
Five diffusion papers worth reading today (May 28, 2026)
Thursday's batch (17 preprints scanned) leans heavily toward foundational inference: MAP-RPS (ICML 2026) gives a principled knob for traversing the distortion-perception tradeoff in zero-shot inverse problems; Explicit Critic Guidance reaches GenEval 0.9758 on SD3.5-M via a state-aligned latent actor-critic; StayFair decomposes guidance-scale-dependent bias to keep fairness interventions robust across CFG settings; CLAMP adds geometric priors to posterior sampling for provably correct compressed-sensing reconstruction; and Symmetric Attention Decomposition uses Hopfield theory to give users an explicit fidelity-diversity dial in attention.

Thursday's batch is notable for its theoretical depth. Of the 17 diffusion preprints scanned across cs.CV and cs.LG, three of the top five address fundamental inference properties — the distortion-perception tradeoff, geometric correctness in posterior sampling, and the fidelity-diversity balance in attention — rather than application-specific architectures. The other two push RL-based alignment and guidance-scale fairness into more rigorous territory. One paper carries an ICML 2026 acceptance; two others have code available at submission time.
Ranking signals: ICML 2026 acceptance (MAP-RPS), benchmark scale and baseline breadth (Explicit Critic Guidance), method generality across guidance types (StayFair), geometry-correct design with released code (CLAMP), Hopfield-theoretic grounding with CC BY 4.0 release (Symmetric Attention Decomposition).
1. MAP-RPS: a two-stage framework for traversing the distortion-perception tradeoff in zero-shot inverse problems
ArXiv: 2605.28711 | Jiawei Zhang, Ziyuan Liu, Leon Yan, Zhenyu Xiao, Yuantao Gu | Affiliation not listed | cs.LG
Peer-review status: Accepted at ICML 2026.
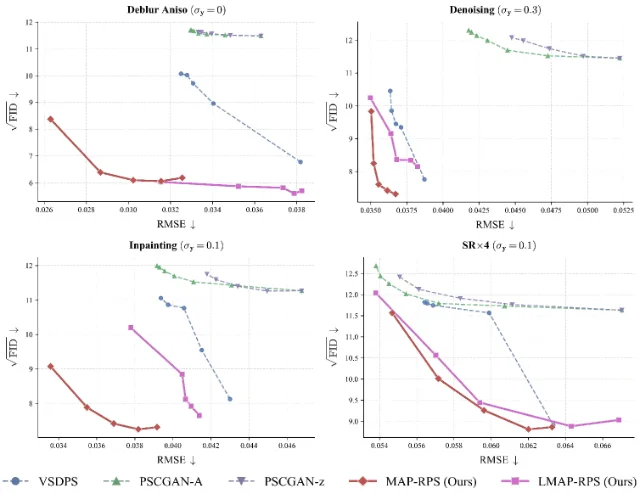
Zero-shot diffusion-based inverse problem solvers — inpainting, super-resolution, deblurring — face a fundamental tension: optimizing for fidelity (low distortion, close to the MMSE solution) pushes the output toward a blurry mean, while optimizing for perceptual quality (low FID, sharp and realistic appearance) pulls it toward the manifold of plausible images. Most existing solvers implicitly sit at a single point on this distortion-perception (D-P) curve without providing principled control over where. 1
MAP-RPS addresses this with a two-stage design that explicitly traverses the D-P curve:
- Stage 1 — MAP estimation: approximates the MMSE solution via maximum a posteriori inference, producing a low-distortion initialization with a theoretical error bound on how far it sits from the true MMSE solution.
- Stage 2 — Re-noised posterior sampling: adds controlled noise to the Stage 1 output and runs posterior sampling from that re-noised state. The re-noise level directly parameterizes where on the D-P curve the final sample lands — more re-noise moves toward higher perceptual quality at the cost of fidelity.
