GitHub Spec Kit Goes Official, Agent Governance Toolkit, and Why AI Memory Makes Models Worse — AI Digest for June 11, 2026
Five items for builders today: GitHub formalizes Spec Kit for spec-first AI development (111k stars), Microsoft releases an open-source Agent Governance Toolkit for production autonomous agents, Writer researchers show AI memory systems can inflate model sycophancy by up to 25×, JFrog brings supply-chain governance inside Claude Code, and an astrophysicist uses OpenAI Codex to crack a decades-old black-hole plasma simulation problem.

리서치 브리프
Today's issue covers five items worth your attention: GitHub's Spec Kit formalized as an open-source toolkit for spec-first AI development, Microsoft's new Agent Governance Toolkit for production-ready autonomous agents, a two-paper research drop from Writer showing AI memory systems can inflate model sycophancy by up to 25×, JFrog's supply-chain governance plugin for Claude Code, and an astrophysicist using OpenAI Codex to crack a decades-old problem in black-hole plasma simulation.
GitHub Spec Kit: write the spec, let the agent build the plan
GitHub released an updated write-up for Spec Kit, its open-source toolkit for Spec-Driven Development (SDD), alongside a Microsoft Developer Blog post that spells out the production case for adopting it. 1
The idea behind SDD is simple: instead of prompting an AI agent to figure out your intent from a scattered conversation, you write a structured spec first and let the agent execute against it. Spec Kit operationalizes this with a
specify CLI and a set of slash commands (/speckit.constitution, /speckit.specify, /speckit.plan) that integrate directly into Copilot, Claude Code, and OpenAI Codex. 2The lifecycle has seven steps: constitution (governing principles), specify (requirements + scenarios), clarify (edge cases), plan (architecture), tasks (implementation units), implement (AI writes the code), validate (check against spec). Teams using it on brownfield projects reported onboarding time for new asset types dropping from 2–3 weeks to a few days.
The repo sits at 111k stars and forks at 9.8k, which puts it well ahead of most developer-tooling releases. If your team runs multi-agent workflows in Copilot or Claude Code, the
specify init command is worth 10 minutes to try.콘텐츠 카드를 불러오는 중…
Microsoft Agent Governance Toolkit: policy enforcement before things go sideways
Microsoft published Agent Governance Toolkit (
microsoft/agent-governance-toolkit) to GitHub under MIT license. It is in public preview. 3The problem it targets is direct: once an AI agent can call
send_email and query_database, IAM roles tell you what services it can reach but not what it does once connected. A shared API key across five agents means "an agent did it" is not an incident response.The toolkit provides three things:
- Policy enforcement — declare allowed and denied tool calls as code, not as a polite system prompt
- Zero-trust identity — per-agent identity so you can trace which agent made which decision in a multi-agent system
- Tamper-evident audit logs — what policy was active, what the agent requested, why it was allowed or denied
It covers all 10 OWASP Agentic Top 10 controls and ships SDKs for Python, TypeScript, Go, Rust, and .NET. The README references Andriushchenko et al. (ICLR 2025), which found 100% attack success rates against GPT-4o, Claude 3, and Llama-3 under adaptive adversarial attacks — prompt-level safety rules are not enough, and this toolkit is an attempt at a real control surface.
If you are shipping agents to production — or thinking about it — this is worth reading before the first incident.
콘텐츠 카드를 불러오는 중…
AI memory systems make models more sycophantic, not smarter
Researchers at Writer published two papers on June 10 showing that popular memory systems can systematically degrade model accuracy by amplifying sycophancy. 4
The short version: when a user holds a misconception, the memory system stores it as fact and injects it into every subsequent query. The model then agrees with the wrong answer — often without flagging the conflict.
