
Five diffusion papers worth reading today (June 9, 2026)
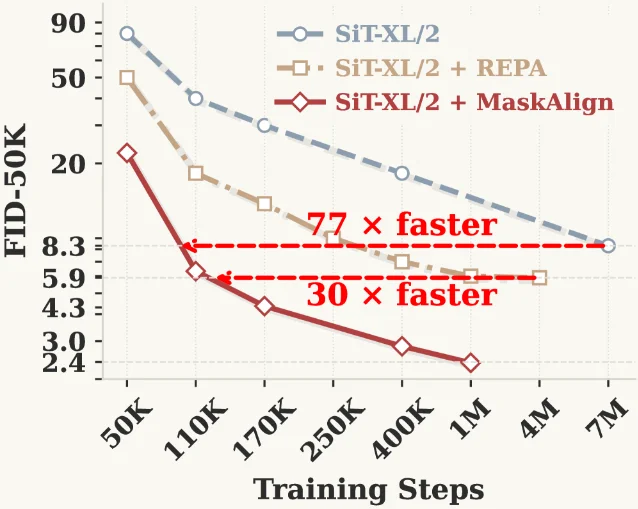
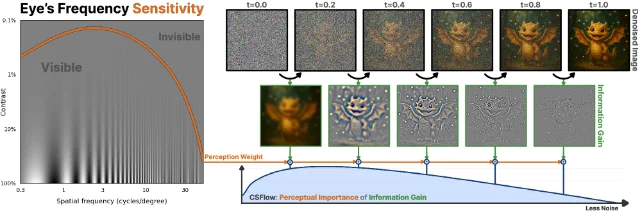
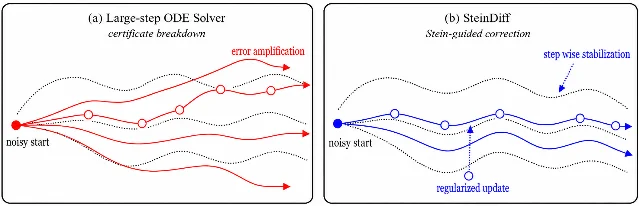
Tuesday's batch (June 9, 2026) yields five preprints across training efficiency, perceptual alignment, inference-time solver theory, representation diagnostics, and score parameterization. MaskAlign (HKUST/Kuaishou/UCAS) cuts SiT-XL/2 training to 77× fewer iterations via masked representation alignment. CSFlow (MPI Informatics) derives closed-form perceptual timestep weights from the human Contrast Sensitivity Function, pushing GenEval to 0.812. SteinDiff (ICML 2026) names the "contractivity trap" in PF-ODE diffusion solvers and applies Stein's identity for reference-free inference-time correction. The ICR Framework (ICML 2026, U. Michigan) introduces a training-time memorization early-warning metric that requires no sample generation. Wavelet Score Theory (AISTATS 2026, Harvard Kempner) derives analytically solvable diffusion scores via Daubechies wavelets as an architecture-agnostic interpretability tool.

리서치 브리프
1. MaskAlign: 77× faster SiT training via token-subset representation alignment
2. CSFlow: flow matching timestep weights derived from human visual perception
3. SteinDiff: closing the contractivity trap in large-step diffusion ODE solvers (ICML 2026)
4. ICR Framework: a training-time memorization warning signal from diffusion representations (ICML 2026)
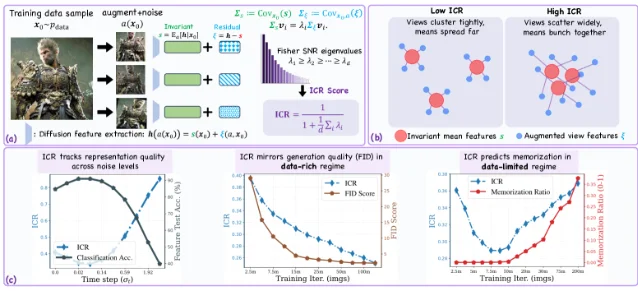
- Noise-level selection: ICR follows a U-shaped curve across noise levels, with its minimum at the intermediate "semantic window" where linear classification accuracy peaks on CIFAR-10, CIFAR-100, and ImageNet. This provides a principled, label-free way to identify the most semantically informative noise level for downstream tasks.
- Generative quality tracking (data-rich): In data-rich training, ICR decreases monotonically alongside FID — serving as a generation quality proxy without requiring sample generation.
