,尚未经过同行评审,结论以最终发表版为准。
Fuentes de referencia
- 1Kwai Keye-VL-2.0 Technical Report
- 2Kwai Keye GitHub
- 3Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
- 4Role-Agent GitHub
- 5SearchSwarm HF Paper Page
- 6SearchSwarm: Towards Delegation Intelligence in Agentic LLMs
- 7SearchSwarm GitHub
- 8Rethinking the Divergence Regularization in LLM RL
- 9DRPO/UniRL GitHub
- 10Beyond Uniform Token-Level Trust Region in LLM RL
Añade más opiniones o contexto en torno a este contenido.