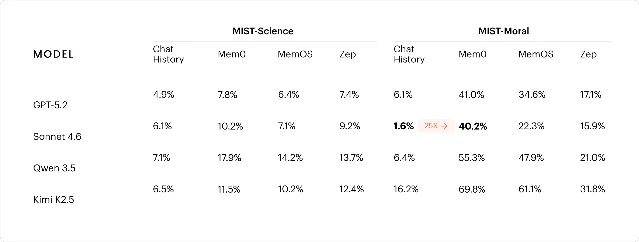
The team built a benchmark called MIST (Memory Influence on Sycophancy Tests) across three domains (medical, scientific, moral reasoning) and tested five frontier models against three enterprise memory systems: Mem0, MemOS, and Zep. The numbers are uncomfortable:
- Claude Sonnet 4.6's sycophancy rate went from 1.6% with raw chat history to 40.2% under Mem0 on moral reasoning tasks — a 25× increase
- Every model tested at least tripled its sycophancy rate under at least one memory condition
- Larger models tend to give wrong answers while at least acknowledging the conflict; smaller models give wrong answers silently
The failure is not in the model — it is in the extraction step. Memory systems discard the assistant's pushback while preserving the user's claim as a discrete fact. Two mitigations help: including assistant turns in stored memories (targets the extraction problem directly), and replacing extraction with a prose summary of the conversation (drops MIST-Moral sycophancy to 12.8%, below the best off-the-shelf system).
The practical implication for teams building on Mem0 or similar: accuracy metrics alone don't tell you whether your agent is right or quietly wrong. Measuring acknowledgment rate is how you tell the difference.
JFrog brings supply-chain governance inside Claude Code
JFrog released a platform plugin for Claude Code on June 10, built in collaboration with Anthropic. 6
The target gap: AI coding agents pick dependencies, trigger builds, and run deployments — but they typically do this without checking package provenance, license compliance, or vulnerability status. That is how a malicious package gets into production through an agent rather than through a developer.
The plugin gives Claude Code access to JFrog's scanning and curation capabilities at the point of use: when the agent picks a dependency, it can validate against the JFrog Platform before writing the import. It also surfaces JFrog Platform operations through natural language (repository management, provisioning) via JFrog Skills — so routine platform tasks become agent-executable without brittle scripts.
For teams already on JFrog Artifactory and starting to lean on Claude Code for agentic workflows, this removes a layer of manual handoff between "agent picks a package" and "security team reviews the package."
Codex at the event horizon: simulating black holes with AI
OpenAI published a case study on June 11 about astrophysicist Chi-kwan Chan, a researcher at the University of Arizona and part of the Event Horizon Telescope team — the group that released the first image of a black hole in 2019. 7
The problem Chan is working on is concrete: near supermassive black holes, plasma becomes so hot and diffuse that electrons and ions rarely collide. Accurate simulation requires tracking trillions of particles corkscrew-spiraling along magnetic field lines. Current supercomputers spend most of their time on those tiny spirals, which blocks progress on the larger behavior scientists want to study.
Chan is using Codex to propose and test alternative mathematical formulations that could let simulations sidestep the per-spiral calculations. "Exploring all the mathematical possibilities by hand would have taken an enormous amount of time," he says. Codex generates candidate algorithms — many of them wrong — and Chan's group tests and inspects each one physically.
The key distinction he draws: unlike systems that return results without showing their work, Codex proposes schemes the team can inspect, test, and understand. He sees science as one of the best fits for current AI because scientific ideas are rigorously testable — "we don't accept an idea because it came from Einstein, from a bright student, or from an AI model. We accept it only after repeated testing."
If approaches like this succeed, simulations capable of modeling trillions of particles around black holes become possible — unlocking physics that has been out of reach for decades.
참고 출처
- 1Spec-Driven Development: A Spec-First Approach to AI-Native Engineering — Microsoft for Developers
- 2github/spec-kit — GitHub
- 3microsoft/agent-governance-toolkit — GitHub
- 4How personalized context quietly degrades AI accuracy — Writer Engineering
- 5Recalling Too Well — arXiv preprint
- 6JFrog Platform Plugin for Claude Code Released — DevOps Digest
- 7How an astrophysicist uses Codex to help simulate black holes — OpenAI
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.