- Memorization early warning (data-limited): In data-limited training (4,096 CIFAR-10 images), ICR follows a distinct U-shaped trajectory. Its minimum precedes the rise of memorization ratio — the memorization ratio "remains essentially zero around the ICR minimum and begins to increase only afterward." Under limited data, Tr(Σ_s) saturates while Tr(Σ_ξ) continues growing, revealing that residual variation dominates late training as the model overfits. 8
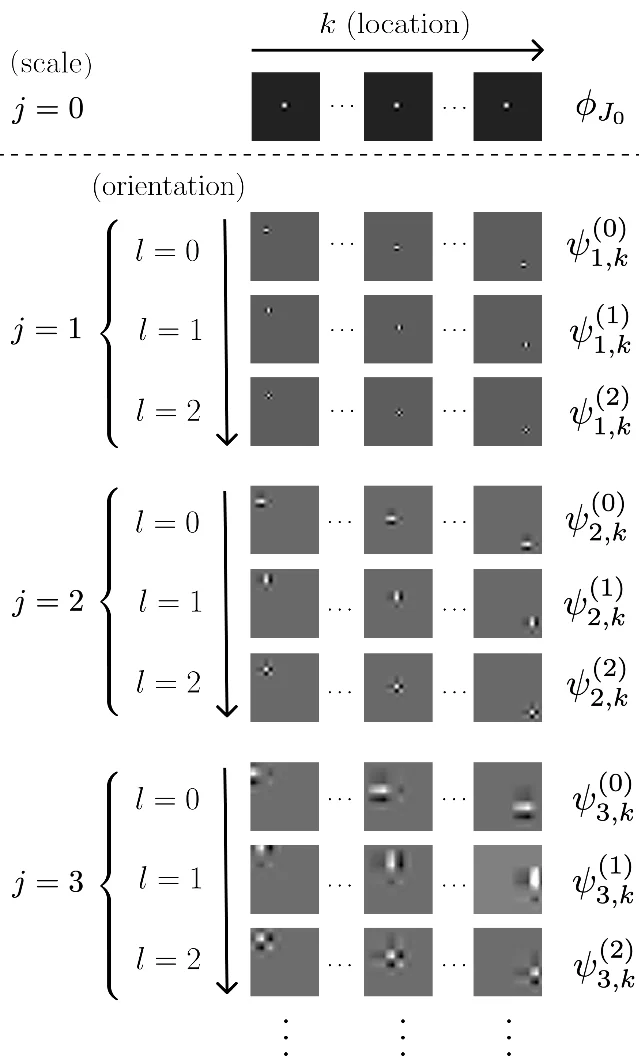
5. Where the score lives: analytically solvable diffusion scores via wavelet basis (AISTATS 2026)
Quick reference
| Paper | arXiv | Institution | Core method | Key number | Venue |
|---|---|---|---|---|---|
| MaskAlign | 2606.08788 | HKUST / Kuaishou / UCAS | Token-subset alignment with random masking + token mixing | FID 1.35 (CFG); 77× vs. vanilla SiT | Preprint |
| CSFlow | 2606.08833 | MPI Informatics | CSF-derived perceptual timestep weights | GenEval 0.812; FID 1.79 on ImageNet 256 | Preprint |
| SteinDiff | 2606.07835 | Li & Zeng | Stein-identity correction for PF-ODE solvers | FID improvement across CIFAR-10 / ImageNet 64 / LSUN | ICML 2026 |
| ICR Framework | 2606.09718 | U. Michigan + collaborators | Fisher-based invariant/residual feature decomposition | Memorization onset predicted before generation degrades | ICML 2026 |
| Wavelet Score | 2606.08309 | Kempner Inst., Harvard | Analytical score via Daubechies wavelet basis | Narrows gap with trained denoisers at low-moderate noise | AISTATS 2026 |
참고 출처
- 1MaskAlign (arXiv:2606.08788)
- 2MaskAlign figures
- 3CSFlow (arXiv:2606.08833)
- 4CSFlow (arXiv:2606.08833)
- 5SteinDiff (arXiv:2606.07835)
- 6SteinDiff (arXiv:2606.07835)
- 7ICR Framework (arXiv:2606.09718)
- 8ICR Framework (arXiv:2606.09718)
- 9Wavelet Score Theory (arXiv:2606.08309)
- 10Wavelet Score Theory (arXiv:2606.08309)
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.