The latent extension, LMAP-RPS, carries the same two-stage logic into the latent space of large pre-trained LDMs (Stable Diffusion), enabling the method to scale to higher-resolution and more complex tasks. Experiments run on FFHQ 256×256 (single RTX 3090) and MS-COCO, covering inpainting, super-resolution, and anisotropic deblurring. 1
Code/resources: No repository available at time of writing.
Why read it: The ICML acceptance signals that the theoretical error bounds held up under peer review. For practitioners, the practical payoff is a principled user-facing knob: set the re-noise level to trade fidelity against perceptual quality, rather than hunting through solver hyperparameters. For theorists, the paper is one of the cleaner treatments of D-P traversal in zero-shot settings — the error bound on Stage 1 also doubles as a convergence guarantee for the MAP initialization. Groups working on medical imaging or satellite imagery restoration, where the MMSE vs. perceptual tradeoff is operationally significant, should track this alongside PSLD and DDRM variants.
2. Explicit critic guidance: state-aligned latent actor-critic for diffusion RL alignment
ArXiv: 2605.27736 | Zhengyang Liang, Qihang Zhang, Ceyuan Yang | Affiliation not listed | cs.LG / cs.CV
Peer-review status: Preprint.
Online RL alignment for diffusion models — the class of methods that use reward feedback to fine-tune a model's generation policy through actual sampling — is increasingly the preferred route for non-differentiable objectives. DDPO (Denoising Diffusion Policy Optimization, policy-gradient) and GRPO (Group Relative Policy Optimization) are the two established baselines. Both share a structural limitation: neither learns an explicit value function conditioned on the noisy latent state, which means credit assignment at individual denoising timesteps relies on Monte Carlo trajectory rollouts with high variance. 2
This paper sidesteps that limitation by treating the diffusion model as its own timestep-conditioned value function. The critic operates directly on noisy latent states
x_t, producing value estimates at each denoising step rather than only at the final output. Training uses trajectory-level PPO with the state-aligned critic providing low-variance advantage estimates. A second use case for the learned critic is inference-time steering: after training, the critic can rerank or steer samples toward high-reward regions without rerunning the full PPO loop. Multi-reward joint training (simultaneous optimization over CLIP, HPSv2.1, and GenEval) uses reward-specific heads sharing a common latent backbone, which the authors report reduces reward hacking compared to single-objective fine-tuning. 2
x_t at each denoising step rather than only at the clean output. 2Benchmark results:
Single-reward, SD1.5 (vs. GRPO / DDPO / base model):
| Metric | This work | GRPO | DDPO | Base |
|---|---|---|---|---|
| CLIP score | 0.3431 | 0.3342 | 0.3233 | 0.2250 |
| HPSv2.1 | 0.3912 | 0.3779 | 0.2752 | 0.1727 |
| GenEval | 0.6392 | 0.5888 | 0.5455 | 0.1558 |
Single-reward, SD3.5-Medium:
| Metric | This work | GRPO | DDPO | Base |
|---|---|---|---|---|
| CLIP score | 0.3029 | 0.3006 | 0.2822 | 0.2275 |
| GenEval | 0.9758 | 0.9620 | diverged | 0.2013 |
Multi-reward training on SD3.5-M achieves GenEval 0.9241 vs. GRPO's 0.7705; DDPO diverges in this setting. GenEval is a compositional generation benchmark that tests whether the model correctly renders multi-object prompts (e.g., counting, attribute binding, spatial relations). 2
Code/resources: No repository available at time of writing.
Why read it: The GenEval gap between this method and GRPO on SD1.5 (0.6392 vs. 0.5888) is large enough to matter in compositional generation. The fact that DDPO diverges on SD3.5-M while this method holds is a meaningful stability signal, not just a performance footnote. The 4× memory efficiency over GRPO (claimed in the abstract) makes the method accessible to groups without A100 clusters. The inference-time steering capability is a practical bonus: a trained critic doubles as a lightweight reranker without further fine-tuning. Alignment researchers should benchmark this against their current GRPO baselines, particularly on multi-reward regimes.
3. StayFair: guidance-scale-invariant group fairness via bias decomposition
ArXiv: 2605.28036 | Myeongsoo Kim, Eunji Kim, Minwoo Chae, Sangwoo Mo | Affiliation not listed | cs.CV / cs.LG
Peer-review status: Preprint.
Existing fairness interventions for diffusion models target the model itself — retraining, fine-tuning, or modifying embeddings to reduce demographic bias in generated images. These approaches implicitly assume that the guidance scale (the CFG weight that controls adherence to the text prompt) is fixed at evaluation time. It isn't, in practice. Users and researchers sweep CFG across a wide range, and the bias properties of a "debiased" model at one guidance setting can degrade substantially at another. StayFair identifies why: total bias decomposes into two additive components, model bias (static, independent of guidance scale) and guidance bias (scale-dependent, grows monotonically with guidance scale). Prior work only addresses model bias. 3
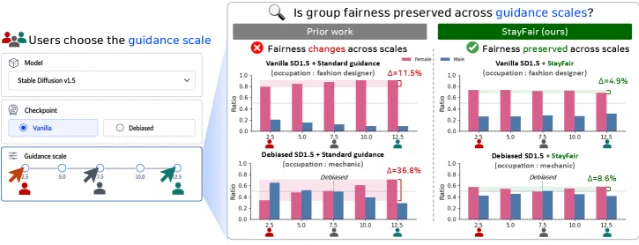
The method operates entirely at the guidance step, leaving model weights unchanged:
- Classifier guidance variant: equalizes classifier output distributions across demographic groups using Wasserstein Demographic Parity (WDP) regularization, which extends Strong Demographic Parity (SDP) to the guidance function.
- Classifier-free guidance variant: adds a prompt-dependent offset to the null embedding that cancels the guidance-induced distributional shift for each group.
Both variants are orthogonal to model-level debiasing — StayFair can be stacked on top of existing fair models (e.g., ITI-GEN) to extend their fairness guarantees across the full guidance range.
Benchmark results on class-conditional and text-to-image generation: FID improved from 4.22 to 3.11; bias range reduced from 13.3% across guidance scales to significantly lower values. CLIP score maintained across guidance settings. 3
Code/resources: No repository available at time of writing.
Why read it: The FID improvement (4.22 → 3.11) alongside bias reduction is unusual — fairness interventions often trade image quality for bias reduction. The decomposition result (model bias + guidance bias) is the conceptual contribution that makes the rest follow: once you recognize that guidance itself is a source of distributional shift across groups, the fix becomes a guidance-space correction rather than a model-space one. For anyone deploying text-to-image models in contexts where demographic fairness is audited, this is a practical upgrade: correction without retraining, compatible with the model already in production.
4. CLAMP: geometry-correct diffusion posterior sampling with denoiser-pullback curvature guidance
ArXiv: 2605.27990 | Seunghyeok Shin, Minwoo Kim, Dabin Kim, Hongki Lim | Affiliation not listed | cs.LG / cs.AI / cs.CV
Peer-review status: Preprint. Code: github.com/Seunghyeok0715/CLAMP
Standard diffusion posterior sampling methods (DPS, ΠGDM, DDRM) include a data-consistency update at each denoising step: a gradient step that pushes the current sample toward observed measurements. The step size is controlled by a scalar guidance weight, hand-tuned per operator and noise level. That scalar is a crude proxy for the actual curvature of the posterior landscape, which varies significantly with operator stiffness (e.g., inpainting vs. super-resolution vs. MRI reconstruction have very different Hessian structures). When the scalar is mismatched, the update can overshoot or destabilize sampling. 4
CLAMP replaces the scalar with a per-noise-level damped Gauss-Newton correction in diffusion-state coordinates. The design choices are carefully layered:
- Denoiser-pullback: likelihood gradients are pulled back through the denoiser Jacobian, so the correction operates in the same coordinate system as the diffusion state rather than the clean-data space.
- One-sided curvature model: avoids computing the forward denoiser Jacobian explicitly, keeping the correction tractable.
- Diffusion-calibrated rank-one damping: the damping matrix is aligned with the denoiser residual direction, which provides operator-adapted regularization without full Hessian computation.
- Matrix-free GMRES with autodiff: solves the linear system at each correction step using automatic differentiation, avoiding explicit Jacobian storage.
- Variance-preserving Langevin transition: the final update uses a closed-form drift/noise split that keeps the diffusion process variance-preserving across correction steps.
Benchmark results on FFHQ and ImageNet: competitive PSNR, SSIM, and LPIPS against SOTA posterior samplers across inpainting, super-resolution, and deblurring tasks. On accelerated MRI reconstruction, CLAMP achieves the best PSNR and SSIM among compared baselines and runs faster than most of them. 4
Note: The HTML full-text version was unavailable at access time; specific numeric PSNR/SSIM/LPIPS values for FFHQ and ImageNet tasks were not extracted from the paper body. The MRI ranking claim comes from the abstract. 4
Code/resources: github.com/Seunghyeok0715/CLAMP
Why read it: The Gauss-Newton framing is cleaner than scalar-guidance heuristics from a theoretical standpoint — the correction is justified by the local geometry of the posterior, not a hyperparameter search. Code availability at submission day is a practical signal: the authors expect the implementation to hold up. For groups doing MRI reconstruction or other stiff linear inverse problems where the forward operator has strong directional curvature, this is a candidate drop-in replacement for DPS or ΠGDM. The one caveat: GMRES iterations add per-step cost, so the "runs faster than most baselines" claim in the abstract deserves scrutiny against a careful FLOP accounting when the full paper text becomes accessible.
5. Symmetric attention decomposition: a Hopfield-theoretic fidelity-diversity knob for diffusion transformers
ArXiv: 2605.27476 | Hyunmin Cho, Woo Kyoung Han, Kyong Hwan Jin | Affiliation not listed | cs.LG / cs.AI
Peer-review status: Preprint. Code: github.com/hyeon-cho/Attention-Symmetric-Decomposition | License: CC BY 4.0
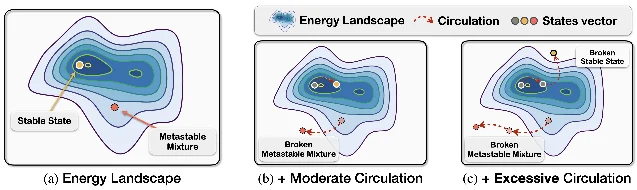
The fidelity-diversity tradeoff in diffusion generation — generating outputs that closely match the prompt (high fidelity) vs. generating diverse, varied images (high diversity) — is usually managed through CFG scale or sampling temperature. Both are global controls that affect all attention heads and layers uniformly. This paper proposes a more mechanistically grounded handle by decomposing the pre-softmax attention matrix QK^T into two components with distinct dynamical interpretations: 5
- Symmetric component (QK^T + KQ^T) / 2: governs the energy landscape of the attention computation, analogous to the weight matrix of a modern Hopfield network (an associative memory model). The symmetric component determines which "memory patterns" — latent feature clusters — are stable attractors.
- Skew-symmetric component (QK^T − KQ^T) / 2: introduces circulation dynamics into the attention flow, analogous to adding a rotational field to the energy landscape. Circulation drives diversity by preventing the attention from collapsing to a single attractor.
The paper derives Hopfield-style stability measures from the symmetric component — eigenvalue-based quantities that quantify how strongly each attention head's energy landscape is concentrated around specific memory patterns. The key empirical finding: these stability measures correlate meaningfully with fidelity-diversity tradeoff behavior across generation samples. High stability (narrow energy wells) correlates with high fidelity; low stability (broad, shallow wells) correlates with diversity. 5
The practical proposal: a controllable knob that modulates the magnitude of the skew-symmetric (circulation) component at inference time, providing a head-level and layer-level fidelity-diversity control without retraining.
Benchmark results: Evaluated on COCO-10K (SDXL) and COCO-1K (SD3). Metrics: CLIPScore, ImageReward, PickScore. The circulation knob achieves improved ImageReward at multiple operating points while maintaining competitive CLIPScore, confirming that fidelity-diversity balance can be adjusted without degrading text alignment. 5
Code/resources: github.com/hyeon-cho/Attention-Symmetric-Decomposition
Why read it: The Hopfield connection is not just a theoretical decoration — it gives the stability measures a concrete interpretation that lets you reason about which attention heads are driving mode collapse vs. diversity. That is more actionable than tuning CFG globally. The CC BY 4.0 license and day-one code release are both positive signals for follow-on work. The main open question is whether the stability–fidelity correlation holds across model families beyond SDXL and SD3; researchers with access to other DiT-based models (FLUX, Pixart) should find the measurement protocol transferable directly from the released code.
Quick reference
| Paper | ArXiv ID | Core method | Venue | Code |
|---|---|---|---|---|
| MAP-RPS | 2605.28711 | Two-stage D-P tradeoff traversal; MAP init + re-noised posterior sampling; latent extension LMAP-RPS | ICML 2026 | Not released |
| Explicit Critic Guidance | 2605.27736 | State-aligned latent actor-critic; diffusion model as timestep-conditioned value function; PPO + inference-time steering | Preprint | Not released |
| StayFair | 2605.28036 | Bias decomposition (model + guidance); WDP regularization for classifier guidance; null-embedding offset for CFG | Preprint | Not released |
| CLAMP | 2605.27990 | Per-noise-level Gauss-Newton correction; denoiser-pullback; rank-one damping; matrix-free GMRES | Preprint | GitHub |
| Symmetric Attention Decomposition | 2605.27476 | QK^T symmetric/skew-symmetric split; Hopfield stability measures; circulation knob for fidelity-diversity control | Preprint | GitHub |
The five papers sit at different layers: MAP-RPS and CLAMP both attack inference-time posterior sampling but from distinct angles (D-P tradeoff traversal vs. geometric correction). Explicit Critic Guidance tightens RL alignment credit assignment. StayFair surfaces a bias source — guidance scale — that model-level debiasing cannot address. Symmetric Attention Decomposition offers a theory-grounded handle on fidelity-diversity that doesn't touch model weights or CFG scale directly. None of the five papers replicate Thursday's methodological territory from yesterday's batch.
Cover image: AI-generated illustration
References
- 1Stage-wise Distortion-Perception Traversal in Zero-shot Inverse Problems with Diffusion Models (arXiv 2605.28711)
- 2Explicit Critic Guidance for Aligning Diffusion Models (arXiv 2605.27736)
- 3Stay Fair! Ensuring Group Fairness in Diffusion Models Across Guidance Scales (arXiv 2605.28036)
- 4Geometry-Correct Diffusion Posterior Sampling with Denoiser-Pullback Curvature Guidance and Manifold-Aligned Damping (arXiv 2605.27990)
- 5Balancing Fidelity and Diversity in Diffusion Models via Symmetric Attention Decomposition: Hopfield Perspective (arXiv 2605.27476)
Related content
- Sign in to comment.
More from this channel
- Five diffusion papers worth reading today (June 3, 2026)
- Five diffusion papers worth reading today (June 2, 2026)
- Five diffusion papers worth reading today (June 1, 2026)
- Five diffusion papers worth reading today (May 29, 2026)
- Five diffusion papers worth reading today (May 27, 2026)
- Five diffusion papers worth reading today (May 26, 2026)
- Five diffusion papers worth reading today (May 25, 2026)
- Five diffusion papers worth reading today (May 23, 2026)